Download
1 / 67
700 likes | 1.31k Views
High Throughput DNA Sequencing. 30,000. Shotgun Sequencing. Isolate Chromosome. ShearDNA into Fragments. Clone into Seq. Vectors. Sequence. Principles of DNA Sequencing. Primer. DNA fragment. Amp. PBR322. Tet. Ori. Denature with heat to produce ssDNA. Klenow + ddN + dN

E N D
Shotgun Sequencing Isolate Chromosome ShearDNA into Fragments Clone into Seq. Vectors Sequence
Principles of DNA Sequencing Primer DNA fragment Amp PBR322 Tet Ori Denature with heat to produce ssDNA Klenow + ddN + dN + primers
dATP dCTP dGTP dTTP ddCTP dATP dCTP dGTP dTTP ddTTP dATP dCTP dGTP dTTP ddATP dATP dCTP dGTP dTTP ddCTP Principles of DNA Sequencing 3’ Template G C A T G C 5’ 5’ Primer GddC GCddA GCAddT ddG GCATGddC GCATddG
Principles of DNA Sequencing G T _ _ C A G C A T G C + +
Capillary Electrophoresis Separation by Electro-osmotic Flow
Multiplexed CE with Fluorescent detection ABI 3700 96x700 bases
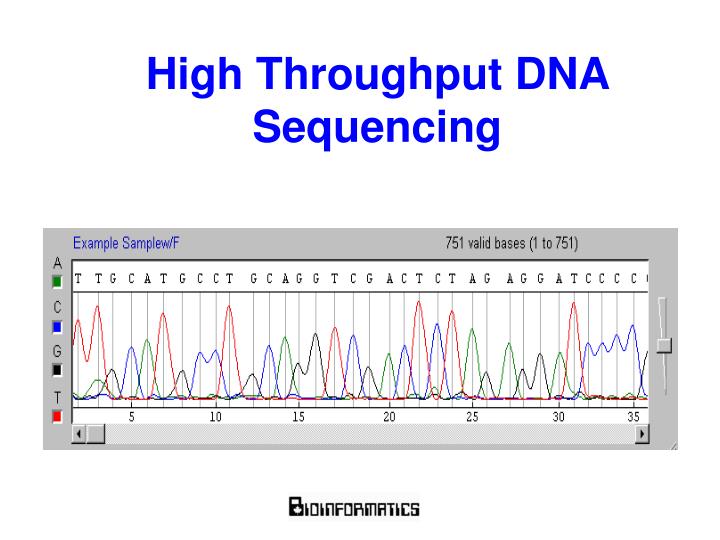
Shotgun Sequencing Assembled Sequence Sequence Chromatogram Send to Computer
Shotgun Sequencing • Very efficient process for small-scale (~10 kb) sequencing (preferred method) • First applied to whole genome sequencing in 1995 (H. influenzae) • Now standard for all prokaryotic genome sequencing projects • Successfully applied to D. melanogaster • Moderately successful for H. sapiens
The Finished Product GATTACAGATTACAGATTACAGATTACAGATTACAG ATTACAGATTACAGATTACAGATTACAGATTACAGA TTACAGATTACAGATTACAGATTACAGATTACAGAT TACAGATTAGAGATTACAGATTACAGATTACAGATT ACAGATTACAGATTACAGATTACAGATTACAGATTA CAGATTACAGATTACAGATTACAGATTACAGATTAC AGATTACAGATTACAGATTACAGATTACAGATTACA GATTACAGATTACAGATTACAGATTACAGATTACAG ATTACAGATTACAGATTACAGATTACAGATTACAGA TTACAGATTACAGATTACAGATTACAGATTACAGAT
Sequencing Successes T7 bacteriophage completed in 1983 39,937 bp, 59 coded proteins Escherichia coli completed in 1998 4,639,221 bp, 4293 ORFs Sacchoromyces cerevisae completed in 1996 12,069,252 bp, 5800 genes
Sequencing Successes Caenorhabditis elegans completed in 1998 95,078,296 bp, 19,099 genes Drosophila melanogaster completed in 2000 116,117,226 bp, 13,601 genes Homo sapiens 1st draft completed in 2001 3,160,079,000 bp, 31,780 genes
Scoring Matrices • An empirical model of evolution, biology and chemistry all wrapped up in a 20 X 20 table of integers • Structurally or chemically similar residues should ideally have high diagonal or off-diagonal numbers • Structurally or chemically dissimilar residues should ideally have low diagonal or off-diagonal numbers
Prokaryotic Gene Prediction Promoter Region -35 (TTGAC) Terminator (stem loop structure) -10 (TATAAT) Initiation codon (ATG) Stop codon (TAG,TAA, TGA) Shine Delgarno sequence RBS (G-rich)
Prokaryotic Gene Prediction • ORF finder • http://www.ncbi.nlm.nih.gov/gorf/gorf.html • GLIMMER • http://www.tigr.org/softlab/glimmer/glimmer.html • GeneMark • exon.biology.gatech.edu/GeneMark/ • www.ebi.ac.uk/genemark
