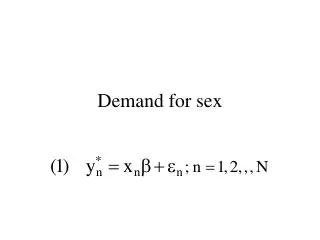Download

1 / 22
280 likes | 1.37k Views
משתנים מוסברים מוגבלים LPM, Probit, Logit. P ( y = 1| x ) = G ( b 0 + x b ). משתנים מוסברים מוגבלים (Limited Dependent Variables - LDV). משתנה מוסבר מוגבל מוגדר כמשתנה מוסבר שטווח ערכיו מוגבל באופן ניכר אחוז ההשתתפות בתוכנית הפרישה חסום בטווח בין 0 ל- 100%

E N D
משתנים מוסברים מוגבלים LPM, Probit, Logit P(y = 1|x) = G(b0 + xb)
משתנים מוסברים מוגבלים(Limited Dependent Variables - LDV) • משתנה מוסבר מוגבל מוגדר כמשתנה מוסבר שטווח ערכיו מוגבל באופן ניכר • אחוז ההשתתפות בתוכנית הפרישה חסום בטווח בין 0ל-100% • מספר הפעמים שפרט יכול להיעצר: 3,2,1,... • האם הפרט עישן מריחואנה או לא? (1 = כן, 0 = לא)
משתנים מוסברים מוגבלים, המשך • משתנים כלכליים רבים מוגבלים בצורה זו או אחרת, לעיתים קרובות בגלל שהם חייבים לקבל ערכים חיוביים בלבד • שכר • מחירי דיור • שערי ריבית נומינליים • כאשר משתנה שיכול להיות חיובי בלבד מקבל ערכים רבים, בדרך כלל אין צורך בהגדרת מודל אקונומטרי ספציפי
משתנים מוסברים בינאריים • משתנים מוסברים בינאריים בדרך כלל מקבלים ערכים1או0 • תחשבו על מודלLPMשניתן להציגו בצורה הבאה:P(y = 1|x) = b0 + xb • החיסרון של מודלLPMהוא בכך שערכי התחזית לא בהכרח נמצאים בתחום בין0ל-1 • החלופה היא לעצב את פונקצית ההסתברות כ-G(b0 + xb), כאשר0<G(z)<1
מודל Probit • אחת האפשרויות עבורG(z) הנה פונקצית התפלגות נורמלית מצטברת(cdf) • G(z) = F(z) ≡ ∫f(v)dv, כאשרf(z) פונקצית צפיפות נורמלית • f(z) = (2p)-1/2exp(-z2/2) • המקרה הזה מכונה מודל Probit • בחירת פונקציהGכהתפלגות נורמלית מצטברת מבטיחה ש-P(y=1|x) תמיד תימצא בטווח בין 0 ל-1 • מכיוון שהמודל איננו ליניארי, לא ניתן לאמוד אותו באמצעות השיטות הרגילות שהכרנו קודם. במקום, נשתמש בשיטת הנראות המכסימלית (maximum likelihood estimation)
מודל Logit • בחירה אחרת מקובלת עבורG(z) הנה פונקציה לוג'יסטית שמהווה פונקצית התפלגות מצטברת של משתנה מקרי בעל התפלגות לוג'יסטית סטנדרטית • G(z) = exp(z)/[1 + exp(z)] = L(z) • המקרה הזה מכונה מודל Logit או, לעיתים, נקרא רגרסיה לוג'יסטית • לשתי הפונקציות צורות דומות – שתיהן עולות ב-z, במהירות מרבית בסביבות0
מודלים Probit ו-Logit • הןprobitוהןlogitהנם מודלים לא ליניאריים ולכן דורשים אמידה בשיטת הנראות המכסימלית • אין סיבה להעדיף מודל אחד על פני השני • בעבר היינו רואים יותרlogit, בעיקר בגלל שפונקציה לוג'יסטית מובילה למודל שקל יותר לאמידה • נכון להיום, ניתן לאמוד בקלות מודלprobitבעזרת תוכנות סטטיסטיות סטנדרטיות, לכן מודל זה יותר פופולארי
פירוש התוצאות במודליםProbitו-Logit(לעומתLPM) • באופן כללי, אנו מעוניינים במדידת השפעה שלxעלP(y = 1|x) , כלומר מעניינת אותנו הנגזרת∂p/ ∂x • במקרה הליניארי (LPM), את ההשפעה הזו ניתן לחשב בקלות כמקדם שלx • P(y = 1|x1) = b0 + bx1ו-∂p/ ∂x =b • תניחו ש-b = .05 ו-x1הנו משתנה הנמדד ב-$. איך נוכל לפרש את משמעות המקדם שלx1?
