Download

1 / 41
430 likes | 1.08k Views
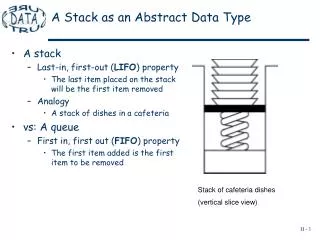
Chapter 3 스택과 큐 (Stack and Queue) 2009. 3. 30. 스택 (Stack). 정의 top 이라고 하는 한쪽 끝에서 모든 삽입 (push) 과 삭제 (pop) 가 일어나는 순서 리스트 S = (a 0 , a 1 , …, a n-1 ), n 0 a 0 는 bottom, a n-1 은 top 의 원소 a i 는 원소 a i-1 (0<i<n) 의 위에 있음 후입선출 (Last-In-First-Out: LIFO) 리스트. a n-1. top. a n-2. …. a 1.

E N D
스택 (Stack) • 정의 • top 이라고 하는 한쪽 끝에서 모든 삽입(push)과 삭제(pop)가 일어나는 순서 리스트 • S = (a0, a1, …, an-1), n 0 • a0는 bottom, an-1은 top의 원소 • ai는 원소 ai-1(0<i<n)의 위에 있음 • 후입선출(Last-In-First-Out: LIFO) 리스트 an-1 top an-2 … a1 a0 bottom
스택 (Stack) • 스택에 원소 A,B,C,D,E를 삽입하고 한 원소를 삭제하는 예 top E top D D top D top C C C C B top B B B B A A A A A top A add (push) add add add add del (pop)
스택 (Stack) 이용 예 • 시스템 스택 • 프로그램 실행 시 함수 호출을 처리하는 방법 • 함수 호출시 스택 프레임(stack frame) 또는 활성 레코드(activation record)라는 구조를 생성하여 스택에 저장 • 복귀 주소: 호출자의 호출 다음 명령어에 대한 주소 • 함수가 종료된 후 실행되어야 할 명령문 위치 • 동적 링크: 호출자의 스택 프레임에 대한 포인터 • 함수 종료 시 스택 프레임 제거에 사용 • Stack Top 포인터를 이 값으로 갱신 • 매개 변수: 호출자가 제공한 값 또는 주소 • 지역 변수: 피호출 함수에서 정의된 변수 • 함수 복귀시 스택 프레임 삭제 • 순환 호출 (recursive call) • 순환 호출시마다 새로운 스택 프레임 생성 • 최악의 경우 가용 메모리를 모두 소모할 수 있음 Stack Top Local variables Parameters Dynamic link Return address Local variables Parameters Dynamic link Return address
스택 (Stack) 이용 예 • 함수 호출 구현 예 void C (int Q) { … } void A (int X) { int Y; … C(Y); } void B (float R) { int S, T; … A(S); } void main () { float P; … B(P); } 시스템 스택의 내용
스택 (Stack) ADT 정의 • 스택 추상 데이터 타입 structure Stack objects: 0개 이상의 원소를 가진 유한 순서 리스트 functions: 모든 stack∈ Stack, item∈ element, max_stack_size∈ positive integer Stack CreateS(max_stack_size) ::= 최대 크기가 max_stack_size인 공백 스택을 생성 Boolean IsFull(stack, max_stack_size) ::= if (stack의 원소수 == max_stack_size) return TRUE else return FALSE Stack Push(stack, item) ::= if (IsFull(stack)) stackFull else stack의 Top에 item을 삽입하고 return Boolean IsEmpty(stack) ::= if (stack의 원소수 == 0)) return TRUE else return FALSE Element Pop(stack) ::= if (IsEmpty(stack)) return else 스택 Top 의 item을 제거해서 반환
스택 (Stack) ADT 구현 • 스택 구현 • 일차원 배열 stack[MAX_STACK_SIZE] 사용 • i 번째 원소는 stack[i-1]에 저장 • 변수 top은 항상 스택의 최상위 원소를 가리키도록 함(초기화: top = -1; 공백스택을 의미함)
스택 (Stack) ADT 구현 • CreateS 와 stackFull의 구현 Stack CreateS(max_stack_size) ::= #define MAX_STACK_SIZE 100 /*최대 스택 크기*/ typedef struct { int key; /* 다른 필드들 */ } element; element stack[MAX_STACK_SIZE]; /* 전역 번수 */ int top = -1; /* 전역 번수 */ Boolean IsEmpty(Stack) ::= top < 0; Boolean IsFull(Stack) ::= top >= MAX_STACK_SIZE-1; void stackFull() { fprintf(stderr, “Stack is full, cannot add element”); exit(EXIT_FAILURE); }
