Download

1 / 27
270 likes | 368 Views
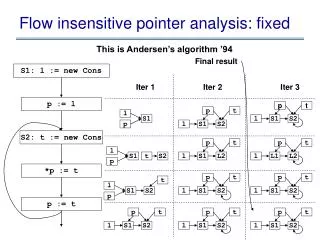
Flow-Insensitive Points-to Analysis with Term and Set Constraints. Presentation by Kaleem Travis Patrick. Two methods:. Andersen vs Steensgaard Foster claims these systems are nearly identical, and may actually be combined in their implementation. Andersen:

E N D
Flow-Insensitive Points-to Analysis with Term and Set Constraints Presentation by Kaleem Travis Patrick
Two methods: • Andersen vs Steensgaard • Foster claims these systems are nearly identical, and may actually be combined in their implementation.
Andersen: For an assignment e1 = e2 anything in the points-to set for e2 must also be in the points-to set for e1. Steensgaard: For an assignment e1 = e2 the points-to set for e2 must be equal to the points-to set for e1.
Foster’s Framework Foster's type systems are designed using Term and Set constraints: • Set constraints define inclusion relationships between types; we use set constraints to describe Andersen's analysis. • Term constraints define equality relationships between types; we use term equations to describe Steensgaard's analysis.
What’s so important about their similarity? The main difference between the Steensgaard and Andersen is Steensgaard uses term constraints as opposed set constraints.Term constraints describe equality. Set constraints describe inclusion By carefully defining our inference rules for both methods, the implementation is vastly simplified. This is because both methods will be combined into one set of inference rules. The difference in set constraints is minimal in the implementation.
Const - Int S: _ is a wildcard - a fresh, unconstrained variable Var S: variables are elevated to references for simplicity
Addr S: &e points to e Deref S: if e is a reference to a then *e is of type a
Asst S: unifies the equivalence classes for the points-to sets of e1 and e2 In other words, if e1 is of type t1and e2 is of type t2 then e1 = e2 is of type t2 This is where Steensgaard uses his time-saving, conservative merging.
Const - Int A: assigns the empty set for integers. Foster uses 0 instead of “bottom” 0 stands for the “least set” Var A: lifts regular variables to a pointer type for simplicity, as with Steensgaard. But we now have to take into account covariance/contravariance.
Addr A: &e points to e Deref A: *e is an upper bound on the type of whatever e points to. In other words, this is nearly the inverse of Addr A.
Asst A: illustrates the difference between Andersen and Steensgaard - in the assignment e1=e2, e1 could potentially point to anything e2 can, so the type of the expression is the type of e2
Constructor Signatures The constructor signatures (section 3) merely describe a key difference between the two algorithms. • Set constraints describe Andersen's analysis. • Term constraints describe Steensgaard's analysis. • This difference must also be handled when combining both algorithms
Combining And/Ste • Foster combines the type languages for And and Ste by redefining their constructor signatures to yield a reference with two p fields and a tag field: ref (pget, pset, t) (page 11) • For Andersen analysis, the Pget fields are covariant, the Pset fields are contravariant, and the t (tag) field is ignored. • For Steensgaard analysis, all the subfields are Term fields, and we can assure that Pget=Pset.
After redefining the signatures for constructors, Foster combines And+Common with Ste+Common to arrive at the final set of inference rules, named Comb At this point, we no longer need to worry about separate And and Ste inference rules. Comb+Common represents both at once. This vastly simplifies the implementation of both algorithms.
How does Comb work? The only difference between Comb and And/Ste is the use of the tag field t and the definition of a general-purpose symbol for the constraints. First, the tag t is shown in Ste+Common. It is used to identify equivalence classes. And+Common deals with inclusion rather than equivalence, so Comb’s tag field is simply ignored when we wish to use it for Andersen-style results.
How does Comb work? Second, changing the interpretation of the general-purpose constraint symbol (subset-iota) yields the two different algorithms. • If it is used as a subset constraint, the rules compute Andersen's analysis. • Steensgaard instead treats this constraint as conditional unification. Also, Pget=Pset, because the distinction is not used in Ste+Common
Implementation There are 3 major problems with using C for the implementation.
Problem 1 We must determine how library functions affect the points-to graph without looking at their source. • First, assume that most undefined functions have no effect on the analysis. • Second, for those functions that do have an effect (such as strcpy(char* s1, char s2), we write a false stub of the function that provides enough information to the analysis to determine how the real function behaves.
Problem 2 Some functions can take a variable number of arguments. • For the most part, C implementations of varargs do not affect the points-to set. • But some implementations accomplish varargs by treating the first argument as a pointer to any subsequent arguments. • None of these algorithms handle this correctly. Foster manually modified the vararg functions to take a fixed number of arguments
Problem 3 When a multidimensional array is allocated, C actually uses a contiguous block of memory. So if b is two-dimensional and a is one-dimensional, the statement: b = (int**) a; results in b[0][0] being an alias to a[0]. Dealing with this added complexity involves determining the C types for each expression, adding more overhead to the existing algorithms.