Download

1 / 27
270 likes | 410 Views
Parallel Data Cubing. Ben Holm Jagadeeshwaran Ranganathan Aric Schorr. The Reductionists. Agenda. Describe the computational problem you investigated. Summarize the major findings from your research paper analyses that you used in designing your programs.

E N D
Parallel Data Cubing Ben Holm Jagadeeshwaran Ranganathan Aric Schorr The Reductionists
Agenda • Describe the computational problem you investigated. • Summarize the major findings from your research paper analyses that you used in designing your programs. • Describe the sequential and parallel programs you developed, including a description of the software design. • Describe the performance metrics you measured for your parallel program. • Discuss what you learned from your investigation. • Discuss future work that could be done to further your investigation.
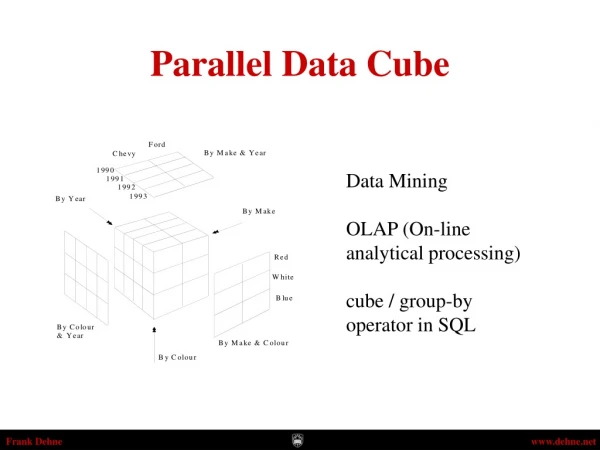
Data Cubing Overview • A database has many entries with many dimensions • A data cube consolidates the entries of a database by counting all possible combinations of every value for each column in a dataset • Goals are to parse and represent important data for analysis • Example data: • Sales statistics (dealerships, newegg, Amazon)
Example Data Set Data Cube grows exponentially with the number of dimensions
Summarize the major findings from your research paper analyses that you used in designing your programs. • Describe the sequential and parallel programs you developed, including a description of the software design. • Describe the performance metrics you measured for your parallel program. • Discuss what you learned from your investigation. • Discuss future work that could be done to further your investigation.
Major Paper Contributions • "Bottom-Up Computation of Sparse and Iceberg CUBES" • Explicitly described the algorithm for BUC algorithm • Explained how to prune work based on a minimum sum • "Iceberg-cube Computation with PC Clusters" • Explained several different parallel techniques • Described advantages and disadvantages of each • Implemented BPP algorithm
Describe the sequential and parallel programs you developed, including a description of the software design. • Describe the performance metrics you measured for your parallel program. • Discuss what you learned from your investigation. • Discuss future work that could be done to further your investigation.
Sequential Algorithm - BUC 1. BUC( input, dim ) 2. aggregate( input ) 3. if ( input.size == 1 ) writeAncestors( input, dim ) 4. writeOutputRec() 5. for( int d = dim to numDims ) 6. for( Partition p in PartitionSet( input, d ) 7. if( p.size > minsup ) 8. outputRec.filter[d] = partition.key 9. BottomUpCube( partition.data, d + 1 ) 10. outputRec.filter[d] = outputRec.ALL
Seq. Alg. Counting 1. BUC( input, dim ) 2. aggregate( input ) // Updates OutputRecord 3. if ( input.size == 1 ) writeAncestors( input, dim ) 4. writeOutputRec() 5. for( int d = dim to numDims ) 6. for( Partition p in PartitionSet( input, d ) 7. if( p.size > minsup ) 8. outputRec.filter[d] = partition.key 9. BottomUpCube( partition.data, d + 1 ) 10. outputRec.filter[d] = outputRec.ALL
Seq Alg. Iterating 1. BUC( input, dim ) 2. aggregate( input ) 3. if ( input.size == 1 ) writeAncestors( input, dim ) 4. writeOutputRec() 5. for( int d = dim to numDims ) 6. for( Partition p in PartitionSet( input, d ) 7. if( p.size > minsup ) 8. outputRec.filter[d] = partition.key 9. BottomUpCube( partition.data, d + 1 ) 10. outputRec.filter[d] = outputRec.ALL
Seq Alg Recursing 1. BUC( input, dim ) 2. aggregate( input ) 3. if ( input.size == 1 ) writeAncestors( input, dim ) 4. writeOutputRec() 5. for( int d = dim to numDims ) 6. for( Partition p in PartitionSet( input, d ) 7. if( p.size > minsup ) 8. outputRec.filter[d] = partition.key 9. BottomUpCube( partition.data, d + 1 ) 10. outputRec.filter[d] = outputRec.ALL