Eukaryotic Gene Prediction branchpoint site 5’site 3’site exon 1 intron 1 exon 2 intron 2 CAG/NT AG/GT
Gene Predictors • GRAIL2 (http://compbio.ornl.gov/Grail-1.3/) • Neural Network Model CC=0.47 • HMMgene (http://www.cbs.dtu.dk/services/HMMgene/) • Hidden Markov Model CC=0.91 • GENSCAN (http://genes.mit.edu/GENSCAN.html) • Probabilistic Model CC=0.91 • GRPL (GeneTool) • Reference Point Logistics CC=0.94
Evaluation Statistics TP FP TN FN TP FN TN Actual Predicted Sensitivity Fraction of actual coding regions that are correctly predicted as coding Sn=TP/(TP + FN) Specificity Fraction of the prediction that is actually correct Sp=TP/(TP + FP) Correlation Combined measure of sensitivity and specificity CC=(TP*TN-FP*FN)/[(TP+FP)(TN+FN)(TP+FN)(TN+FP)]0.5
Gene Prediction Accuracy (%) Method
What Works Best? • Expect only a single exon… • BLASTN vs. dbEST • BLASTX vs. nr(protein) • Fully sequenced data • Run GENSCAN + HMMgene + GRPL • Combine predictions (CC > 0.95) • BLAST vs. nr(protein) • Combine BLAST result with prediction
Translation Frame3 A Y S D A H Frame2 C V * R C A Frame1 M R I A M R I ATGCGTATAGCGATGCGCATT TACGCATATCGCTACGCGTAA Frame-1 H T Y R H A N Frame-2 R I A I R M Frame-3 A Y L S A C
From Sequence to Function (and Structure) ACEDFHIKNMF SDQWWIPANMC ASDFDPQWERE LIQNMDKQERT QATRPQDS...
PROSITE Pattern Expressions C - [ACG] - T - Matches CAT, CCT and CGT only C - X -T - Matches CAT, CCT, CDT, CET, etc. C - {A} -T - Matches every CXT except CAT C - (1,3) - T - Matches CT, CCT, CCCT C - A(2) - [TP]- Matches CAAT, CAAP [LIV] - [VIC] - X(2) - G - [DENQ] - X - [LIVFM] (2) -G
PepTool Pattern Expressions C[ACG]T - Matches CAT, CCT and CGT only C*T - Matches CAT, CCT, CDT, CET, etc. C!AT - Matches every C * T except CAT C{1,3}T - Matches C*T, C * * T, C * * * T $CAA(TP]- Matches CAAT, CAAP at N terminus [LIV][VIC] * * G[DENQ] *[LIVFM][LIVFM]* G
Protein Sequence Motifs • Pattern-Based (PQL) Sequence Motifs • >*TCP&NLGT* • DOOLITTLE, R.F., OF URFS AND ORFS (1986) • GUANIDINE KINASE ACTIVE SITE • Profiles or Position Scoring Matrix (PSSM) • A C D E F G H I K L M N P Q R • 1 W G V L V 3 -2 3 4 0 4 -1 3 -1 4 4 1 1 1 -2 • 2 L L S P L 2 -2 -2 -1 3 0 -1 3 -1 6 5 -1 3 0 -1 • 3 V V V V V 2 2 -2 -2 2 2 -3 11 -2 8 6 -2 1 -2 -2 • 4 K E A T A 6 -2 5 6 -5 4 1 0 5 -2 0 3 3 3 1
C C C H2N H2N H2N COOH COOH COOH H H H Phosphorylation Sites pY pT pS PO4 CH3 PO4 PO4
Sequence Pattern Databases • PROSITE - http://www.expasy.ch/ • BLOCKS - http://www.blocks.fhcrc.org/ • DOMO - http://www.infobiogen.fr/~gracy/domo • PFAM - http://pfam.wustl.edu • PRINTS - http://www.biochem.ucl.ac.uk/bsm/dbrowser/PRINTS • SEQSITE - PepTool
R V Q N C A A P L I A A Y A T A G G A A F A K H A Sequence Profiles






















