Download
1 / 12
120 likes | 132 Views
This analysis utilizes pTrees and various algorithms to identify affinities and anomalies in dimension 2 datasets. The algorithms include dimension clustering, density-based clustering, and oblique clustering.

E N D
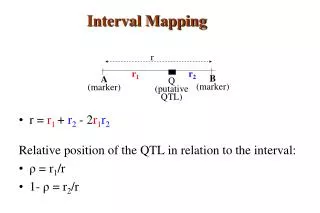
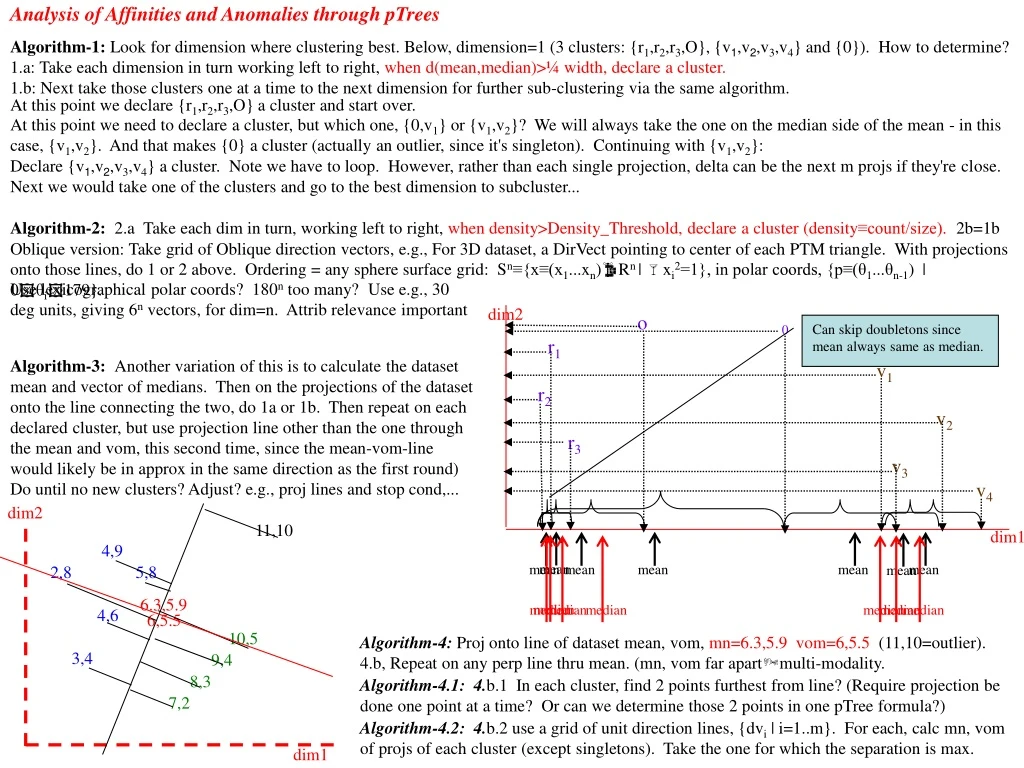
Analysis of Affinities and Anomalies through pTrees dim2 11,10 4,9 2,8 5,8 4,6 3,4 6.3,5.9 6,5.5 10,5 9,4 8,3 7,2 mean median mean median mean median median mean mean median mean mean median median dim1 Algorithm-1: Look for dimension where clustering best. Below, dimension=1 (3 clusters: {r1,r2,r3,O}, {v1,v2,v3,v4} and {0}). How to determine? 1.a: Take each dimension in turn working left to right, when d(mean,median)>¼ width, declare a cluster. 1.b: Nexttake those clusters one at a time to the next dimension for further sub-clustering via the same algorithm. At this point we declare {r1,r2,r3,O} a cluster and start over. At this point we need to declare a cluster, but which one, {0,v1} or {v1,v2}? We will always take the one on the median side of the mean - in this case, {v1,v2}. And that makes {0} a cluster (actually an outlier, since it's singleton). Continuing with {v1,v2}: Declare {v1,v2,v3,v4} a cluster. Note we have to loop. However, rather than each single projection, delta can be the next m projs if they're close. Next we would take one of the clusters and go to the best dimension to subcluster... Algorithm-2: 2.a Take each dim in turn, working left to right, when density>Density_Threshold, declare a cluster (density≡count/size). 2b=1b Oblique version: Take grid of Oblique direction vectors, e.g., For 3D dataset, a DirVect pointing to center of each PTM triangle. With projections onto those lines, do 1 or 2 above. Ordering = any sphere surface grid: Sn≡{x≡(x1...xn)Rn | xi2=1}, in polar coords, {p≡(θ1...θn-1) | 0θi179}. Use lexicographical polar coords? 180n too many? Use e.g., 30 deg units, giving 6n vectors, for dim=n. Attrib relevance important dim2 o 0 r1 v1 r2 v2 r3 v3 v4 Can skip doubletons since mean always same as median. Algorithm-3: Another variation of this is to calculate the dataset mean and vector of medians. Then on the projections of the dataset onto the line connecting the two, do 1a or 1b. Then repeat on each declared cluster, but use projection line other than the one through the mean and vom, this second time, since the mean-vom-line would likely be in approx in the same direction as the first round) Do until no new clusters? Adjust? e.g., proj lines and stop cond,... dim1 Algorithm-4: Proj onto line of dataset mean, vom, mn=6.3,5.9 vom=6,5.5 (11,10=outlier). 