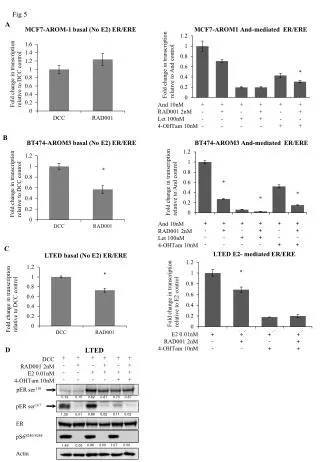
Download

1 / 15
150 likes | 321 Views
p.167 2. 采用基数排序方法时间复杂性最佳。 因为这里英文单词的长度相等,且英文单词是由 26 个字母组成的,满足进行基数排序的条件,另外,依题意, m<<n ,基数排序的时间复杂性由 O ( m ( n + 26 ))变成 O ( n ),因此时间复杂性最佳。. p.167 3. 采用堆排序最合适,依题意可知只需取得第 K 个最小元素之前的排序序列时,堆排序的时间复杂度是 O ( n+klog 2 n ),若 k≤n/log 2 n ,则可得到的时间复杂度是 O ( n )。

E N D
p.167 2 采用基数排序方法时间复杂性最佳。 因为这里英文单词的长度相等,且英文单词是由26个字母组成的,满足进行基数排序的条件,另外,依题意,m<<n,基数排序的时间复杂性由O(m(n + 26))变成O(n),因此时间复杂性最佳。
p.167 3 采用堆排序最合适,依题意可知只需取得第K个最小元素之前的排序序列时,堆排序的时间复杂度是O(n+klog2n),若k≤n/log2n,则可得到的时间复杂度是O(n)。 对于序列:{57,40,38,11,13,34,48,75,25,6,19,9,7}得到其第4个最小元素之前的部分序列{6,7,9,11},使用所选择的算法实现时,其执行比较次数如下: 建堆 20次 得到6 调整 5次 得到7 调整 4次 得到9 调整 5次 得到11 共计34次比较。
p.167 4 可以用队列实现,因为所划分出来的子表可以在任何次序上被继续排序。
p.168 5 依题意,取各种情况下的最好的比较次数即为最小比较次数。 (1)这种情况下,插入第i(1≤i≤n-1)个元素的比较次数为1,因此总的比较次数为:1+1+……+1=n-1 (2)这种情况下,插入第i(1≤i≤n-1)个元素的比较次数为i,因此总的比较次数为: 1+2+3+……+…n-1=n (n-1) /2 (3)这种情况下,比较次数最小的情况是所有记录关键字均按升序排列,这时,总的比较次数为:n-1 (4)在后半部分元素的关键字均大于前半部分元素的关键字时需要的比较次数最小,此时前半部分的比较次数=m-1,后半部分的比较次数=(n-m-1)(n-m)/2,因此,比较次数为:m-1+(n-m-1)(n-m)/2。
p.168 6 #define MAXITEM 100 typedef struct rec { KeyType key; elemType data; } sqlist; sqlist r[MAXITEM];
void dbubble (sqlist r[ ], int n) { int i=0, j, t, b=1; sqlist t; while (b) { b=0; for (j=n-i-1; j>i; j--) if (r[j].key<r[j-1].key) { b=1; t=r[j]; r[j]=r[j-1]; r[j-1]=t; } for (j=i+1; j<n-i-1; j++) if (r[j].key>r[j+1].key) { b=1; t=r[j]; r[j]=r[j+1]; r[j+1]=t; } i++; } }
p.168 7 #define MAXSIZE 200 typedef int elemtype; typedef struct element { elemtype key; int link; // 下一个结点下标, 初始值为0 } ELEMENT; ELEMENT s[MAXSIZE]; //结点存放s[1],s[2], …,s[n]
p.168 7 int listmerge (ELEMENT s[ ], int start1, int start2) { int k=0, i=start1, j=start2; while(i&&j) if(s[i].key<=s[j].key) { s[k].link=i; k=i; i=s[i].link; } else { s[k].link=j; k=j; j=s[j].link; } if(!i) s[k].link=j; if(!j) s[k].link=i; return s[0].link; }
p.168 7 int mergesort(ELEMENT s[ ], int left, int right) { if(left >= right) return left; int mid = (left + right) / 2; return listmerge(s, mergesort(s, left, mid), mergesort(s, mid+1, right)); }
for (i=0; i<n; i=i+2) if (a[i]>a[i+1]) { flag=1; t=a[i+1]; a[i+1]=a[i]; a[i]=t; } }while ( flag!=0); } p.168 8 (1)排序结束条件为没有交换元素为止。 (2)实现本题奇偶转换排序的函数如下: void oesort ( int a[ ], int n) { int i, flag; do{ flag=0; for (i=1; i<n; i=i+2) if (a[i]>a[i+1]) { flag=1; t=a[i+1]; a[i+1]=a[i]; a[i]=t; }
if (s==t) w=t; else { p=t->link; t->link=s->link; r->link=t; w->link=s; s->link=p; w=s; } t=w->link; } } p.168 9 typedef struct node { int key; struct node *link; }NODE; // 带表头结点 void selectsort (NODE *h) { NODE *p, *q, *s, *t, *r, *w; w=h; t=h->link; while(t!=NULL) { q=s=t; p=q->link; while (p!=NULL) { if (p->key<s->key) { s=p; r=q; } q=p; p=p->link; }
p.168 10 #define M 100 typedef struct rec { KeyType key; elemType data; } sqlist;
p.168 10 void partition (sqlist *r, int l, int h, int *pi) { int i=l, j=h; sqlist x; x=r[i]; do { while (x.key<=r[j].key&&j>i ) j--; if (j>i) { r[i]=r[j]; i++; } while (x.key>=r[j].key&&i<j) i++; if (i<j) { r[j]=r[i]; j--; } }while (i!=j); r[i]=x; *pi=i; }
p.168 10 void quicksort (sqlist * r, int t1, int t2) { int stack[M][2], i, top=0; stack[top][0]=t1; stack[top++][1]=t2; while (top>0) { t1=stack[--top][0]; t2=stack[top][1]; partition (r, t1, t2, &i); if (t1<i-1) { stack[top][0]=t1; stack[top++][1]=i-1; } if (i+1<r2) { stack[top][0]=i+1; stack[top++][1]=t2; } } }
p.168 11 void sort (int A[ ], int n) { int i, j, t, minval, minidx; for (i=0; i<n-1; i++) { minval=A[i]; minidx=i; for (j=i+1; j<n; j++) if (A[j]<minval) { minval=A[j]; minidx=j; } if (minidx!=i) { t=A[i+1]; A[i+1]=A[minidx]; A[minidx]=t; } } }