Download

1 / 44
440 likes | 570 Views
Digital Curation Centre. a centre of support for data curation and preservation. UK Digital Curation Centre One Year On. Liz Lyon Associate Director, Outreach Chris Rusbridge, DCC Director. Overview. Why is digital curation important? What are the challenges that the DCC faces?

E N D
Digital Curation Centre a centre of support for data curation and preservation UK Digital Curation Centre One Year On Liz Lyon Associate Director, Outreach Chris Rusbridge, DCC Director
Overview • Why is digital curation important? • What are the challenges that the DCC faces? • About the people and our collaborative approach • Addressing the issues • How can you contribute to the DCC?
Curation? “maintaining and adding value to a trusted body of digital information for current and future use”
Digital curation continuum For later use? In use now (and the future)? Static Dynamic Data preservation Data curation
Assuring permanent access to the records of science & the humanities? • Long term access to primary data • Increasing data volumes from eScience and Grid-enabled / cyberinfrastructure applications • Changing research paradigm: data-driven science, “big science” • Observational data, simulations, large-scale experimentation • Multi-media resources, statistical data, surveys, geo-spatial data……
Facilitate “post-processing” and knowledge extraction • Enable the acquisition of newly-derived information and knowledge • Run complex algorithms over primary datasets • Mining (data, text, structures) • Modelling (economic, climate, mathematical, biological) • Analysis (statistical, lexical, pattern matching, gene) • Presentation (visualisation, rendering)
Provide additional functionality beyond digital preservation processes • Annotations • Gene and protein sequences • e-Lab books (Smart Tea Project in chemistry)
Presentation services: subject, media-specific, data, commercial portals Searching , harvesting, embedding Resource discovery, linking, embedding Data creation / capture / gathering: laboratory experiments, Grids, fieldwork, surveys, media The scholarly knowledge cycle : linking research data to publications eBank UK Project http://www.ukoln.ac.uk/projects/ebank-uk/ Data analysis, transformation, mining, modelling Aggregator services: national, commercial Harvestingmetadata Research & e-Science workflows Repositories : institutional, e-prints, subject, data, learning objects Deposit / self-archiving Validation Validation Publication Linking Emerging policy on open access to data Data curation: databases & databanks Peer-reviewed publications: journals, conference proceedings
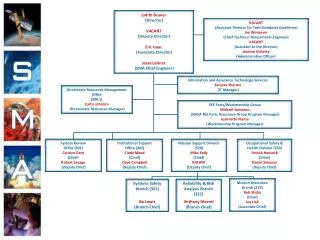
DCC people (some of them…) Management & Co-ordination Director Chris Rusbridge (University of Edinburgh) Community Support & Outreach Led by Dr Liz Lyon (UKOLN, University of Bath) Service Definition & Delivery Led by Professor Seamus Ross (HATII [ERPANET], University of Glasgow) Development Led by Dr David Giaretta (Astronomical Software & Services, CCLRC) Research Led by Professor Peter Buneman (Informatics, University of Edinburgh)
The challenges we face • Standards • Interoperability issues: technical & hopefully soluble • Scale • Volume and diversity of datasets • Culture • Bringing communities together • Library/information science/archives “document tradition” • Domain research (chemists, astronomers, biologists) • Computer science (databases) • Commercial suppliers (storage technology)
More challenges…… • Process • Highly-distributed organisation: use collaborative tools • Skills • Distributed amongst the 4 partners & beyond • Engagement • Lots of existing work and many significant players • Impact • Visible & measurable, in the short & long-term • Meeting expectations (which are high…..) • Of the community and our funders
User requirements analysis • Commissioned study • Leona Carpenter • Reporting now • Desk-based research • Focus groups • Interviews • Results will inform research, development service definition / delivery and outreach • Recommendations and priority tasks
Some sound bytes… R&D issues: Annotation services, Ontology development, Automating metadata creation, Tools and toolkits, Data Format Description Language, Identifiers, Registries, Economic and cost-benefits studies Advisory services:“Ask-a-Curator”,FAQs, reports, briefings, awareness-raising materials, best practice guidance, Storage media, “Like Erpanet”, advise Government, Research Councils, funding bodies Professional development: Short courses, conferences, seminars, workshops, secondments to DCC and to working repository services Outreach: Leadership for the future, case studies, sharing solutions, collaboration with other partners, international peers, industry links Taxonomy of “Users”
Outline Taxonomy of digital curation users by role • 4. Policy makers • funding bodies • other leaders 2. Data Curators 1. Data Creators 3. Data Re-users
Outline Taxonomy of digital curation users by role Data Preservers • 4. Policy makers • funding bodies • other leaders 2. Data Curators Data publishers 1. Data Creators 3. Data Re-users
Outline Taxonomy by significant function of organisational entity • Research 4. Funders 3. Learning & teaching 5. Policy / strategy makers 2. Service provision “Designated communities”
Outline Taxonomy by significant function of organisational entity • Research 4. Funders 3. Learning & teaching 5. Policy / strategy makers 2. Service provision Commercial “Designated communities”
Service definition & delivery • Advisory services • Responses to queries—from legal to technical guidance HELPDESK@dcc.ac.uk • Site visits (National Institute of Environmental eScience) • Information Services • Briefing Documents - Freedom of Information by Mags McGinley • DIGITAL CURATION MANUAL • 20 chapters written by community experts e.g. Metadata written by Michael Day, UKOLN • Peer-reviewed • Checklist for Compliance with best practices and standards • Technology Watch
Services: workshops • 2005 Programme • Preservation of medical databases: 24-25 May at the Gulbenkian Institute, Lisbon in collaboration with ERPANET & the Wellcome Trust • Institutional repositories: 6 July at the University of Cambridge, UK in collaboration with DSpace • Cost models in collaboration with the Digital Preservation Coalition July at British Library • Persistent identifiers liaising with NISO, summer, UK location tbc
Development approach • OAIS (Open Archival Information System) linkage: focus on representation information • link to global work on format registries? • Concentrate on scientific data formats? • Repository • Representation Information • Standards and Tools • Aim for OAIS compliance • Persistent identifiers • Certification… RLG task force • Open development wiki and email list
OAIS Reference Model – Functional Model How relevant to curation?