4.b, Repeat on any perp line thru mean. (mn, vom far apartmulti-modality. Algorithm-4.1: 4.b.1 In each cluster, find 2 points furthest from line? (Require projection be done one point at a time? Or can we determine those 2 points in one pTree formula?) Algorithm-4.2: 4.b.2 use a grid of unit direction lines, {dvi | i=1..m}. For each, calc mn, vom of projs of each cluster (except singletons). Take the one for which the separation is max.
mean=(8.18, 3.27, 3.73) vom=(7,4,3) 3 1. no clusters determined yet. 2.(9,2,4) determined as an outlier cluster. 435 524 504 545 323 3.Using red dim line, (7,5,2) is determined as an outlier cluster. maroon pts determined as cluster, purple pts too. 924 b43 e43 c63 752 f72 3.a However, continuing to use line connecting (new) mean and vom of the projections onto this plane, would the same be determined? 1 Other option? use (at some judicious point) a p-Kmeans type approach. This could be done using K=2 and a divisive top down approach (using a GA mutation at various times to get us off a non-convergent track)? Notes:Each round, reduce dim by one (low bound on the loop.) Each round, just need good line (in remaining hyperplane) to project cluster (so far). 1. pick line thru proj'd mean, vom (vom is dependent on basis used. better way?) 2. pick line thru longest diameter? ( or diam 1/2 previous diam?). 3. try a direction vector. Then hill climb it in direction increase in diam of proj'd set. 2 From: Mark Silverman [mailto:msilverman@treeminer.com] April 21, 2012 8:22 AM Subject: RE: oblique faust I’ve been doing some tests, so far not so accurate (I’m still validating the code – I “unhardcoded” it so I can deal with arbitrary datasets and it’s possible there’s a bug, so far I think it’s ok). Something rather unique about the test data I am using is that it has four attributes, but for all of the class decisions it is really one of the attributes driving the classification decision (e.g. for classes 2-10, attribute 2 is dominant decision, class 11 attribute 1 is dominant, etc). I have very wide variability in std deviation in the test data (some very tight, some wider). Thus, I think that placing “a” on the basis of relative deviation makes a lot of sense in my case (and probably in general). My assumption is that all I need to do is to modify as follows: Now: a[r][v] = (Mr + Mv) * d / 2 Changes to a[r][v] = (Mr + Mv) * d * std(r) / (std(r) + std(s)) Is this correct?
