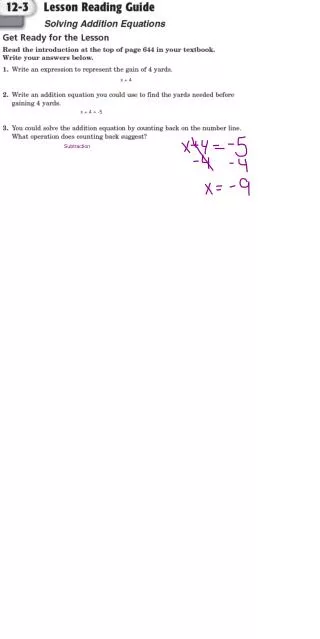Download
1 / 5
50 likes | 168 Views
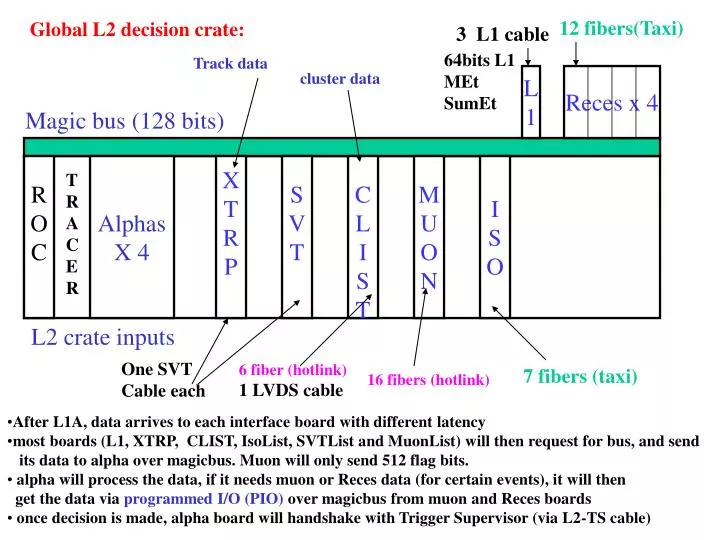
12 fibers(Taxi). Global L2 decision crate:. 3 L1 cable. 64bits L1 MEt SumEt. Track data. cluster data. L 1. Reces x 4. Magic bus (128 bits). R O C. Alphas X 4. X T R P. S V T. C L I S T. M U O N. I S O. T R A C E R. L2 crate inputs. One SVT Cable each.

E N D
12 fibers(Taxi) Global L2 decision crate: 3 L1 cable 64bits L1 MEt SumEt Track data cluster data L 1 Reces x 4 Magic bus (128 bits) R O C Alphas X 4 X T R P S V T C L I S T M U ON I S O T R A CER L2 crate inputs One SVT Cable each 6 fiber (hotlink) 1 LVDS cable 7 fibers (taxi) 16 fibers (hotlink) • After L1A, data arrives to each interface board with different latency • most boards (L1, XTRP, CLIST, IsoList, SVTList and MuonList) will then request for bus, and send • its data to alpha over magicbus. Muon will only send 512 flag bits. • alpha will process the data, if it needs muon or Reces data (for certain events), it will then • get the data via programmed I/O (PIO) over magicbus from muon and Reces boards • once decision is made, alpha board will handshake with Trigger Supervisor (via L2-TS cable)
1.5K bits/evt 96 bits/evt L 1 Reces x 4 1 MBW=Magic bus word = 128 bits = 16 bytes 200ns to transfer 1 MBW, raw bandwidth = 80 MB/s alphas X T R P S V T C L I S T I S O M U O N largest data size 21bits/tk 60bits /tk 45/cls 145/cls 512 flag bits/10.5Kb/evt Time takes from L1A to ready for Magicbus transfer ~1us ~15us ~2-3us ~3-4us ~6us 132ns ~6us Note: the actual system performance cannot be simply estimated with back-on-the-envelope calculations. Here we will make some assumptions, and then try to find a fair way to compare numbers…
Assumptions: • assume magicbus abitration has 200ns over head per board, • Magicbus bandwidth is 80MB/s, or 16Bytes/200ns; • Muon board sends 512 flag bits (fixed) every L1A • Alpha PIO is 4 us per MB: 4MB/s (measured with Reces) • assume CPU processing time is not the issue • no new L2 data path added • There is nothing one can do for the time it takes • for upstream data to transfer into the interface boards • ready for MB transaction. Will remove that offset in • the estimate. So this is a simplified picture. • Only look at data transfer time (bandwidth) in different • scenarios, assuming all the data from each L2 data path • are available “right away” to be transferred on magicbus • after L1A….
MBW=magicbus word(16bytes) Data transfer over magicbus per L1A: 96 bits (L1) + 21 bits x Ntrk (XTRP) + 60bits x Ntrk (SVT) + 45 bits x Nclu (CLIST) + 145bits x Niso x Fiso (ISO) + 512bits muon flag (MOUN) + 1MBW x Nmuon x Fmuon + 1MBWx Nelec x Felec Lum= 2 x 10 **31, L1 rate = 8KHz Fixed: 1 MBW Ntrk = 3 + 1.5 (3 layer trks), 1 MBW Ntrk =3, 2 MBW Nclu =2?, 1 MBW Niso =1? Fiso=0.1?, 0.2 MBW Fixed: 4 MBW Time for MB transfer 9.2MBW* 0.2us = 1.84 us + 6* 0.2us = 3 us Nmuon=2, Fmuon=0.01, 2MBW x 0.01x4=0.08us Nelec = 2, Felec =0.1, 2MBW x 0.1x4=0.8us Time for PIO .08 us + .8 us = 0.88 us average Total average time 0.88 + 3= 3.9 us << SVX/SVT time
~10 Interactions per BX Data transfer over magicbus per L1A: 96 bits L1 + 21 bits x Ntrk + 60bits x Ntrk + 45 bits x Nclu + 145bits x Niso x Fiso + 512bits muon flag + 16Bytes x Nmuon x Fmuon + 16Bytes x Nelec x Felec Lum= 4 x 10 **32, L1 rate = 40KHz Fixed: 1MBW Ntrk = (3 + 3)x 2?, 2 MBW Ntrk =3 x 2?, 3MBW Nclu =2? X 2?, 2 MBW Niso =1 ? Fiso=0.2?, 0.4 MBW Fixed: 4 MBW Time to transfer 12.4MBW * 0.2us = 2.5 us + 6 * 0.2us =3.7 us Nmuon=2?, Fmuon=0.02? 2MBW x 0.02 x 4 = 0.2us Nelec = 2?, Felec =0.2? 2MBW x 0.2x4 = 1.6us Time for PIO 0.2 us + 1.6 us = 1.8 us average Total average time 1.8 + 3.7 = 5.5 us << SVX/SVT time