Download
1 / 1
10 likes | 176 Views
2 – Homology Modelling of the TEN Domain. 4 – Comparison of TEN Domain Structures. Conclusions. 6 – Mapping of Predicted and Verified Nucleic Acid Binding Sites on hTERT TEN Domain. 7 – Predicted vs. Verified DNA and RNA Binding Sites in hTERT and tTERT. 5 – Evaluation of Models.

E N D
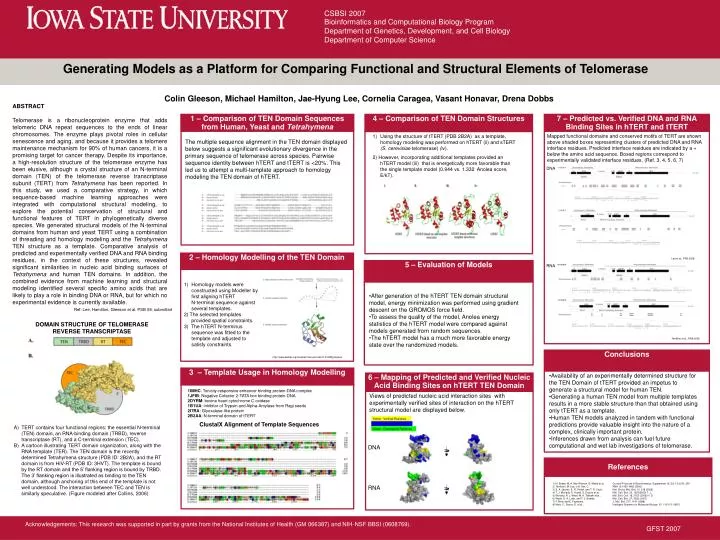
2 – Homology Modelling of the TEN Domain 4 – Comparison of TEN Domain Structures Conclusions 6 – Mapping of Predicted and Verified Nucleic Acid Binding Sites on hTERT TEN Domain 7 – Predicted vs. Verified DNA and RNA Binding Sites in hTERT and tTERT 5 – Evaluation of Models Views of predicted nucleic acid interaction sites with experimentally verified sites of interaction on the hTERT structural model are displayed below. DNA RNA References 3 – Template Usage in Homology Modelling 1 – Comparison of TEN Domain Sequences from Human, Yeast and Tetrahymena • TERT contains four functional regions: the essential N-terminal (TEN) domain, an RNA-binding domain (TRBD), reverse transcriptase (RT), and a C-terminal extension (TEC). • A cartoon illustrating TERT domain organization, along with the RNA template (TER). The TEN domain is the recently determined Tetrahymena structure (PDB ID: 2B2A), and the RT domain is from HIV-RT (PDB ID: 3HVT). The template is bound by the RT domain and the 5’ flanking region is bound by TRBD. The 3’ flanking region is illustrated as binding to the TEN domain, although anchoring of this end of the template is not well understood. The interaction between TEC and TEN is similarly speculative. (Figure modeled after Collins, 2006) CSBSI 2007 Bioinformatics and Computational Biology Program Department of Genetics, Development, and Cell Biology Department of Computer Science Generating Models as a Platform for Comparing Functional and Structural Elements of Telomerase Colin Gleeson, Michael Hamilton, Jae-Hyung Lee, Cornelia Caragea, Vasant Honavar, Drena Dobbs ABSTRACT Telomerase is a ribonucleoprotein enzyme that adds telomeric DNA repeat sequences to the ends of linear chromosomes. The enzyme plays pivotal roles in cellular senescence and aging, and because it provides a telomere maintenance mechanism for 90% of human cancers, it is a promising target for cancer therapy. Despite its importance, a high-resolution structure of the telomerase enzyme has been elusive, although a crystal structure of an N-terminal domain (TEN) of the telomerase reverse transcriptase subunit (TERT) from Tetrahymena has been reported. In this study, we used a comparative strategy, in which sequence-based machine learning approaches were integrated with computational structural modeling, to explore the potential conservation of structural and functional features of TERT in phylogenetically diverse species. We generated structural models of the N-terminal domains from human and yeast TERT using a combination of threading and homology modeling and the Tetrahymena TEN structure as a template. Comparative analysis of predicted and experimentally verified DNA and RNA binding residues, in the context of these structures, revealed significant similarities in nucleic acid binding surfaces of Tetrahymena and human TEN domains. In addition, the combined evidence from machine learning and structural modeling identified several specific amino acids that are likely to play a role in binding DNA or RNA, but for which no experimental evidence is currently available. Mapped functional domains and conserved motifs of TERT are shown above shaded boxes