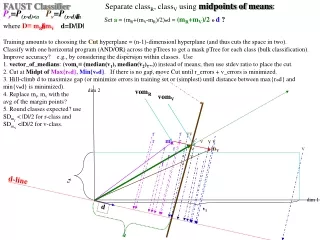
Separate class R using midpoint of means (mom) method: Calc a vomV vomR d-line d v2 v1 std of distances, vod, from origin along the d-line FAUST Oblique (our best classifier?) PR=P(X o dR ) < aR1 pass gives classR pTree D≡ mRmV d=D/|D| (mR+(mV-mR)/2)od = a = (mR+mV)/2od(works also if D=mVmR, Training≡placingcut-hyper-plane(s) (CHP) (= n-1 dim hyperplane cutting space in two). Classification is 1 horizontal program (AND/OR) across pTrees, giving a mask pTree for each entire predicted class (all unclassifieds at-a-time) Accuracy improvement? Consider the dispersion within classes when placing the CHP. E.g., use the 1. vectors_of_median, vom, to represent each class, not the meanmV, where vomV ≡(median{v1|vV}, 2. mom_std, vom_std methods: project each class on d-line; then calculate std (one horizontal formula per class using Md's method); then use the std ratio to place CHP (No longer at the midpoint between mr and mv median{v2|vV}, ...) dim 2 Note:training (finding a and d) is a one-time process. If we don’t have training pTrees, we can use horizontal data for a,d (one time) then apply the formula to test data (as pTrees) r r vv r mR r v v v r r v mV v r v v r v dim 1
The PTreeSet Genius for Big Data 1 A1,bw1 A1,bw1-1 ... A1,0 A2,bw2 ... Ak+1,c1 ..An,ccn 2 3 4 1 0 0 0 1 0 0 1 5 ... 0 1 1 0 0 1 1 2 7B 0 0 0 0 0 0 0 P 3 1 0 0 0 1 0 0 4 0 0 1 0 0 0 1 5 1 0 0 0 1 0 0 ... 0 0 1 0 0 0 0 N A1,bw1 A1,bw1-1 ... A1,0 A2,bw2 ... Ak+1,c1 ...An,ccn row number 1 0 1 0 1 1 0 1 1 1 1 0 0 0 1 2 gene chromosome 0 0 0 0 0 0 0 ... 1 0 0 0 1 0 1 roof (N/64) bpp 1 2 3 4 5 ... 3B inteval number pc bc lc cc pe age ht wt 1 0 0 0 1 0 0 0 1 1 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 1 1 0 0 0 1 0 0 0 0 1 0 0 0 0 AHG(P,bpp) Big Vertical Data: PTreeSet (Dr. G. Wettstein's) perfect for BVD! (pTrees both horiz and vert) PTreeSets incl methods for horiz querying and vertical DM, multihopQuery/DM, and XML. T(A1...An) is a PTreeSet data structure = bit matrix with (typically) each numeric attr converted to fixedpt(?), (negs?) bitsliced (pt_posschema) and category attr bitmapped; coded then bitmapped; num coded then bisliced (or as is, ie, char(25) NAME col stored outside PTreeSet? A1..Ak num w bitwidths=bw1..bwk; Ak+1..An categorical w counts=cck+1...ccn, PTreeSet is bitmatrix: Methods for this data structure can provide fast horizontal row access , e.g., an FPGA could (with zero delay) convert each bit-row back to original data row. Methods already exist to provide vertical (level-0 or raw pTree) access. Add any Level1 PTreeSet can be added: given any row partition (eg, equiwidth =64 row intervalization) and a row predicate (e.g., 50% 1-bits ). Add "level-1 only" DM meth, e.g., FPGA converts unclassified rowsets to equiwidth=64, 50% level1 pTrees, then entire batch would be FAUST classified in one horiz program. Or lev1 pCKNN. pDGP (pTree Darn Good Protection) by permuting col ord (permution = key). Random pre-pad for each bit-column would makes it impossible to break the code by simply focusing on the first bit row. More security?: all pTrees same (max) depth, and intron-like pads randomly interspersed... Relationships (rolodex cards) are 2 PTreeSets, AHGPeoplePTreeSet (shown) and AHGBasePairPositionPTreeSet (rotation of shown). Vertical Rule Mining, Vertical Multi-hop Rule Mining and Classification/Clustering methods (viewing AHG as either a People table (cols=BPPs) or as a BPP table (cols=People). MRM and Classification done in combination? Any table is a relationship between row and column entities (heterogeneous entity) - e.g., an image = [reflect. labelled] relationship between pixel entity and wavelength interval entity. Always PTreeSetting both ways facilitates new research and make horizontal row methods (using FPGAs) instantaneous (1 pass across the row pTree) Most bioinformatics done so far is not really data mining but is more toward the database querying side. (e.g., a BLAST search). A radical approach View whole Human Genome as 4 binary relationships between People and base-pair-positions (ordered by chromosome first, then gene region?). AHG [THG/GHG/CHG] is relationship between People and adenine(A) [thymine(T)/guanine(G)/cytosine(C)] (1/0 for yes/no) Order bpp? By chromosome and by gene or region (level2 is chromosome, level1 is gene within chromosome.) Do it to facilitate cross-organism bioinformatics data mining? Create both People and BPP-PTreeSet w human health records feature table (training set for classification and multi-hop ARM.) comprehensive decomp (ordering of bpps) FOR cross species genomic DM. If separate PTreeSets for each chrmomsome (even each region - gene, intron exon...) then we can may be able to dataming horizontally across the all of these vertical pTrees. The red person features used to define classes. AHGp pTrees for data mining. We can look for similarity (near neighbors) in a particular chromosome, a particular gene sequence, of overall or anything else.