Representation Information More detail How does this relate to format registries?
High Level View Example of use of Representation Information Labelling
Registry issues? • Trusted repository of Representation Information • Authenticity of information • Access control • Certificates/Digests : (are they trustable over the long term?) • Findability • Persistent IDs • What can we rely on? • Labels (to support automated processing) • Extensibility • Distributed
Registry development • Simple PHP prototype • Scoping study- unification • Formats, standards, tools • More robust prototype in development • Based on ebXML & JAXR • Potentially distributed, cooperative maintenance model
Development Roadmap • Registry: complete prototype, link to PRONOM, GDFR etc, handover to service • Representation information: describe CCLRC (science) data using EAST, etc • Certification work continues • Additional tools: metadata extraction • Testbeds, interactions with others
Research approaches • Publishing & integrating scientific databases • ‘Archiving’ past states of volatile databases • Database provenance and annotation • Organisational dynamics of trusted repositories • Automating metadata extraction • Cost-benefit analysis of data curation • Rights and responsibilities
The database picture Curated data: classified, cleaned, annotated, integrated, cross-linked Source data
Curated Databases are Central Much/most scientific data is now in databases • They often do not contain source experimental data. Sometimes just annotation/metadata • They borrow extensively from, and refer to, other databases • You are now judged by your data as well as your (paper) publications!! • These databases are built and maintained with a great deal of human or computational effort. • What makes a database? • it has internal structure or it changes. • Size alone doesn’t qualify
Archiving (preserving) volatile databases • How do you preserve something that changes every hour or minute? • Important for the scientific record – someone might have cited your data at time t. • Current practice • Create versions (how often?) • Log changes • Use diffs • Do nothing (common!)
Curated databases – some issues • Integratingand publishing data so that someone else can use it. • Annotating existing data and moving annotations to other databases • Provenance: where did this data come from? • Archiving: how do you preserve something that is constantly changing?
How do we cite data? • A URL or citation to an article is already unsatisfactory. • DCC client complaint: “I spend a lot of time searching [electronic documents] for the part that is relevant to the citation.” • The problem is much worse when you are citing something in a very large database. • How do you use a citation to locate data? • How do you ensure that the citation persists? • Connections with DB archiving and DOIs
Research approaches • Publishing & integrating scientific databases • ‘Archiving’ past states of volatile databases • Database provenance and annotation • Organisational dynamics of trusted repositories • Automating metadata extraction • Cost-benefit analysis of data curation • Rights and responsibilities • “Public domain, public interest, public funding” paper Waelde & McGinley
www.ijdc.net • Launch planned June/July • Peer-reviewed contributions • Peter Buneman Editor (research) • Production editor Philip Hunter
Sample issue Full papers Invited articles News & views Papers for submission are very welcome!
1st DCC International Conference • Location - Bath UK • 29-30 September 2005 • Keynote speakers • Cliff Lynch CNI • Graham Cameron European Bio-informatics Institute • DCC Research update • Social highlights
Associates Network • Goals • Develop understanding, share best practice, advance research, promote recognition, develop consensus • Membership • International groups, national bodies, industry partners, funders, research groups, HEIs, FEIs, individuals…… • Benefits • Early access to R&D outputs, advisory services, training, input to definition and design, community participation • Discussion Forum www.dcc.ac.ukPlease join us!
CMS-Bristol NASA NARA CNES ESA RLG BNSC BODC BADC NIEeS Cambridge Leicester Jodrell Bank DPC ESO RG RLG IVOA ESA SDSC Kyoto USC CDS ESO Council for Museums, Archives & Libraries Caltech JHU CSIRO RDN. OCLC International Collaborations Research Institutes RI EDG GridPP EGEE UNC So’ton MIMAS NLA CEH OAI NOF NCS ILRT HEIs & FE NEODC WT-CFG Leicester IC Maastricht Oxford AHDS Microsoft IBM Oracle BT STK Standards Bodies Durham Innogen Dutch NA Swiss NA Urbino Research Councils Data Archive Capri NTUA INRIA HUJ UPC Max- Planck LDC Salzburg NHS ACM Roslin INRIA MIMAS UNC JHU CSIRO IBM Almaden MRC HGU EBI OCLC TU Vienna IASSIST UPenn GSK CCLRC UKOLN DELOS DPC DLI (US) NeSC UofE UofG
Acknowledgements Slides from Peter Buneman, David Giaretta and others used with thanks.
How you can help us How does OAIS relate to curation? How do format registries relate to representation information? Who else is working across these areas? What outcomes would you like to see?