Download

1 / 18
180 likes | 265 Views
Managing Hierarchies of Database Elements (18.6). -Neha Saxena Class Id: 214. Two problems that arise with locks when there is a tree structure to the data are: When the tree structure is a hierarchy of lockable elements

E N D
Managing Hierarchies of Database Elements (18.6) -Neha Saxena Class Id: 214
Two problems that arise with locks when there is a tree structure to the data are: • When the tree structure is a hierarchy of lockable elements • Determine how locks are granted for both large elements (relations) and smaller elements (blocks containing tuples or individual tuples) • When the data itself is organized as a tree (B-tree indexes) • This will be discussed in the next section
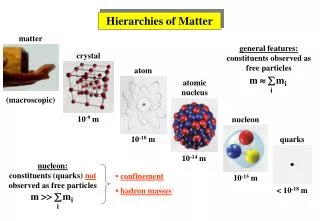
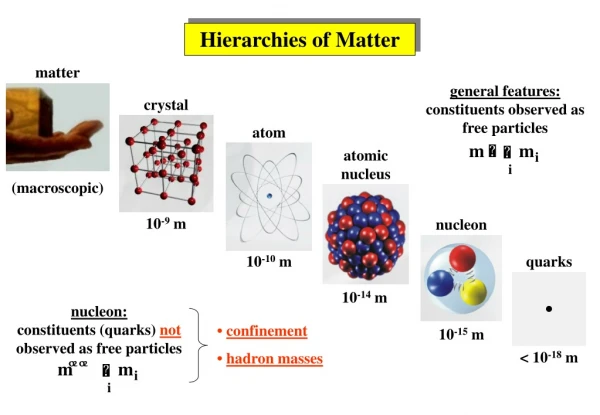
Locks with Multiple Granularity • A database element can be a relation, block or a tuple • Different systems use different database elements to determine the size of the lock • Thus some may require small database elements such as tuples or blocks and others may require large elements such as relations
Example of Multiple Granularity Locks • Consider a database for a bank • Choosing relations as database elements means we would have one lock for an entire relation • If we were dealing with a relation having account balances, this kind of lock would be very inflexible and thus provide very little concurrency • Why? Because balance transactions require exclusive locks and this would mean only one transaction occurs for one account at any time
But as each account is independent of others we could perform transactions on different accounts simultaneously • Thus it makes sense to have block element for the lock so that two accounts on different blocks can be updated simultaneously • Another example is that of a document • With similar arguments as above, we see that it is better to have large element (a complete document) as the lock in this case
Warning (Intention) Locks • These are required to manage locks at different granularities • In the bank example, if the a shared lock is obtained for the relation while there are exclusive locks on individual tuples, unserializable behavior occurs • The rules for managing locks on hierarchy of database elements constitute the warning protocol
Rules of Warning Protocol • These involve both ordinary (S and X) and warning (IS and IX) locks • The rules are: • Begin at the root of hierarchy • Request the S/X lock if we are at the desired element • If the desired element id further down the hierarchy, place a warning lock (IS if S and IX if X) • When the warning lock is granted, we proceed to the child node and repeat the above steps until desired node is reached
Compatibility Matrix for Shared, Exclusive and Intention Locks • The above matrix applies only to locks held by other transactions
Group Modes of Intention Locks • An element can request S and IX locks at the same time if they are in the same transaction (to read entire element and then modify sub elements) • This can be considered as another lock mode, SIX, having restrictions of both the locks i.e. No for all except IS • SIX serves as the group mode
Example • Consider a transaction T1 as follows • Select * from table where attribute1 = ‘abc’ • Here, IS lock is first acquired on the entire relation; then moving to individual tuples (attribute = ‘abc’), S lock in acquired on each of them • Consider another transaction T2 • Update table set attribute2 = ‘def’ where attribute1 = ‘ghi’ • Here, it requires an IX lock on relation and since T1’s IS lock is compatible, IX is granted
On reaching the desired tuple (ghi), as there is no lock, it gets X too • If T2 was updating the same tuple as T1, it would have to wait until T1 released its S lock
Phantoms and Handling Insertions Correctly • This arises when transactions create new sub elements of lockable elements • Since we can lock only existing elements the new elements fail to be locked • The problem created in this situation is explained in the following example
Example • Consider a transaction T3 • Select sum(length) from table where attribute1 = ‘abc’ • This calculates the total length of all tuples having attribute1 • Thus, T3 acquires IS for relation and S for targeted tuples
Now, if another transaction T4 inserts a new tuple having attribute1 = ‘abc’, the result of T3 becomes incorrect • This is not a concurrency problem since the serial order (T3, T4) is maintained • But if both T3 and T4 were to write an element X, it could lead to unserializable behavior
r3(t1);r3(t2);w4(t3);w4(X);w3(L);w3(X) • r3 and w3 are read and write operations by T3 and w4 are the write operations by T4 and L is the total length calculated by T3 (t1 + t2) • At the end, we have result of T3 as sum of lengths of t1 and t2 and X has value written by T3 • This is not right; if value of X is considered to be that written by T3 then for the schedule to be serializable, the sum of lengths of t1, t2 and t3 should be considered • Else if the sum is total length of t1 and t2 then for the schedule to be serializable, X should have value written by T4
This problem arises since the relation has a phantom tuple (the new inserted tuple), which should have been locked but wasn’t since it didn’t exist at the time locks were taken • The occurrence of phantoms can be avoided if all insertion and deletion transactions are treated as write operations on the whole relation