representing clusters of predicted DNA and RNA interface residues. Predicted interface residues are indicated by a + below the amino acid sequence. Boxed regions correspond to experimentally validated interface residues. (Ref. 3, 4, 5, 6, 7) • Using the structure of tTERT (PDB 2B2A) as a template, homology modeling was performed on hTERT (ii) and sTERT (S. cerevisiae telomerase) (iv). • 2) However, incorporating additional templates provided an hTERT model (iii) that is energetically more favorable than the single template model (0.944 vs. 1.332 Anolea score, E/kT). The multiple sequence alignment in the TEN domain displayed below suggests a significant evolutionary divergence in the primary sequence of telomerase across species. Pairwise sequence identity between hTERT and tTERT is <20%. This led us to attempt a multi-template approach to homology modeling the TEN domain of hTERT. DNA Lee et al., PSB 2008 RNA • Homology models were constructed using Modeller by first aligning hTERT • N-terminal sequence against several templates. • 2) The selected templates provided spatial constraints. • 3) The hTERT N-terminus sequence was fitted to the template and adjusted to satisfy constraints. • After generation of the hTERT TEN domain structural model, energy minimization was performed using gradient descent on the GROMOS force field. • To assess the quality of the model, Anolea energy statistics of the hTERT model were compared against models generated from random sequences. • The hTERT model has a much more favorable energy state over the randomized models. Ref: Lee, Hamilton, Gleeson et al. PSB 08, submitted DOMAIN STRUCTURE OF TELOMERASE REVERSE TRANSCRIPTASE Terriblini et al., RNA 2006 http://www.salilab.org/modeller/manual/node11.html#fig:feature • Availability of an experimentally determined structure for the TEN Domain of tTERT provided an impetus to generate a structural model for human TEN. • Generating a human TEN model from multiple templates results in a more stable structure than that obtained using only tTERT as a template. • Human TEN models analyzed in tandem with functional predictions provide valuable insight into the nature of a complex, clinically important protein. • Inferences drawn from analysis can fuel future computational and wet lab investigations of telomerase. 1IMHC: Tonicity-responsive enhancer binding protein-DNA complex 1JFIB: Negative Cofactor 2-TATA box binding protein-DNA 2DYRM: bovine heart cytochrome C oxidase 1B1UA: inhibitor of Trypsin and Alpha-Amylase from Ragi seeds 2I7RA: Glyoxalase-like protein 2B2AA: N-terminal domain of tTERT Yellow : Verified Residues ClustalX Alignment of Template Sequences Blue : Predicted Residues Green : Overlapping Residues 1) N. Eswar, M. A. Mari-Renom, B. Webb et al.. Current Protocols in Bioinformatics, Supplement 15, 5.6.1-5.6.30, 200. 2) Terribilini, M. Lee, J-H. Yan, C. RNA 12:1450-1462 (2006) 3) S. A. Jacobs, E. R. Podell, and T. R. Cech, Nat. Struct. Mol. Biol. 13, 218 (2006) 4) T. J. Moriarty, S. Huard, S. Dupuis et al., Mol. Cell. Biol. 22, 1253(2002) T. J. 5) Moriarty, R. J. Ward, M. A. Taboski et al., Mol. Biol. Cell. 16, 3152 (2005) H. D. 6) Wyatt, D. A. Lobb, and T. L. Beattie, Mol. Cell. Biol. 27, 3226 (2007) 7) F. Melo and E. Feytmans, J. Mol. Biol. 277, 1141 (1998) 8) Melo, F., Devos, D. et al., Intelligent Systems for Molecular Biology 97, 110-113 (1997) Acknowledgements: This research was supported in part by grants from the National Institutes of Health (GM 066387) and NIH-NSF BBSI (0608769). GFST 2007