Download

1 / 29
310 likes | 446 Views
ARIES Recovery Algorithm. 11/03,08/05 ADBMS20051103 See Redbook . See Ramakrishnan & Gehrke, Database Management Systems. ARIES - OVERVIEW (1/2). A steal, no-force approach

E N D
ARIES Recovery Algorithm 11/03,08/05 ADBMS20051103 See Redbook. See Ramakrishnan & Gehrke, Database Management Systems
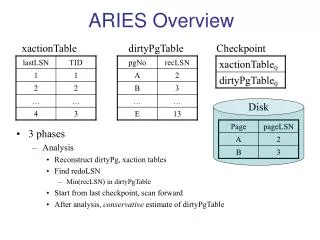
ARIES - OVERVIEW (1/2) • A steal, no-force approach • Steal: if a frame is dirty and chosen for replacement, the page it contains is written to disk even if the modifying transaction is still active. • No-force: Pages in the buffer pool that are modified by a transaction are not forced to disk when the transaction commits.
ARIES - OVERVIEW (2/2) After a crash, the recovery manager is invoked. Proceed in three phases. • Analysis: identify dirty pages in buffer pool (I.e., changes not yet written to disk), and identify active transactions at time of crash. • Redo: repeats all actions, starting from proper point in log, thus restoring the DB state to what is was at time of crash. • Undo: undo actions of transactions that didn’t commit --> DB reflects only committed transactions.
ARIES - the main principles • Write-ahead logging: any change to DB element is first recorded in log. The log record is written to stable storage before DB’s element change is written to disk. • Repeating History During Redo: On restart following crash, retrace all actions of DBMS before crash so system is back to the exact state it was at crash time. Then undo (abort) transactions still active at time of crash. • Logging Changes During Undo: Changes to DB while undoing a transaction are logged to ensure such an action is not repeated in the event of repeated restarts (from repeated failures).
Repeating History • Because of repeating all actions, ARIES can support concurrency control with record-level locks (not just page level locks).
Simple Example ANALYSIS: T1, T2 active (-> undo) T2 committed (-> write) D1, D2, D3 possibly dirty REDO: do updates 1, 2, 5, 6 UNDO: undo 6, 5, 2
Logging for ARIES Write a log record for: • Updating: (update-type record. Also set pageLSN for this page (in buffer) to this LSN. • Commit: force-write a commit log record (first, append log record then write log tail to disk. Then , update any DBMS data structures. Finally write commit log record.) • Abort: write log record. Then initiate UNDO for this transaction. • End: do DBMS data structures updating, then write end record. • Undoing an update: when transaction is rolled back or during crash recovery, its updates are undone. When an action described by update log record is undone, a compensation log record is written.
ARIES log records • LSN: log sequence number (unique, increasing) • prevLSN: maintain linked list of all log records • transID: ID of transaction generating log rec. • Type: commit, update, etc.
ARIES update log record • prevLSN • transID • type • pageID // page id of modified page • Length // length of change • Offset // offset to change • before-image // value before change • after-image // value after change • Redo-only update contains just after-image • Undo-only update contains just before-image
ARIES compensation log record (CLR) • This record is written just before the change recorded in update log record is undone. • CLR describes the action taken to undo the actions recorded in the corresponding update record. • CLR contains field undoNextLSN, the LSN of the next log record that is to be undone for the transaction that wrote the update record. • CLR describes an action that will never be undone. • CLR contains information needed to reapply or redo, but not to reverse it.
OTHER data structures (1/2) • Transaction Table: one entry for each active transaction: • transId • Status // in progress, committed, aborted // if C or A, will be eventually cleaned up. • lastLSN //LSN of most recent log record for this transID
OTHER data structures (2/2) • Dirty page table: One entry for each dirty page in the buffer pool: • recLSN // LSN of first log record that caused page to be dirty. This is the ealiest log record that may need to be redone during restart.
WAL • Before writing a page to disk, every update log record describing a change to this page must be forced to stable storage. So, force all log records upto and including the one with LSN equal to pageLSN to stable storage. THEN write page to disk. • SO “committed” means all log records, including the commit record, have been written to stable storage.