פירוש התוצאות במודליםProbitו-Logit(משתנים רציפים) • במודלים לא ליניאריים מסוגprobitו-logitעם משתנים מסבירים רציפים: • ∂p(x)/ ∂xj = g(b0 +xb)bj,כאשר g(z) הוא dG/dz • הנגזרת הנ"ל מראה כי השפעה יחסית של כל זוג משתנים מסבירים רציפים אינו תלוי ב-x: יחס ההשפעות החלקיות שלxjו-xhשווה ל- • ∂p(x)/ ∂xj = g(b0 +xb)bj =bj ∂p(x)/ ∂xh g(b0 +xb)bhbh
פירוש התוצאות במודליםProbitו-Logit(משתנים מסבירים בינאריים) • תחשבו על הדוגמא בה אנו רוצים לאמוד השפעת תוכנית הכשרה על מצב תעסוקה (yהנו בינארי, שווה ל-1אם הפרט מועסק ו-0אחרת, ו-x = 1 אם הפרט השתתף בתוכנית הכשרה ו-0 אחרת). הערה: כרגע נתעלם מבעיית האנדוגניות בהשתתפות בתוכנית • במודל ליניארי מספיק לנו להסתכל על המקדם שלxכדי להעריך השפעת תוכנית ההכשרה • y = b0 + bx • במקרה שלprobitנצטרך לחשב • G(b0 + b) - G(b0) • מה פירוש התוצאה? • במקרה שלlogit נצטרך לחשב • exp(b0 + b)/[1+ exp(b0 + b)] - exp(b0)/[1+ exp(b0)] • מה פירוש התוצאה?
פירוש התוצאות, המשך • שימו לב שמספיק לדעת מהו סימן שלbכדי לדעת האם ההשפעה הנה חיובית או שלילית, אולם כדי לדעת עוצמת ההשפעה חייבים לעשות חישוב מדויק, כפי שהוצג בשקף הקודם • כשמשתנים מסבירים הנם רציפים, להשוואת עוצמת ההשפעות אנו חייבים לחשב את הנגזרות, לדוגמא בנקודת ממוצע הערכים • ברור שלא ניתן להשוות בין המקדמים שהתקבלו במודלים שונים (LPM, Logitו-Probit) • בכל זאת, ניתן להשוות בין הסימנים ורמת המובהקות (על סמך מבחןtסטנדרטי) של המקדמים • כלל אצבע להשוואת גובה המקדמים הוא לחלק אומדני probitב-2.5 ולחלק אומדני logitב-4 לשם השוואתם עם אומדניLPM
פירוש התוצאות, המשך • ההבדל העיקרי בין מודלLPMלמודלים logit/probitהוא בכך שמודלLPMמניח השפעה שולית קבועה, בזמן שמודליםlogit/probit לוקחים בחשבון ערכים ספציפיים של המשתנים המסבירים,x
אמידה בשיטת הנראות המכסימליתMaximum Likelihood Estimation(MLE) • מכיוון שהמודליםlogit/probitאינם ליניאריים, לא נוכל לאמוד אותם בשיטתOLS • הרעיון מאחורי שיטת האמידה של נראות מכסימלית הוא לספק שיטה לבחירת אומדנים יעילים אסימפטוטית עבור קבוצת פרמטרים
דוגמא אינטואיטיבית להמחשת שיטת הנראות המכסימלית* • נניח שיש לכם מטבע ואתם מעוניינים לאמוד את ההסתברות (נקרא לה“p”) לקבלת "ראש" בהטלה. אתם יודעים שההסתברות הזאת שווה ל-1/2 או ל-9/10. אתם מטילים מטבע 10 פעמים ומקבלים את התוצאה הבאה: רזרררזרזרר (כאשר "ר" מסמן "ראש" ו-"ז" מסמל "זנב", כלומר קיבלתם 7 פעמים ראש מתוך 10 הטלות). מהו אומדן נראות מכסימלית להסתברותp? *Credit to Daniele Passerman for this example
