Download

1 / 34
340 likes | 506 Views
Nesting Paging in VM Replay for MPs. Jaehyuk Huh Computer Science, KAIST. Address Translation in VM. Need to translate guest VA ( gVA ) to machine address gVA (guest VA) gPA (guest PA) sPA (system PA) Paravirtualization

E N D
Nesting Paging in VMReplay for MPs Jaehyuk Huh Computer Science, KAIST
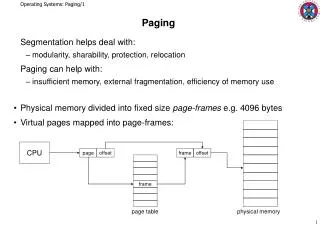
Address Translation in VM • Need to translate guest VA (gVA) to machine address • gVA (guest VA) gPA (guest PA) sPA (system PA) • Paravirtualization • Guest page table (managed by guest OS) directly maps gVA to sPA • Hypervisor validates guest page table • Full virtualization • SW technique: shadow paging • HW-assisted technique: nested paging
Shadow Page Table • Shadow page table (sPT) • translate from gVA to sPA • maintained by VMM (hypervisor) • VMM intercepts the updates of page table base address • CR3 updates in x86 • Set CR3 with sPT base address instead of gPT base address • must be consistent with guest page table (gPT) gPT updates must be reflected in sPT • Any page fault must be intercepted by VMM • VMM must tell guest-induced page-faults from VMM-induced ones • Vectors guest-induced page-faults to guest OS • High overheads for page fault handling
How to make gPT and sPT consistent? • Write-protecting gPT • Any modification of gPT (add or remove a translation) causes a fault • VMM updates sPT accordingly • Exploiting page-fault behavior and TLB consistency rules • Adding a page translation • Guest OS can add a new translation to gPT without interception by VMM • Later accesses by guest VM causes a page fault on the new translation • VMM updates sPT on the page fault: must inspect gPT to find out the new page • Deleting a page translation • Guest OS executes INVLPG to invalidate TLB entry • VMM intercept the execution and remove the entry from sPT
Overheads of Shadow Paging • Any page fault requires the expensive VMM intervention • Guest-induced page fault • Hypervisor-induced page faults • Accessed and dirty bit updates • HW page walker sets bits in sPT(not gPT) • Guest OS need the information to make paging decision • Dirty bit example: set pages pointed by sPT read-only • Problems in MPs • What if a VM uses multiple processors? • Replicating sPT for each processor? memory overheads • Sharing sPT? synchronizing sPT for any change
Nesting Page Table • A source of address translation overheads in traditional x86 VMM • a fixed hardware page walker to handle a TLB miss • Can walk from only one page table (pointed by CR3) • Nested paging • Separate HW states affecting paging (two copies of CR3 etc … ) for guest OS and VMM • HW page walker can walk both gPT and sPT • TLB can holds a translation from gVA to sPT directly • Benefits: No more traps on Guest Page Table accesses • Drawback: Extra page table steps add latency to TLB miss • May add extra caching for page translation • Nested TLB • 2D page walk cache
Address Space IDs • Old x86 did not support address space IDs (ASID) in TLBs • must flush TLBs for VM switch • Assign ASID for each VM • Still need to flush TLBs for context switch within a VM
Replay Papers • VM-based replay • Execution Replay for Multiprocessor Virtual Machines • Dunlap et al • HW-based replay • Rerun: Exploiting Episodes for Lightweight Memory Race Recording • Hower and Hill • ODR: Output-Deterministic Replay for Multicore Debugging • Altekar and Stoica • Slides adapted from the presentation slides by the paper authors
Big ideas • Detection and replay of memory races is possible on commodity hardware • Overhead high for some workloads • …but surprisingly low for other workloads
Execution Replay CPU Interrupts Network Memory Keyboard, mouse Disk
Deterministic Replay • Deterministic Replay • Faithfully replay an execution such that all instructions appear to complete in the same order and produce the same result • Valuable • Debugging [LeBlanc, et al. - COMP ’87] • e.g., time travel debugging, rare bug replication • Fault tolerance [Bressoud, et al. - SIGOPS ‘95] • e.g., hot backup virtual machines • Security [Dunlap et al. – OSDI ‘02] • e.g., attack analysis • Tracing [Xu et al. – WDDD ‘07] • e.g., unobtrusive replay tracing
