Download

1 / 29
290 likes | 442 Views
CMP L2 Cache Management. Presented by: Yang Liu CPS221 Spring 2008. Based on: Optimizing Replication, Communication, and Capacity Allocation in CMPs, Z. Chishti, M. Powell, and T. Vijaykumar ASR: Adaptive Selective Replication for CMP Caches, B. Beckman, M. Marty, and D. Wood. Outline.

E N D
CMP L2 Cache Management Presented by: Yang Liu CPS221 Spring 2008 Based on: Optimizing Replication, Communication, and Capacity Allocation in CMPs, Z. Chishti, M. Powell, and T. Vijaykumar ASR: Adaptive Selective Replication for CMP Caches, B. Beckman, M. Marty, and D. Wood
Outline • Motivation • Related Work (1) – Non-uniform Caches • CMP-NuRAPID • Related Work (2) – Replication Schemes • ASR
Motivation • Two options for L2 caches in CMPs • Shared: high latency because of wire delay • Private: more misses because of replications • Need hybrid L2 caches • Take in mind • On-chip communication is fast • On-chip capacity is limited
NUCA • Non-Uniform Cache Architecture • Place frequently-accessed data closest to the core to allow fast access • Couple tag and data placement • Can only place one or two ways in each set close to the processor
NuRAPID • Non-uniform access with Replacement And Placement usIng Distance associativity • Decouple the set-associative way number from data placement • Divide the cache data array into d-groups • Use forward and reverse pointers • Forward: from tag to data • Reverse: from data to tag • One to one?
CMP-NuRAPID - Overview • Hybrid private tag • Shared data organization • Controlled Replication – CR • In-Situ Communication – ISC • Capacity Stealing – CS
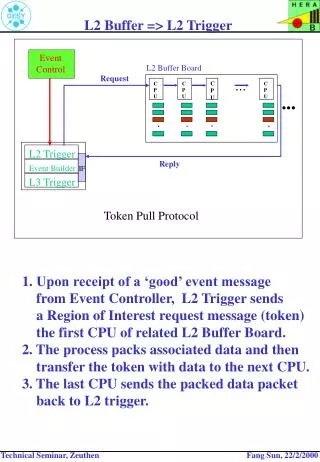
CMP-NuRAPID – Structure • Need carefully chosen d-group preference
CMP-NuRAPID – Data and Tag Array • Tag arrays snoop on bus to maintain coherence • The data array is accessed through a crossbar
CMP-NuRAPID – Controlled Replication • For read-only sharing • First use no copy, save capacity • Second copy, reduce future access latency • In total, avoid off-chip misses
CMP-NuRAPID – Time Issues • Start to read before the invalidation and end after the invalidation • Mark the tag for the block being read from a farther d-group busy • Start to read after the invalidation begins and end before the invalidation completes • Put an entry in the queue that holds the order of the bus transaction before sending a read request to a farther d-group
CMP-NuRAPID – In-situ Communication • For read-write sharing • Communication state • Write-through for all C blocks in L1 cache
CMP-NuRAPID – Capacity Stealing • Demote less-frequently-used data to unused frames in the d-groups closer to the cores with less capacity demands • Placement and Promotion • Place all private blocks in the d-group closest to the initiating core • Promote the block directly to the closest d-group for the core
CMP-NuRAPID – Capacity Stealing • Demotion and Replacement • Demote the block to the next-fastest d-group • Replace in the order of invalid, private, and shared • Doesn’t this kind of demotion pollute another core’s fastest d-group?
CMP-NuRAPID - Methodology • Simics • 4-core CMP • 8 MB, 8-way CMP-NuRAPID with 4 single-ported d-groups • Both multithreaded and multiprogrammed workloads
Replication Schemes • Cooperative Caching • Private L2 caches • Restrict replication under certain criteria • Victim Replication • Share L2 cache • Allow replication under certain criteria • Both have static replication policies • How about dynamic?
ASR - Overview • Adaptive Selective Replication • Dynamic cache block replication • Replicate blocks when the benefits exceed the costs • Benefits: lower L2 hit latency • Costs: More L2 misses
ASR – Sharing Types • Shingle Requestor • Blocks are accessed by a single processor • Shared Read-Only • Blocks are read, but not written, by multiple processors • Shared Read-Write • Blocks are accessed by multiple processors, with at least one write • Focus on replicating shared read-only blocks • High locality • Little Capacity • Large portion of requests
ASR - SPR • Selective Probabilistic Replication • Assume private L2 caches and selectively limits replication on L1 evictions • Use probabilistic filtering to make local replication decisions
ASR – Replication Control • Replication levels • C: Current • H: Higher • L: Lower • Cycles • H: Hit cycles-per-instruction • M: Miss cycles-per-instruction
ASR – Replication Control • Wait until there are enough events to ensure a fair cost/benefit comparison • Wait until four consecutive evaluation intervals predict the same change before change the replication level
ASR – Designs Supported by SPR • SPR-VR • Add 1-bit per L2 cache block to identify replicas • Disallow replications when the local cache set is filled with owner blocks with identified sharers • SPR-NR • Store a 1-bit counter per remote processor for each L2 block • Remove the shared bus overhead (How?) • SPR-CC • Model the centralized tag structure using an idealized distributed tag structure
ASR - Methodology • Two CMP configurations – Current and Future • 8 processors • Writeback, write-allocate cache • Both commercial and scientific workloads • Use throughput as metrics
Conclusion • Hybrid is better • Dynamic is better • Need tradeoff • How does it scale…