Download
1 / 1
20 likes | 211 Views
A Scalable Approach to Size-Independent Network Similarity. Research Dublin. Dept. of Computer Science Rutgers. dblp. querylog. egonet. Networks. ‘Signature’ Vectors (aggr. features). Oregon AS. 2. Michele Berlingerio 1 Danai Koutra 2 Tina Eliassi-Rad 3 Christos Faloutsos 2

E N D
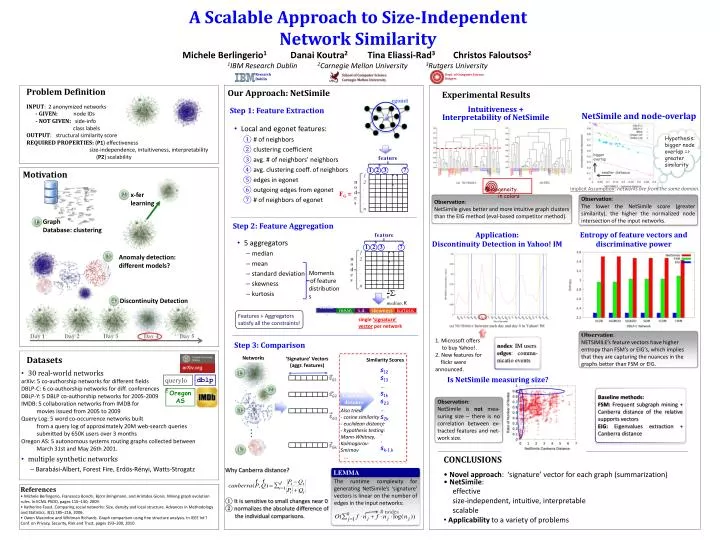
A Scalable Approach to Size-Independent Network Similarity Research Dublin Dept. of Computer Science Rutgers dblp querylog egonet Networks ‘Signature’ Vectors (aggr. features) Oregon AS ... ... ... ... 2 Michele Berlingerio1 Danai Koutra2 Tina Eliassi-Rad3 Christos Faloutsos2 1IBM Research Dublin 2Carnegie Mellon University 3Rutgers University x-fer learning LEMMA The runtime complexity for generating NetSimile’s ‘signature’ vectors is linear on the number of edges in the input networks: Why Canberra distance? It is sensitive to small changes near 0 normalizes the absolute difference of the individual comparisons. features features k 3 1 2 3 7 2 3 1 1 7 . . . . . . • Problem Definition • INPUT: 2 anonymized networks • - GIVEN: node IDs • - NOT GIVEN: side-info • class labels • OUTPUT: structural similarity score • REQUIRED PROPERTIES: (P1) effectiveness • size-independence, intuitiveness, interpretability • (P2) scalability Our Approach: NetSimile 1 2 . . . n 1 2 . . . n Experimental Results . . . . . . n o d e s n o d e s # nodes Step 1: Feature Extraction Intuitiveness + Interpretability of NetSimile NetSimile and node-overlap • Local and egonet features: • # of neighbors • clustering coefficient • avg. # of neighbors’ neighbors • avg. clustering coeff. of neighbors • edges in egonet • outgoing edges from egonet • # of neighbors of egonet Hypothesis: bigger node overlap => greater similarity bigger overlap Motivation smaller distance homogeneity in colors Implicit Assumption: networks are from the same domain. FG = 2 Observation: NetSimile gives better and more intuitive graph clusters than the EIG method (eval-based competitor method). Observation: The lower the NetSimile score (greater similarity), the higher the normalized node intersection of the input networks. Step 2: Feature Aggregation Graph Database: clustering 1 Application: Discontinuity Detection in Yahoo! IM Entropy of feature vectors and discriminative power • 5 aggregators • median • mean • standard deviation • skewness • kurtosis 3 Anomaly detection: different models? Moments of feature distributions Discontinuity Detection 4 … median kurtosis skewness mean s.d. Features + Aggregators satisfy all the constraints! single ‘signature’ vector per network Day 1 Day 2 Day 3 Day 4 Day 5 Observation: NETSIMILE’s feature vectors have higher entropy than FSM’s or EIG’s, which implies that they are capturing the nuances in the graphs better than FSM or EIG. Step 3: Comparison 1. Microsoft offers to buy Yahoo!. 2. New features for flickr were announced. nodes: IM users edges: commu- nicatio events Datasets Similarity Scores s12 s13 … s1k s23 … s2k . . . sk-1,k • 30 real-world networks • arXiv: 5 co-authorship networks for different fields • DBLP-C: 6 co-authorship networks for diff. conferences • DBLP-Y: 5 DBLP co-authorship networks for 2005-2009 • IMDB: 5 collaboration networks from IMDB for • movies issued from 2005 to 2009 • Query Log: 5 word co-occurrence networks built • from a query log of approximately 20M web-search queries • submitted by 650K users over 3 months • Oregon AS: 5 autonomous systems routing graphs collected between • March 31st and May 26th 2001. • multiple synthetic networks • Barabási-Albert, Forest Fire, Erdös-Rényi, Watts-Strogatz Is NetSimile measuring size? sG1 Canberra distance Baseline methods: FSM: Frequent subgraph mining + Canberra distance of the relative supports vectors EIG: Eigenvalues extraction + Canberra distance sG2 Observation: NetSimile is not mea-suring size – there is no correlation between ex-tracted features and net-work size. • Also tried: • cosine similarity • euclidean distance • hypothesis testing: Mann-Whitney, Kolmogorov-Smirnov • … sG3 sGk • CONCLUSIONS • Novel approach: ‘signature’ vector for each graph (summarization) • NetSimile: • effective • size-independent, intuitive, interpretable • scalable • Applicability to a variety of problems • References • Michele Berlingerio, Francesco Bonchi, Björn Bringmann, and Aristides Gionis. Mining graph evolution rules. In ECML PKDD, pages 115–130, 2009. • Katherine Faust. Comparing social networks: Size, density and local structure. Advances in Methodology and Statistics, 3(2):185–216, 2006. • Owen Macindoe and Whitman Richards. Graph comparison using fine structure analysis. In IEEE Int’l Conf. on Privacy, Security, Risk and Trust, pages 193–200, 2010.