Multi-hop Data Mining (MDM): relationship1 (Buys= B(P,I) ties table1 (People=P) to table2 (Items) Category color size wt store city state country 2 2 3 3 4 4 5 5 P 2 3 0 1 1 0 0 1 0 1 1 0 0 0 0 1 1 0 4 5 ct(|pAPpAND&iCPi)>mncf ct(|pAPp) friend of any in A will buy C if any in A buy C. ct(|pAPpAND |iCPi)>mncf ct(|pAPp) Change to "friend of any in A will buy something in C if any in A buy C. pc bc lc cc pe age ht wt tied by relationship2 (Friends=F(P,P) ) to table3 (also P). Can we do clustering and/or classification on one of the tables using the relationships to define "close" or to define the other notions? Find all strong, AC, AP, CI Frequent iff ct(PA) > minsup and Confident iff ct(&pAPpAND &iCPi) / ct(&pA Pp) > minconf Says: "A friend of all A will buy C if all A buy C." (the AND is always AND) Closures: A freq then A+ freq. AC not conf, then AC- not conf I=Items F(P,P)=Friends 0 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 B(P,I)=Buys P=People Define NearestNeighborVoterSet of {f} using strong R-rules with F in consequent? A strong cluster based on several self-relationships (different relationships, so it's not just strong implic both ways) strongly implies itself (or strongly implies itself after several hops (or when closing a loop).
Facebook-Buys: A facebook Member, m, purchases Item, x, tells all friends. Let's make everyone a friend of him/her self. Each friend responds back with the Items, y, she/he bought and liked. I≡Items I≡Items I≡Items F≡Friends(M,M) Members F≡Friends(K,B) F≡Friends(K,B) Buddies Buddies 1 0 1 1 4 1 1 0 0 1 1 1 1 4 4 0 1 0 0 3 0 0 1 1 0 0 0 0 3 3 1 0 0 1 2 1 1 0 0 0 0 1 1 2 2 0 0 1 0 1 0 0 0 0 1 1 0 0 1 1 P≡Purchase(M,I) P≡Purchase(B,I) P≡Purchase(B,I) Kiddos Kiddos 2 4 4 4 2 2 3 3 3 3 3 3 2 2 4 4 2 4 1 5 5 5 1 1 Members Groupies Groupies 4 4 1 1 0 0 1 1 1 1 4 4 1 2 4 2 2 2 4 1 3 3 0 0 1 1 0 0 0 0 3 3 2 2 1 1 0 0 0 0 1 1 2 2 0 0 1 1 0 1 0 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 0 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 0 0 0 0 0 1 1 1 4 4 4 3 3 3 2 2 2 1 1 1 4 4 4 0 0 0 0 1 1 0 0 1 1 1 0 0 0 0 0 0 0 Others(G,K) Compatriots (G,K) 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 2 2 2 1 0 0 0 1 1 0 0 Kx=OR Ogx frequent if Kx large (tractable- one x at a time and OR. gORbPxFb XI MX≡&xXPx People that purchased everything in X. FX≡ORmMXFb = Friends of a MX person. So, X={x}, is Mx Purchases x strong" Mx=ORmPxFmx frequent if Mx large. This is a tractable calculation. Take one x at a time and do the OR. K2 = {1,2,4} P2 = {2,4} ct(K2) = 3 ct(K2&P2)/ct(K2) = 2/3 Mx=ORmPxFmx confident if Mx large. ct( Mx Px ) / ct(Mx) > minconf To mine X, start with X={x}. If not confident then no superset is. Closure: X={x.y} for x and y forming confident rules themselves.... ct(ORmPxFm & Px)/ct(ORmPxFm)>mncnf Fcbk buddy, b, purchases x, tells friends. Friend tells all friends. Strong purchase poss? Intersect rather than union (AND rather than OR). Ad to friends of friends K2={2,4} P2={2,4} ct(K2) = 2 ct(K2&P2)/ct(K2) = 2/2 K2={1,2,3,4} P2={2,4} ct(K2) = 4 ct(K2&P2)/ct(K2)=2/4