스택 (Stack) ADT 구현 • Push 및 Pop 연산 구현 void push(element item) {/* 전역 stack에 item을 삽입 */ if (top >= MAX_STACK_SIZE-1) stackFull(); stack[++top] = item; } top = top + 1; stack[top] = item; 스택에 원소삽입 element pop() {/* stack의 최상위 원소를 삭제하고 반환 */ if (top == -1) return stackEmpty(); /* returns an error key */ return stack[top--]; } element e = stack[top]; top = top - 1; return e; 스택으로부터 삭제
동적 배열을 사용하는 스택 • 동적 배열을 이용 • 스택의 범위(MAX_STACK_SIZE)를 컴파일 시간에 알아야 하는 단점 극복 • 원소를 위해 동적으로 할당된 배열을 이용하고, 필요 시 배열의 크기를 증대시킴 Stack CreateS() ::= typedef struct { int key; /* 다른 필드 */ } element; element *stack; MALLOC(stack, sizeof(*stack)); int capacity = 1; int top = -1; Boolean IsEmpty(Stack) ::= top < 0; Boolean isFull(Stack) ::= top >= capacity-1; 초기 크기가 1인 동적할당 배열 stack을 사용
동적 배열을 사용하는 스택 • 스택 full에 대한 새로운 검사 이용 • MAX_STACK_SIZE를 capacity로 대체 • 함수 push 변경 • 함수 stackFull 변경 • 배열 stack의 크기를 확장시켜서 스택에 원소를 추가로 삽입할 수 있도록 함 • 배열 배가(array doubling) : 배열의 크기를 늘릴 필요가 있을 시 항상 배열의 크기를 두 배로 만듦 void stackFull() { REALLOC(stack, 2*capacity*sizeof(*stack)) capacity *= 2; }
참고: C++에서의 스택 ADT 구현 예 • stack 클래스 정의 #include <iostream.h> class stack { private: int* stackPtr; int maxLen; int topPtr; public: stack(int maxSize) { // constructor stackPtr = new int [maxSize]; maxLen = maxSize-1; topPtr = -1; } ~stack() { delete[] stackPtr; } //destructor void push(int number) { if (topPtr == maxLen) cerr << “Error in push - stack is full\n”; else stackPtr [++topPtr] = number; } void pop() { if (topPtr == -1) cerr << “Error in pop - stack is full\n”; else return stackPtr[topPtr--]; } int top() { return stackPtr[topPtr]; } int isEmpty() { return (topPtr == -1); } int isEull() { return (topPtr == maxLen); } }
참고: C++에서의 스택 ADT 구현 예 • stack 클래스 이용 void main() { int topOne; stack myStack(100); // stack 클래스의 instance 생성 … myStack.push(42); myStack.push(17); … topOne = myStack.top(); … topOne = myStack.pop(); … } Note: 스택 top이클래스 내에 private member로 정의되므로 외부에서 직접 이용할 수 없음 (스택 내부 구조에 대해 접근 불가)
Ticket Box 큐(Queue) • 정의 • 한쪽 끝(rear)에서 삽입이 일어나고 그 반대쪽 끝(front)에서 삭제가 일어나는 순서 리스트 • Q = (a0, a1, …, an-1), n 0 • a0는 앞(front) 원소, an-1은 뒤(rear) 원소 • ai는 원소 ai-1(0i<n)의 뒤에 있다고 함 • 선입선출(First-In-First-Out: FIFO) 리스트 … an-2 an-1 a1 a0 front rear
큐(Queue) • 큐에 원소 A, B, C, D, E를 삽입하고 한 원소를 삭제하는 예 add B add A add B add C add D add E
큐(Queue)의 활용 • 응용 예 • 시뮬레이션의 대기열(공항에서의 비행기들, 은행에서의 대기열) • 통신에서의 데이터 패킷들의 모델링 • 프린터와 컴퓨터 사이의 버퍼링 • 많은 알고리즘에서 사용됨 data QUEUE 생산자 소비자
큐(Queue) ADT 정의 • 큐 추상 데이터 타입 structure Queue objects: 0개 이상의 원소를 가진 유한 순서 리스트 functions: 모든 queue∈Queue, item∈element,max_queue_size∈positive integer Queue CreateQ(max_queue_size) ::= 최대 크기가 max_queue_size인 공백 큐를 생성 Boolean IsFullQ(queue, max_queue_size ) ::= if (queue의 원소수 == max_queue_size) return TRUE else return FALSE Queue AddQ(queue, item) ::= if (IsFull(queue)) queueFull else queue의 뒤에 item을 삽입하고 이 queue를 반환 Boolean IsEmptyQ(queue) ::= if (queue의 원소수 == 0) return TRUE else return FALSE Element DeleteQ(queue) ::= if (IsEmpty(queue)) return else queue의 앞에 있는 item을 제거해서 반환