Single-processor Replay • Basic principles well understood • Log all non-deterministic inputs • Timing of asynchronous events • Minimal overhead (Dunlap02) • 13% worst case • Log for months or years • Available commercially • VMWare: Record/Replay
The Multiprocessor Challenge • Interleaved reads and writes • Fine-grained non-determinism • Much more difficult • Existing solutions • Hardware modification • Software instrumentation • SMP-ReVirt • Hardware MMU to detect sharing
Multiprocessor Replay P2 P1 P1 P2 n=5 n=3 Memory if (n<4)
Ordering Memory Accesses • Preserving order will reproduce execution • a→b: “a happens-before b” • Ordering is transitive: a→b, b→cmeans a→c • Two instructions must be ordered if: • they both access the same memory, and • one of them is a write
To guarantee a→d: a→d b→d a→c b→c Suppose we need b→c b→c is necessary a→d is redundant Constraints: Enforcing order P1 P2 a b overconstrained c d
CREW Protocol • Each shared object in one of two states: • Concurrent-Read:all processors can read, none can write • Exclusive-Write: one processor (the owner) can read and write; others have no access • Enforced with hardware MMU • Read/write • Read-only • None • Change CREW states on demand • Fault, fixup, re-execute • CREW event • Increasing or reducing permission due to CREW state changes
CREW Property • If two instructions on different processors: • access the same page, • and one of them is a write, • there will be a CREW event on each processor between them.
Generating Constraints • State: Concurrent Read • All processors read-only • d*: CREW fault • New state: P2 Exclusive • r: privilege reduction • Read to None • i: privilege increase • Read to Read/write • Log timing of r and i • Constraint: • r → i P1 P2 a d* r i d
Predicting results • Key changes in sharing attributes • 4096-byte sharing granularity • “Miss” is very expensive • SPLASH2 • Good: high spatial locality / low false sharing • Bad: random access patterns / high false sharing • The Linux kernel • Tuned to 16-byte cacheline • Involving the kernel may be expensive
HW Memory Race Recording • SW only approach • Too slow to be turned on always • SW alter execution path • Want • Small log – record longer for same state • Small hardware – reduce cost, especially when not used • Unobtrusive – should not alter execution • Rerun: Exploiting Episodes for Lightweight Memory Race Recording
Episodic Recording • Most code executes without races • Use race-free regions as unit of ordering • Episodes: independent execution regions • Defined per thread • Identified passively does not affect execution • Encompass every instruction T0 T1 T2 ST V LD A ST E ST Z ST B LD B LD W ST C ST X LD J LD F LD R LD J LD X ST T LD V LD Q ST C ST Q ST E ST C ST X LD Z
Capturing Causality • Via scalar Lamport Clocks [Lamport ‘78] • Assigns timestamps to events • Timestamp order implies causality • Replay in timestamp order • Episodes with same timestamp can be replayed in parallel T0 T1 T2 60 43 22 61 23 23 44 44 62 45
Episode Benefits • Multiple races can be captured by a single episode • Reduces amount of information to be logged • Episodes are created passively • No speculation, no rollback • Episodes can end early • Eases implementation • Episode information is thread-local • Promotes scalability, avoids synchronization overheads
Rerun L2/Memory State Hardware • Rerun requirements: • Detect races track r/w sets • Mark episode boundaries • Maintain logical time Data Tags Directory Coherence Controller Base System Total State: 166 bytes/core L2 0 L2 1 L2 14 L2 15 … DRAM Memory Timestamp(MTS) DRAM Interconnect 32 bytes 4 bytes Core 0 Core 1 … Core 14 Core 15 Write Filter (WF) Read Filter (RF) Coherence Controller References (REFS) 128 bytes Timestamp (TS) 2 bytes L1 I L1 D 4 bytes Rerun Core State Pipeline
HW Replay Summary • Require some modification to existing HW • will CPU manufacturers add the support any time soon? not likely • Other low overhead approaches with SW-based replay • ODR: Output-Deterministic Replay for MulticoreDebugging, Altekarand Stoica, SOSP 09