WAL - Commit • No-force: log tail is forced to storage • Force: all pages modified by transaction (not just the portion of the log) are forced to storage. ---> cost of forcing log-tail is much smaller than cost of force writing (all changed pages)
ARIES - Three steps for Checkpointing • Begin_checkpoint written to indicate where checkpoint starts. • End_checkpoint built, including current contents of transaction table and dirty page table, and appended to log. • After end_checkpoint is written to storage, a master record (has LSN of begin_checkpoint record) written to known place on disk. While constructing end_checkpoint, DBMS continues transactions and logging ==> the transaction table and dirty page table are accurate at time of begin_checkpoint.
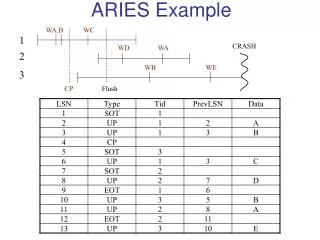
Example -- building the log and associated tables T1: update x[21..23], DEF Update y[41..43], WXY T2: Update x[20..22], KLM Update z[21..23], QRS Example offline -- interleaving T1 and T2.
ARIES Recovery Manager • Analysis: Scan down from most recent begin_checkpoint to last record. • Redo: Start at smallest recLSN in dirty page table at end of Analysis. Redo all changes to any page that might have been dirty at crash. • Undo: Starting at end of log, in reverse order, undo changes of all transactions at time of crash.
Start/End points in the log LOG AnalysisRedoUndo Oldest log record of active transactions Smallest recLSN in dirty page table Most recent checkpoint
Analysis’ tasks • Finds point in log to start Redo. • Finds set of pages in buffer pool that were dirty at crash. • Finds transactions active at crash time that need to be redone.
Analysis continued • Find most recent begin_checkpoint -> initialize Dirty Page Table (DPT) and Transaction table (TT) to copies of those in the next end_checkpoint. • Scan forward to end of log • If find T’s end, remove T from TT. • If T writes any other record, make sure T is in TT • Modify in TT so lastLSN field is set to LSN of this record • If log record is commit, status is set to C, otherwise set to U (indicating “to be UNDONE”) • If a redoable log record affecting page P is found, and P is not in DPT, insert entry to DPT with page id P and recLSN equal to LSN of this redoable log record
Analysis continued At end of Analysis, TT has correct list of active transactions at time of crash (marked with U) DPT has dirty pages at time of crash AND maybe some pages that were written to disk.
Redo • Reapply updates of ALL transactions, committed or otherwise. • If a transaction was aborted before the crash and its updates were undone, as indicated by CLRs, the actions described in CLRs are also reapplied. (AKA “repeating history” ) • At end of REDO, DB is in same state as it was at time of crash.
Redo Continued • Start at log with smallest recLSN of all pages in DPT constructed by the Analysis phase -- this is the oldest update that may not have been written to disk. • Scan forward to end of log. • For each redoable record (update or CLR), Redo checks to see whether action must be redone.
Redo - continued • If a (logged) action has to be redone: • Reapply the logged action • The pasgeLSN on the page is set to the LSN of the redone log record. No additional log record is written.
Redo - continued • Redo the action UNLESS: • The affected page is not in DPT (I.e., changes to this page have been written to disk) • The affected page is in DPT, but the recLSN for the entry is greater than the LSN of the log record being checked.(I.e., update being checked was written to disk) • The pageLSN (stored on the page) is greater than or equal to the LSN of the log record being checked. (have to retrieve the page for this one! )
UNDO • Scan backward to undo the actions of all transactions active at the time of the crash. • In OTHER WORDS! abort the active transactions.
UNDO continued • Start with TT built byAnalysis (recall, includes lastLSN, LSN of most recent log record for each). • Make a set of all lastLSN: ToUNDO • UNDO repeated choose the largest (most recent) LSN value and process it, until ToUNDO is empty.
UNDO continued • Process a log record: • IF CLR and undoNextLSN is not null, the undoNextLSN is added to ToUNDO • If CLR and undoNextLSN is null, write an end record for the transaction (because it is completely undone) and CLR is discarded. • If an update record, write a CLR and corresponding action is undone. TheprevLSN value in the update log record is added to ToUNDO set.
UNDO continued: aborting a transaction • Aborting a transaction is like the UNDO, but on a single transaction.