큐(Queue) ADT 구현 • 큐의 구현: 1차원 배열 이용 • 변수 front는 큐에서 첫 원소의 위치보다 하나 작은 위치 • 변수 rear는 큐에서 마지막 원소의 위치 • Note: IsFullQ() 구현은 앞의 ADT 명세와 다름 • rear = MAX_QUEUE_SIZE-1이나 front > -1 이 될 수 있기 때문 (즉, 큐의 원소수가 MAX_QUEUE_SIZE 보다 작음) Queue CreateQ(max_queue_size) ::= #define MAX_QUEUE_SIZE 100 /* 큐의 최대 크기 */ typedef struct { int key; /* 다른 필드 */ } element; element queue[MAX_QUEUE_SIZE]; int rear = -1; /* 전역변수 */ int front = -1; Boolean IsEmptyQ(queue) ::= front == rear Boolean IsFullQ(queue) ::= rear == MAX_QUEUE_SIZE-1
큐(Queue) ADT 구현 • Add 및 Delete 연산 구현 void addq(element item) {/* queue에 item을 삽입 */ if (rear == MAX_QUEUE_SIZE-1) queueFull(); queue[++rear] = item; } 큐에서의 삽입 element deleteq() {/* queue의 앞에 있는 원소를 삭제 */ if (front == rear) return queueEmpty(); /* returns an error key */ return queue[++front]; } 큐에서의 삭제
큐(Queue) ADT 구현 • 큐의 순차적 표현의 문제점 • 예제 3.2 [작업 스케쥴링] • 운영체제의 작업 큐(job queue): FCFS 스케쥴링 • 작업들이 큐에 들어가고 나옴에 따라 큐는 점차 오른쪽으로 이동 결국 rear 값이 MAX_QUEUE_SIZE-1과 같아져서 큐가 포화 상태가 됨
큐(Queue) ADT 구현 • queueFull() • 첫째 원소가 queue[0]에 가도록 전체 큐의 데이터를 왼쪽으로 이동(shift) front를 -1로, rear 값도 조정 • 이러한 배열 이동에는 많은 시간이 소요됨 최악의 경우: O(MAX_QUEUE_SIZE) • 큐에 n개의 원소 J1,...,Jn이 있음 • 그 후 삽입과 삭제가 교대로 이루어짐 새 원소 삽입시마다 n-1개의 원소 가진 큐 전체 왼쪽 이동
원형 큐 (Circular Queue) • 순차적 큐의 문제 해결: 원형 큐 이용 • 배열 queue[MAX_QUEUE_SIZE]를 원형으로 취급 rear == MAX_QUEUE_SIZE-1이면, q[0]가 빈 경우 q[0]에 삽입 • 최대 원소 수: MAX_QUEUE_SIZE가 아니라 MAX_QUEUE_SIZE-1 front == rear일 경우, 포화상태인지 공백상태인지 구분하기 위해 하나의 공간은 항상 비워둠 rear rear rear C D C D C B B B A A front front front (a) 초기 (b) 삽입 (c) 삭제
원형 큐 (Circular Queue) • 초기상태: front = rear = 0 • 공백상태: front == rear • 포화상태: front =(rear+1) % MAX_QUEUE_SIZE 3 3 3 4 4 4 C D C D 2 2 2 5 5 5 B E B E F F A A 1 6 1 6 1 6 G G H 7 7 7 0 0 0 front front rear front rear rear (b) 포화상태 (c) 오류상태 (a) 공백상태
원형 큐 (Circular Queue) • 원형 큐 예 rear front rear front rear front rear front
원형 큐 (Circular Queue) • 원형 큐에 대한 삽입 연산 • rear 증가 (circular shift)if (rear == MAX_QUEUE_SIZE-1) k = 0;else k = rear+1; k =(rear+1) % MAX_QUEUE_SIZE와 동등 • 포화 상태 검사(front == k), 포화 아니면 새 원소 삽입 void addq(element item) { /* queue에 item을 삽입 */ rear = (rear+1) % MAX_QUEUE_SIZE; if (front == rear) queueFull(); /* 오류 출력 후종료 */ queue[rear] = item; }
원형 큐 (Circular Queue) • 원형 큐에 대한 삭제 연산 • 먼저 empty 테스트 (front == rear), • front 이동: front = ++front % MAX_QUEUE_SIZE void deleteq() { element item; /* queue의 front 원소를 삭제하여 그것을 item에 놓음 */ if (front == rear) return queueEmpty(); /* 오류 키를 반환 */ front = (front+1) % MAX_QUEUE_SIZE; return queue[front]; }