The Multi-hop Closure Theorem A hop is a relationship, R, hopping from entities E to F. 4 U(H,I) 3 2 1 C I H G S(F,G) 0 1 0 1 4 0 0 0 1 3 1 0 1 0 2 0 0 0 1 1 T(G,H) 2 2 3 3 4 4 5 5 F 0 1 0 0 4 0 0 0 1 3 0 0 1 0 2 0 0 0 1 1 A R(E,F) E 0 1 1 0 1 1 1 1 0 0 1 0 1 1 0 1 0 0 0 0 0 0 0 1 1 1 0 0 0 1 0 1 downward closure: If a condition is true of A, then it is true for all subsets D of A. upward closure: If a condition is true of A then it is true of all supersets D of A. For transitive (a+c)-hop strong rule mine where the focus or count entity is a hops from the antecedent and c hops from the consequent, if a (or c) is odd/eventhendownward/upwardclosure applies to frequency (confidence). Odd downward Even upward The proof of the theorem: a pTree, X, is said to be "covered by" a pTree, Y, if 1-bit in X, there is a 1-bit at that same position in Y. Lemma-0: For any two pTrees, X and Y, X & Y is covered by X and ct(X) ct(X&Y) Proof-0: ANDing with Y may zero some of X's 1-positions but never ones any of X's 0-positions. Lemma-1: Let AB, &aBXa is covered by &aAXa Proof-1: Let Z=&aB-AXa then &aB Xa = Z & (&aA Xa), so the result follows from lemma-0. Lemma-2: For a (or c) =0, frequency and confidence are upward closed Proof-2: Lemma-3: If a (or c) we have upward/downward closure of frequency or confidence, then for a+1 (or c+1) we have downward/upward closer. Proof-3: Taking the a and upward closure, going to a+1 and DA, we are removing ANDs in the numerator for both frequency and confidence, so by Lemma-1, the a+1 numerator is covers the a numerator and therefore the a+1_count the a_count. Therefore, the condition (frequency or confidence) holds in the a+1 case and we have downward closure. ct(B)ct(A), so ct(A)>mnsp ct(B)>mnsp and ct(C&A)/ct(C)>mncf ct(C&B)/ct(C)>.mncf
The Multi-hop Closure Theorem A hop is a relationship, R, hopping from entities E to F. & & a(n-1)(&anARan) a(n-1)(&anDRan) & & a(n-2)& a(n-2)& a(n-1)(&anDRan) a(n-1)(&anARan) & & a(n-3)& a(n-3)& a(n-2)& a(n-2)& a(n-1)(&anDRan) a(n-1)(&anARan) downward closure: If a condition is true of A, then it is true for all subsets D of A. Odd downward Even upward upward closure: If a condition is true of A then it is true of all supersets D of A. For transitive (a+c)-hop strong rule mine where the focus entity is a hops from the antecedent and c hops from the consequent, if a (or c) is odd/eventhendownward/upwardclosure applies to frequency (confidence). A pTree, X, is "covered by" a pTree, Y, if 1-bit in X, there is a 1-bit at that same position in Y. Lemma-0: For any two pTrees, X&Y is covered by X and ct(X) ct(X&Y) Proof-0: ANDing with Y may zero some of X's 1-positions but never ones any of X's 0-positions. Lemma-1: Let AB, &aBXa is covered by &aAXa Proof-1: Let Z=&aB-AXa then &aB Xa = Z & (&aA Xa), so the result follows from lemma-0. &a1(&... )Sa2Ta1) ct( Lemma2: If n is even/odd Thresh is upward/downard closed on A &a(n-1)(&anARan) &anDRan &anARan Proof-2: Let AD, then
