Download
1 / 14
140 likes | 276 Views
Introdução a GPGPU. CUDA: arquitetura de computação paralela para GPGPU. Introdução a GPGPU. Por que CUDA? Desempenho versus custo NVIDIA é líder de mercado: mais de 10 8 GPUs Programação paralela para muitos Instalação de CUDA Driver CUDA toolkit (compilador e bibliotecas)

E N D
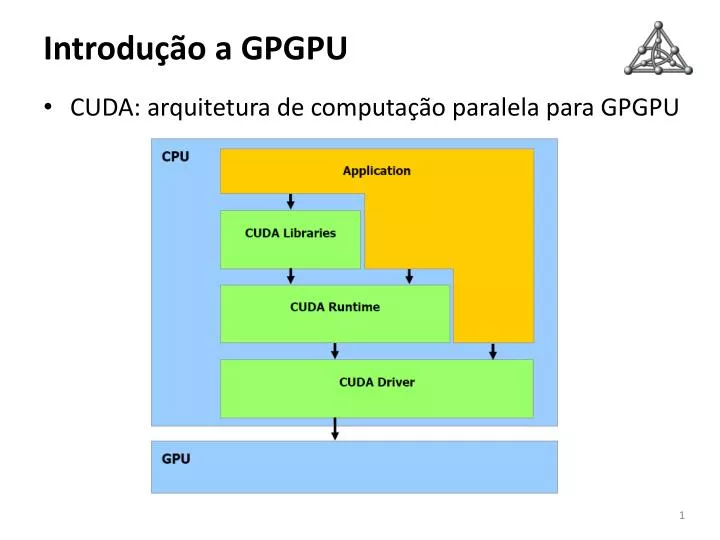
Introdução a GPGPU • CUDA: arquitetura de computação paralela para GPGPU
Introdução a GPGPU • Por que CUDA? • Desempenho versus custo • NVIDIA é líder de mercado: mais de 108 GPUs • Programação paralela para muitos • Instalação de CUDA • Driver • CUDA toolkit (compilador e bibliotecas) • CUDA SDK (utilitários e exemplos) • www.nvidia.com/object/cuda_get.html
Fundamentos de programação CUDA • Modelo de programação • Host: executa a aplicação (CPU) • Dispositivo (GPU) • Coprocessador da CPU • Executa kernels • Host e dispositivo tem DRAMs próprias • Host: • Aloca memória no dispositivo • Transfere dados de entrada para o dispositivo • Dispara a execução de kernels • Transfere dados resultantes do dispositivo • Libera memória no dispositivo
Fundamentos de programação CUDA • Modelo de programação • Kernel • Função geralmente escrita em C para CUDA • Executa no dispositivo N vezes em N threads em paralelo • Threads são organizadas em blocos • Um bloco é um arranjo 1D, 2D ou 3D de threads • Cada thread de um bloco tem um índice 1D, 2D ou 3D • Blocos são organizados em grids • Um grid é um arranjo 1D ou 2D de blocos • Cada bloco de um grid tem um índice 1D ou 2D • Os blocos de um grid têm o mesmo número de threads
Fundamentos de programação CUDA • Exemplo: kernel executando em 72 threads • Grid 2D com: • Dimensão 3×2×1 • 6 blocos • Blocos 2D com: • Dimensão 4×3×1 • 12 threads cada
Fundamentos de programação CUDA • Modelo de programação • Um kernel é uma função que: • Começa com o especificador __global__ • Tem tipo de retorno void • Kernels podem invocar outras funções que: • São especificadas como __device__ • Podem invocar outras especificadas como __device__ • Funções que executam no dispositivo: • Não admitem número variável de argumentos • Não admitem variáveis estáticas • Não admitem recursão • Não admitem variáveis do tipo endereço de função
Fundamentos de programação CUDA • Modelo de programação • Kernels são invocados do host • Um dispositivo executa um kernel de cada vez
Fundamentos de programação CUDA • Modelo de programação • Configuração de execução de um kernel • Dimensões do grid e dos blocos • Tamanho da memória compartilhada (opcional) • Especificada na invocação (ou lançamento) do kernel • Dimensão 3D é representada por objeto do tipo dim3 • Um grid: • 1D de dimensão dim3 dG tem dG.x × 1 × 1 blocos • 2D de dimensão dim3 dG tem dG.x × dG.y × 1 blocos • Um bloco: • 1D de dimensão dim3 dB tem dB.x × 1 × 1 threads • 2D de dimensão dim3dB tem dB.x × dB.y × 1 threads • 3D de dimensão dim3dB tem dB.x × dB.y × dB.z threads
Fundamentos de programação CUDA • Modelo de programação • Identificador global de uma thread • Pode ser usado para indexar vetores em funções __global__ou __device__ • Determinado a partir das variáveis pré-definidas: • dim3 gridDim • Dimensão do grid • dim3 blockDim • Dimensão do bloco • dim3 blockIdx • Índice do bloco no grid • dim3 threadIdx • Índice da thread no bloco
Fundamentos de programação CUDA • Modelo de programação • Hierarquia de memória acessada por uma thread • Memória compartilhada do bloco da thread • Visível para todas as threads do bloco • Tempo de vida do bloco • Memória local da thread • Memória global • Memória constante • Memória de textura Tempo de vida da aplicação Somente leitura
Fundamentos de programação CUDA • Modelo de programação • Capacidade de computação • 1.0 • 1.1 • 1.2 • 1.3 • Especificações: depende do dispositivo • Número de multiprocessadores e processadores • Dimensões de grids e blocos • DRAM • Memória compartilhada, etc.
Fundamentos de programação CUDA • Interface de programação • C para CUDA e API de runtime • API de driver • Ambas APIs têm funções para: • Gerência de memória no dispositivo • Transferência de dados entre host e dispositivo • Gerência de sistemas com vários dispositivos, etc. • API de runtime tem também funções para: • Gerenciamento de threads • Detecção de erros • Manual de referência de CUDA APIs exclusivas
Fundamentos de programação CUDA • Programa básico em C para CUDA • Seleção do dispositivo a ser usado • Alocação de memória no host • Dados de entrada na memória do host • Alocação de memória no dispositivo • Transferência de dados do host para dispositivo • Invocação do(s) kernel(s) • Transferência de dados do dispositivo para host • Liberação de memória no host • Liberação de memória no dispositivo • Finalização
Fundamentos de programação CUDA • Programa básico em C para CUDA • Seleção do dispositivo a ser usadocudaSetDevice() • Alocação de memória no dispositivocudaMalloc() • Transferência de dados entre host e dispositivocudaMemcpy() • Liberação de memória no dispositivocudaFree() • FinalizaçãocudaThreadExit()






