동적 할당 배열을 이용하는 원형 큐 • 동적 할당 배열 사용 • capacity : 배열 queue의 위치 번호 • 원소 삽입 시, 배열 크기 확장해야 함 • 함수 realloc • 배열 배가 방법 사용 queue [0] [1] [2] [3] [4] [5] [6] [7] D C C D E F G A B E B front = 5, rear = 4 (b) 포화된 원형 큐를 펼쳐 놓은 모양 F A G [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10][11][12][13][14][15] C D E F G A B front = 5, rear = 4 rear = 4 front = 5 (c) 배열을 두 배로 확장한 뒤의 모양 (realloc을 이용하여 확장) (a) 포화된 원형 큐
동적 할당 배열을 이용하는 원형 큐 최대 복사 원소 수 : 2*capacity-2 [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10][11][12][13][14][15] C D E F G A B front = 13, rear = 4 (d)세그먼트를 오른쪽으로 이동한 뒤의 모양 [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10][11][12][13][14][15] A B C D E F G front = 15, rear = 6 (e) 같은 내용의 다른 모양 • 최대 복사 원소 수 capacity-1로 제한 (1) 크기가 두배 되는 새로운 배열 newQueue를 생성한다. (2) 두번째 부분(즉, queue[front+1]과 queue[capacity-1] 사이에 있는 원소들)을 newQueue의 0에서부터 복사해 넣는다. (3) 첫번째 부분(즉 queue[0]와 queue[rear]사이에 있는 원소들)을 newQueue의 capacity-front-1에서부터 복사해 넣는다.
동적 할당 배열을 이용하는 원형 큐 void queueFull() { /* 2배 크기의 배열을 할당 */ element* newQueue; MALLOC(newQueue, 2*capacity*sizeof(*queue)); /* queue로부터 newQueue로 복사 */ int start = (front+1) % capacity; if (start < 2) /* 둘러싸지 않음 */ copy(queue+start, queue+start+capacity-1, newQueue); else /* 큐가 주변을 둘러쌈 */ copy(queue+start, queue+capacity, newQueue); copy(queue, queue+rear+1, newQueue+capacity-start); } /* newQueue로 전환 */ front = 2*capacity-1; rear = capacity-2; capacity *= 2; free(queue); queue = newQueue; }
add_rear add_front delete_rear delete_front get_front get_rear 전단(front) 후단(rear) 덱(deque) • double-ended queue • 큐의 전단(front)와 후단(rear)에서 모두 삽입과 삭제가 가능
덱(deque)의 연산 rear front rear front C A B D A add_front(dq, A) add_rear(dq, D) front rear rear front A B A B D add_rear(dq, B) delete_front(dq) rear rear front front A B C A B add_front(dq, C) delete_rear(dq)
큐의 응용: 버퍼(buffer) • 큐는 서로 다른 속도로 실행되는 두 프로세스 간의 상호 작용을 조화시키는 버퍼 역할을 담당 • CPU와 프린터 사이의 프린팅 버퍼, CPU와 키보드 사이의 키보드 버퍼 등 • 데이터를 생산하는 생산자 프로세스가 있고 데이터를 소비하는 소비자 프로세스가 있으며 이 사이에 큐로 구성되는 버퍼가 존재
큐의 응용: 시뮬레이션(simulation) • 큐잉 이론(queueing theory)에 따라 시스템의 특성을 시뮬레이션하여 분석하는 데 이용 • 큐잉 모델(queueing model)은 고객에 대한 서비스를 수행하는 서버와 서비스를 받는 고객들로 이루어진다 • 예 • 은행에서 고객이 들어와서 서비스를 받고 나가는 과정을 시뮬레이션 • 고객들이 기다리는 평균 대기 시간 등을 계산
스택 응용 1: 미로 탐색 • m x p 미로의 표현: 이차원 배열 maze[m+2][p+2] • 1 : 통로가 막혀 있음 • 0 : 통과할 수 있음 • 실제 미로의 길 위치 (i, j): 1im, 1jp 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 0 0 1 1 0 0 0 1 1 1 1 1 1 1 1 0 0 0 1 1 0 1 1 1 0 0 1 1 1 1 1 0 1 1 0 0 0 0 1 1 1 1 0 0 1 1 1 1 1 1 0 1 1 1 1 0 1 1 0 1 1 0 0 1 1 1 1 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 0 0 1 1 0 1 1 1 0 1 0 0 1 0 1 1 1 0 0 1 1 0 1 1 1 0 1 0 0 1 0 1 1 1 0 0 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 0 1 1 0 0 0 0 0 1 1 0 0 1 1 1 1 1 0 0 0 1 1 1 1 0 1 1 0 1 0 0 1 1 1 1 1 0 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 입구 출구 maze[m+2][p+2]