Parallel Algorithm - BPP 1. CUBE_COMPUTATION( input ) 2. BPP_BUC( input, rank, empty_prefix ); 1. BPP_BUC( input, dim, prefix ) 2. prefix += input[ rank ]; 3. sort( input ) // sorted according to prefix 4. sorted = input 5. for combo in combinations( sorted, prefix ) 6. if( combo.count >= minsup ) 7. aggregateAndWrite( combo, prefix ) 8. else removeCombo( combo, sorted ) 9. for d from dim to numDims 10. BPP_BUC( sorted, d, prefix )
Par. Alg. - Parallelization 1. CUBE_COMPUTATION( input ) 2. BPP_BUC( input, rank, empty_prefix );
Par. Alg. - Prefix and Sorting [ "*", "*", ".", ".", "*" ] 1. BPP_BUC( input, dim, prefix ) 2. prefix += input[ rank ] 3. sort( input ) // sorted according to prefix 4. sorted = input 5. for combo in combinations( sorted, prefix ) 6. if( combo.count >= minsup ) 7. aggregateAndWrite( combo, prefix ) 8. else removeCombo( combo, sorted ) 9. for d from dim to numDims 10. BPP_BUC( sorted, d, prefix )
Par. Alg. - Partitioning . . . again! 1. BPP_BUC( input, dim, prefix ) 2. prefix += input[ rank ] 3. sort( input ) // sorted according to prefix 4. sorted = input 5. for combo in combinations( sorted, prefix ) 6. if( combo.count >= minsup ) 7. aggregateAndWrite( combo, prefix ) 8. else removeCombo( combo, sorted ) 9. for d from dim to numDims 10. BPP_BUC( sorted, d, prefix )
Par. Alg. - Recursive step 1. BPP_BUC( input, dim, prefix ) 2. prefix += input[ rank ]; 3. sort( input ) // sorted according to prefix 4. sorted = input 5. for combo in combinations( sorted, prefix ) 6. if( combo.count >= minsup ) 7. aggregateAndWrite( combo, prefix ) 8. else removeCombo( combo, sorted ) 9. for d from dim to numDims 10. BPP_BUC( sorted, d, prefix )
Describe the performance metrics you measured for your parallel program. • Discuss what you learned from your investigation. • Discuss future work that could be done to further your investigation.
Data Description User data from Bookmooch.com - a free book trading website. A user has: - user name - active (is this user active) - points (number of points user has) - country (the country the user lives in) - zip (user's zip code) - willsend (where will the user send books) The data set from Bookmooch contained 100,000 users (about 4GB of xml which was trimmed and chopped down to 4MB csv file)
Numerical Measurements Entries S_MS1 P_MS1 S_MS3 P_MS3 S_MS5 P_MS5 S_MS:Sequential with Minsup P_MS:Parallel with Minsup No.of Processors used for parallel version:5
Graphical measurement X-axis time(msec) Yaxis entries
Towards Final Report • The Efficiency is higher than they should be because the cluster algorithm (BPP-BUC) was optimized before parallelization. • More aggressive trimming of data • The initial, sequential algorithm was naive in some implementation details, despite its revolutionary approach.
bash-2.05$ /usr/jdk/jdk1.5.0_17/bin/java -Dpj.np=5 IcebergClu 1 users.csv op.csv • Job 1144, thug29, thug30, thug31, thug32, thug01 • 6677ms • 8296ms • 11152ms • 65049ms • 124702ms • The BPP-BUC algorithm is not load balanced. Some processors finish well before others. • The Partitioned Tree algorithm uses BPP-BUC inside a load balancing / scaling algorithm to address this problem
Discuss future work that could be done to further your investigation.
Future work • Implement a load balancing algorithm (Partitioned Tree) on top of BPP. • This will allow easier scaling across a variable number of processors. • Implement various sorting algorithm based on specific attributes of the data. • Test with other databases and correct data-specific code • Implement other cubing algorithms. Real world applications choose between several cubing algorithms during data processing