דוגמא אינטואיטיבית להמחשת שיטת הנראות המכסימלית, המשך • אם הערך האמיתי של pהוא 1/2, מהי הסתברות (או סבירות) לקבל אותה סדרה של תוצאות שראינו בדוגמא שנו? מהי סבירות במידה והערך האמיתי של p שווה ל-9/10? איזה ערך שלpסביר יותר לאור התוצאות התקבלו בניסוי? • החישוב פשוט: נצטרך להשתמש בנוסחה לחישוב ההסתברות לקבלת מספר נתון של הצלחות בסדרתnניסוייBernoulliעם הסתברות להצלחהpבכל ניסוי בודד. נסמן ב-y = 1קבלת הצלחה בניסויi,ו-0 אחרת.ההסתברות לקבלתkהצלחות היא:
דוגמא אינטואיטיבית להמחשת שיטת הנראות המכסימלית, המשך • נציב את המועמדים הפוטנציאליים שנו ונקבל:
דוגמא אינטואיטיבית להמחשת שיטת הנראות המכסימלית, המשך • מהחישוב עולה כי יש סבירות גבוהה יותר לכך ש- p = ½. זאת שיטת הנראות המכסימלית. • הדוגמא הפשוטה הנ"ל מראה מה נחוץ לנו לאמידה בשיטת הנראות המכסימלית: • פונקציה לקביעת ההסתברות לקבל אותה תוצאה שקיבלנו בפועל לערך נתון של הפרמטרים שאנו מעוניינים לאמוד • תחום הגדרה של הפרמטרים (הערכים הספציפיים, כמו 1/2 ו-9/10 בדוגמא שלנו) • כשיש לנו את זה, כל מה שנשאר לעשות זה לחשב את הערך שממכסם את פונקצית הנראות, בהינתן ערכי הפרמטרים
שיטת הנראות המכסימלית • נניח שיש לנו מדגם מקרי בגודלn. כדי לחשב אומדן הנראות המכסימלית, מותנה במשתנים המסבירים, אנו צריכים לדעת פונקצית צפיפות שלyiבהינתןxi: • f(y|xi;b) = [G(xi b)]y[1-G(xi b)]1-y, y = 0,1 • כאשרy = 1, נקבל • [G(xi b)] • כאשרy = 0, נקבל • [1-G(xi b)] • פונקצית לוג-נראות (log-likelihood function ) עבור תצפיתi, הנה פונקצית הפרמטרים והנתונים(xi ,y)שניתן לקבלה באמצעות חישוב הלוגריתם של הביטוי הבא: • li(b) = yilog[G(xi b)]+(1-yi)log[1- G(xi b)]
שיטת הנראות המכסימלית • מכיוון שפונקציהG(.)חסומה בין 0 ל-1 במודלים logit ו-probit, פונקציהli(b) מוגדרת היטב עבור כל הערכים שלb • פונקצית לוג נראות למדגם בגודלnמתקבלת כסכום של כל ערכי ה-li(b) עבור כל התצפיות במדגם: • L(b) = Σili(b) • אנו מוצאים את ה-bשממסמת את הפונקציה הנ"ל • Stata, דוגמא 8-1
מבחן יחס הנראות • להבדיל ממודלLPM, בו אנו יכולים לחשבFסטטיסטי אוLMסטטיסטי לבדיקת מגבלת ההשמטה, במודלים logitו-probitנצטרך סוג אחר של המבחן • באמידה בשיטת הנראות המכסימלית (MLE) תמיד נקבל פונקצית לוג-נראות,L. • מכיוון ששיטתMLEממקסמת פונקצית לוג-נראות, השמטת משתנים בדרך כלל גורמת לירידת ערך פונקצית לוג-נראות • בדיוק כמו במבחןFאתם חייבים לאמוד מודל שלם ומוגבל ולאחר מכן לחשב את הסטטיסטי לבדיקה • LR = 2(Lur – Lr) ~ c2q • ערך הסטטיסטי הזה תמיד יהיה חיובי • Stata, דוגמא 8-1, המשך
טיב ההתאמה • להבדיל ממודלLPM, בו אנו יכולים לחשבR2לבדיקת טיב ההתאמה, במודליםlogitו- probitנצטרך מדדים אחרים לבדיקת טיב התאמה • אחת האפשרויות למדד טיב ההתאמה הנוpseudo R2המבוסס על פונקצית לוג-נראות ומחושב כ-1 – Lur/Lr • נוכל גם לחשב מספר התחזיות המנובאות נכון • אם ההסתברות הצפויה גדולה מ-0.5, מתאים ל-y = 1ולהיפך • Stata, דוגמא 8-1, המשך