미로 탐색 • 현재의 위치 x : maze[i][j] 가능한 이동
미로 탐색 • 각 방향으로의 이동: move 배열 이용 typedef struct { short int vert; short int horiz; } offsets; offsetsmove[8]; /* 여덟 방향 이동에 대한 배열 */ maze[row][col]에서 dir 방향으로 이동시 다음 위치: maze[next_row][next_col], next_row = row + move[dir].vert; next_col = col + move[dir].horiz;
미로 탐색 • 경로 탐색 • 현위치를 저장 후 방향 선택 : N방향부터 시계 방향 순서대로 선택 • 잘못된 경로 선택 시, back-tracking 후 다음 방향 시도해야 함 • 위치 정보 저장 시 스택 이용 • 한 번 방문한 위치의 재방문 방지를 위해 보조 배열 mark[m+2][p+2] 이용 (bitmap) • 모든 값을 0으로 초기화 • maze[row][col] 방문 시 mark[row][col] = 1 로 변경 • 경로 유지 위한 스택 정의 #define MAX_STACK_SIZE 100 /* 스택의 최대 크기 */ typedef struct { short int row; short int col; short int dir; } element; elementstack[MAX_STACK_SIZE];
미로 탐색 • 미로 탐색 알고리즘 스택에 미로의 입구 좌표 저장, 방향(dir)은 N으로 초기화 while (stack is not empty) { /* 스택의 top에 있는 위치로 복귀 */ <rol, col, dir> = delete from top of stack; while (there are more moves from current position) { dir = next direction of move; <next_row, next_col> = coordinate of next move; if ((next_row == EXIT_ROW) && (next_col == EXIT_COL)) success; if (maze[next_row][next_col] == 0) && mark[next_row][next_col] == 0) { /* 가능하지만 아직 이동해보지 않은 이동 방향 */ mark[next_row][next_col] = 1; /* 현재의 위치와 그 위치에서의 다음 이동 방향을 저장 */ add <row, col, next_dir> to the top of the stack; row = next_row; col = next_col; dir = north; } } } printf("No path found\n");
입구 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 0 1 0 0 0 0 0 0 0 1 0 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 0 1 0 0 0 0 0 0 0 1 0 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 출구 미로 탐색 • 스택의 최대 크기 • 미로의 각 위치는 최대 한 번씩만 방문 (값이 0인 위치) • m × p maze 최대 mp개의 원소 긴 경로를 가진 미로
void path(void) { /* 미로를 통과하는 경로가 있으면 그 경로를 출력한다. */ int i, row, col, next_row, next_col, dir, found=FALSE; element position = { 1, 1, 0 }; mark[1][1]=1; top=-1; push(position); while (top>-1 && !found) { position = pop(); row = position.row;col = position.col; dir = position.dir; while (dir<8 && !found) { next_row = row + move[dir].vert; /* dir 방향으로 이동 */ next_col = col + move[dir].horiz; if (next_row==EXIT_ROW && next_col==EXIT_COL) found = TRUE; else if (!maze[next_row][next_col] && !mark[next_row][next_col]) { mark[next_row][next_col]= 1; position.row = row; position.col = col; position.dir = ++dir; push(position); row = next.row; col = next.col; dir = 0; } else dir++; } }
if (found) { printf("The path is:\n"); printf("row col\n"); for (i=0; i<=top; i++) printf("%2d%5d", stack[i].row, stack[i].col"); printf("%2d%5d\n", row, col); printf("%2d%5d\n", EXIT_ROW, EXIT_COL); } else printf("The maze does not have a path\n"); } • 시간 복잡도 • 미로의 각 위치는 최대 한 번씩만 방문 • 최악의 경우 연산시간 = O(mp)