Dear Dr. Perrizo and All,I think I found a method to calculate mode of a dataset using pTrees.Assume we have a data set that is represented by three pTrees. So possible values of each data value is 0 to 7. Now if we do the following operations:F0 = count (P2'&P1'&P0') will give us frequency of value 0F1 = count (P2'&P1 &P0') will give us frequency of value 1F2 = count (P2'&P1 &P0') will give us frequency of value 2...F7 = count (P2 &P1 &P0 ) will give us frequency of value 7Now Mode = Max(F0, F1, ...,F7)Problem of this method is: if we have large number of pTrees then there will be large number of F operations and each F operation will involve many AND operations. For examples, if we have 8 pTrees then we'll have 2^8=256 F's and each F contains 8-1=7 AND operations.I have though of a solution that may overcome this problem: Assume we have 3 pTrees and Value=2 is the mode. So if we do F2=P2'&P1&P0' would give us maximum F value. Assume it is m. Now if we get the count of all individual component of F2 that is subsets ( P2', P1, P0, P2'&P1, P2'&P0', P1&P0', P2'&P1&P0') then all of them are must be greater than of equal to m (Down closure property).So to search for P2'&P1&P0' we can run an aprio like algorithm with singleton itemset P2, P2', P1, P1', P0, P0'. Then form doubleton P2P1, P2P1' ... etc. Now we need a support value for pruning. Obviously the support should be the mode but we do not know it ahead of time. So we can set a minimum value of mode as support. (Note: There cannot be any PiPi' doubleton as it is 0.)Minimum value of mode is Min(1, floor[Datasize/2^n]) where n is number of pTrees.Sorry I cannot give any example now but I can try to give an example in the white board. Thanks.Sincerely,Mohammad
Given a n-row table, a row predicate (e.g., a bit slice predicate, or a category map) and a row ordering (e.g., asc on key; or for spatial data, col/row-raster, Z, Hilbert), the sequence of predicate truth bits is the raw or level-0predicate Tree (pTree) for that table, row predicate and row order. gte75% str=5 P1C=red 0 0 1 gte50% str=5 P1C=red 0 0 1 pure1 str=5 P1C=red 0 0 0 gte25% str=5 P1C=red 1 1 1 0 1 1 1 1 0 1 0 0 0 level-2 gte50% stride=2 1 1 P2gte50%,s=4,SL,0 0 1 1 1 level-1 gt50 stride=4 pTree level-1 gt50 stride=2 pTree gte50% stride=5 P1SL,1 1 0 0 pure1 str=5 P1SL,1 0 0 0 gte25% str=5 P1SL,1 1 1 1 gte75% str=5 P1SL,1 1 0 0 IRIS Table NameSLSWPLPWColor setosa 38 38 14 2 red setosa 50 38 15 2 blue setosa 50 34 16 2 red setosa 48 42 15 2 white setosa 50 34 12 2 blue versicolor 51 24 45 15 red versicolor 56 30 45 14 red versicolor 57 28 32 14 white versicolor 54 26 45 13 blue versicolor 57 30 42 12 white virginica 73 29 58 17 white virginica 64 26 51 22 red virginica 72 28 49 16 blue virginica 74 30 48 22 red virginica 67 26 50 19 red pred: rem(div(SL/2)/2)=1 order: given order P0SL,0 0 0 0 0 0 1 0 1 1 1 1 0 0 0 1 P0Color=red 1 0 1 0 0 1 1 0 0 0 0 1 0 1 1 P0SL,1 1 1 1 0 1 1 0 0 1 0 0 0 0 1 1 predicate: remainder(SL/2)=1 order: the given table order pred: Color=red order: given ord Given a raw pTree, P, a partitioned of it, par, and a bit-set predicate, bsp (e.g., pure1, pure0, gte50%One), the level-1 par, bsp pTree is the string of truths of bsp on consecutive partitions of par. If the partition is an equiwidth=m intervalization, it's called the level-1 stride=m bsp pTree. gte50% stride=5 P1PW<7 1 0 0 pred: PW<7 order: given gte50% st=5 pTree predicts setosa. P1gte50%,s=4,SL,0≡ gte50% stride=4 P1SL,0 0 1 1 1 gte50% stride=8 P1SL,0 0 1 gte50% stride=4 P1SL,0 0 1 1 1 rem(SL/2)=1 ord: given pred: rem(SL/2)=1 ord: given order P0PW<7 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 P0SL,0 0 0 0 0 0 1 0 1 1 1 1 0 0 0 1 1 P0SL,0 0 0 0 0 0 1 0 1 1 1 1 0 0 0 1 1 R11 1 0 0 0 1 0 1 1 lev2 pTree= lev1 pTree on a lev1. (1col tbl) raw level-0 pTree gte50_P11 1 gte50% stride=16 P1SL,0 0
R G ir1 ir2 std 8 15 13 9 1 8 13 13 19 2 5 7 7 6 3 6 8 8 7 4 6 12 13 13 5 5 8 9 7 7 R G ir1 ir2 mn 62.83 95.29 108.12 89.50 1 48.84 39.91 113.89 118.31 2 87.48 105.50 110.60 87.46 3 77.41 90.94 95.61 75.35 4 59.59 62.27 83.02 69.95 5 69.01 77.42 81.59 64.13 7 FAUST Satlog evaluation 1 2 3 4 5 7 tot 461 224 397 211 237 470 2000 TP actual 99 193 325 130 151 257 1155 TP nonOb L0 pure1 212 183 314 103 157 330 1037 TP nonOblique 14 1 42 103 36 189 385 FP level-1 50% 322 199 344 145 174 353 1537 TP Obl level-0 28 3 80 171 107 74 463 FP MeansMidPoint 359 205 332 144 175 324 1539 TP Obl level-0 29 18 47 156 131 58 439 FP s1/(s1+s2) 410 212 277 179 199 324 1601 TP 2s1/(2s1+s2) 114 40 113 259 235 58 819 FP Ob L0 no elim 309 212 277 154 163 248 1363 TP 2s1/(2s1+s2) 22 40 65 211 196 27 561 FP Ob L0 234571 329 189 277 154 164 307 1420 TP 2s1/(2s1+s2) 25 1 113 211 121 33 504 FP Ob L0 347512 355 189 277 154 164 307 1446 TP 2s1/(2s1+s2) 37 18 14 259 121 33 482 FPOb L0425713 2 33 56 58 6 18 173 TP BandClass rule 0 0 24 46 0 193 263 FP mining (below) red green ir1 ir2 abv below abv below abv below abv below avg 1 4.33 2.10 5.29 2.16 1.68 8.09 13.11 0.94 4.71 2 1.30 1.12 6.07 0.94 2.36 3 1.09 2.16 8.09 6.07 1.07 13.11 5.27 4 1.31 1.09 1.18 5.29 1.67 1.68 3.70 1.07 2.12 5 1.30 4.33 1.12 1.32 15.37 1.67 3.43 3.70 4.03 7 2.10 1.31 1.32 1.18 15.37 3.43 4.12 pmr*pstdv + pmv*2pstdr 2pstdr a = pmr + (pmv-pmr) = pstdr +2pstdv pstdv+2pstdr G[0,46]2 G[47,64]5 G[65,81]7 G[81,94]4 G[94,255]{1,3} R[0,48]{1,2} R[49,62]{1,5} above=(std+stdup)/gap below=(std+stddn)/gapdn suggest ord 425713 cls avg 4 2.12 2 2.36 5 4.03 7 4.12 1 4.71 3 5.27 R[82,255]3 ir1[0,88]{5,7} ir2[0,52]5 NonOblique lev-0 1's 2's 3's 4's 5's 7's True Positives: 99 193 325 130 151 257 Class actual-> 461 224 397 211 237 470 2s1, # of FPs reduced and TPs somewhat reduced. Better? Parameterize the 2 to max TPs, min FPs. Best parameter? NonOblq lev1 gt50 1's 2's 3's 4's 5's 7's True Positives: 212 183 314 103 157 330 False Positives: 14 1 42 103 36 189 Oblique level-0 using midpoint of means 1's 2's 3's 4's 5's 7's True Positives: 322 199 344 145 174 353 False Positives: 28 3 80 171 107 74 Oblique level-0 using means and stds of projections (w/o cls elim) 1's 2's 3's 4's 5's 7's True Positives: 359 205 332 144 175 324 False Positives: 29 18 47 156 131 58 Oblique lev-0, means, stds of projections (w cls elim in 2345671 order)Note that none occurs 1's 2's 3's 4's 5's 7's True Positives: 359 205 332 144 175 324 False Positives: 29 18 47 156 131 58 Oblique level-0 using means and stds of projections, doubling pstd No elimination! 1's 2's 3's 4's 5's 7's True Positives: 410 212 277 179 199 324 False Positives: 114 40 113 259 235 58 Oblique lev-0, means, stds of projs,doubling pstdr, classify, eliminate in 2,3,4,5,7,1 ord 1's 2's 3's 4's 5's 7's True Positives: 309 212 277 154 163 248 False Positives: 22 40 65 211 196 27 Oblique lev-0, means,stds of projs,doubling pstdr, classify, elim 3,4,7,5,1,2 ord 1's 2's 3's 4's 5's 7's True Positives: 329 189 277 154 164 307 False Positives: 25 1 113 211 121 33 2s1/(2s1+s2) elim ord: 425713 TP: 355 205 224 179 172 307 FP: 37 18 14 259 121 33 Conclusion? MeansMidPoint and Oblique std1/(std1+std2) are best with the Oblique version slightly better. I wonder how these two methods would work on Netflix? Two ways: UTbl(User, M1,...,M17,770) (u,m); umTrainingTbl = SubUTbl(Support(m), Support(u), m) MTbl(Movie, U1,...,U480189) (m,u); muTrainingTbl = SubMTbl(Support(u), Support(m), u)
Netflix data{mk}k=1..17770 UPTreeSet 3*17770 bitslices wide UserTable(uID,m1,...,m17770) m0,2 . . . m17769,0 u1 : uk . . . u480189 m1 ... mh ... m17770 u1 : uk . . . u480189 mk(u,r,d) avg:5655u/m m 1 2 4 5 5 m 1 2 4 5 5 uIDrating date u i1rmk,u dmk,u ui2 . . . ui n k 1/0 rmhuk u 324513?45 u 324513?45 Main:(m,u,r,d) avg:209m/u mIDuIDrating date m1 u 1 rm,u dm,u m1 u2 . . . m17770 u480189 r17770,480189 d17770,480189 or U2649429 -------- 100,480,507 -------- 47B 47B MTbl(mID,u1...u480189) MPTreeSet 3*480189 bitslices wide u1 uk u480189 m1 : m h : m17770 u0,2 u480189,0 m1 : m h : m17770 0/1 rmhuk 47B 47B (u,m) to be predicted, form umTrainingTbl=SubUTbl(Support(m),Support(u),m) Lots of 0s in vector sp, umTraningTbl). Want the largest subtable without zeros. How? SubUTbl( nSup(u)mSup(n), Sup(u),m)? Using Coordinate-wise FAUST (not Oblique), in each coordinate, nSup(u), divide up all users vSup(n)Sup(m) into their rating classes, rating(m,v). then: 1. calculate the class means and stds. Sort means. 2. calculate gaps 3. choose best gap and define cutpoint using stds. Coord FAUST, in each coord, vSup(m), divide up all movies nSup(v)Sup(u) to rating classes 1. calculate the class means and stds. Sort means. 2. calculate gaps 3. choose best gap and define cutpoint using stds. Of course, the two supports won't be tight together like that but they are put that way for clarity. This of course may be slow. How can we speed it up? Gaps alone not best (especially since the sum of the gaps is no more than 4 and there are 4 gaps). Weighting (correlation(m,n)-based) useful (higher the correlation the more significant the gap??) Ctpts constructed for just this one prediction, rating(u,m). Make sense to find all of them. Should just find, e,g, which n-class-mean(s) rating(u,n) is closest to and make those the votes? (u,m) to be predicted, from umTrainingTbl = SubUTbl(Support(m), Support(u),m)