Download

1 / 27
270 likes | 389 Views
PostgreSQL Enhancement. PopSQL Daniel Basilio, Eril Berkok Julia Canella, Mark Fischer Misiu Godfrey, Andrew Heard. Presentation Overview. Problem Enhancement Implications of our proposal SAAM Analysis Chosen Approach Alternate Approach Use Case Concurrency and Team Issues

E N D
PostgreSQL Enhancement PopSQL Daniel Basilio, Eril Berkok Julia Canella, Mark Fischer Misiu Godfrey, Andrew Heard
Presentation Overview • Problem • Enhancement • Implications of our proposal • SAAM Analysis • Chosen Approach • Alternate Approach • Use Case • Concurrency and Team Issues • Testing Impact • Lessons Learned • Limitations • Conclusion
Enhancement: The Problem • A commonly referenced problem of PostgreSQL is its limited scalability • Because the postmaster MUST be on the same machine as all back end instances, PostgreSQL cannot scale out back end instance processing. Currently, the only solution is to scale up. • This limits the amount of users who can connect to a PostgreSQL database at any given time.
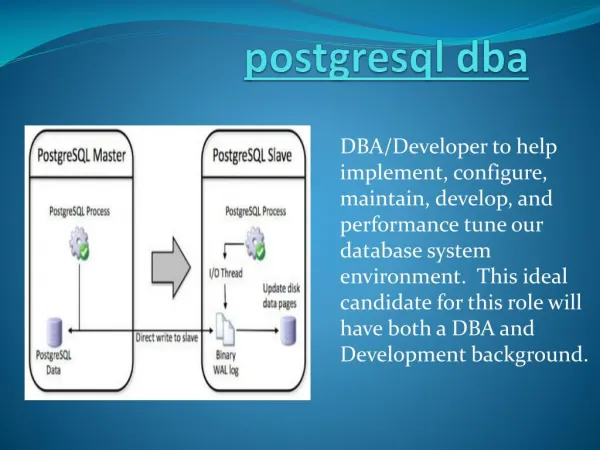
Enhancement: The Solution • PostgreSQL already allows data to be spread out over machines. This functionality is controlled primarily by the access subsystem. • Our idea: Allow postgreSQL to distribute query processing across multiple machines. • Because every machine needs to access the same data, act on the same table locks, and return the same results - several changes will have to be made to the PostgreSQL architecture
Enhancement: Implications • In order to realize our enhancement, several changes need to be made to the existing architecture, primarily: • The Client Communications Manager and Server Process subsystems needs to be able to remotely create Backend Instances and connect the client to remote machines • The Data Control subsystem needs to be replicated through all machines with processing capabilities, and kept up to date, so that all machines know where the data are
New Conceptual Architecture Diagram 1: New Conceptual Architecture
Changes to Postmaster • After implementing our enhancement, there are two cases the postmaster must consider: • If the backend instance is created on the same machine as the postmaster, then nothing changes. • If the backend instance is created on a new machine, then the postmaster has to forward new connection information to the client so that they can re-connect to a new machine • How does the postmaster know where to create new backend instances? Answer: Load Balancing
Load Balancer Subsystem • A new subsystem designed to balance the clients and workload assigned to each machine • The Load Balancer receives CPU usage stats from each machine (generated within the new Data Sync Subsystem within Database Control) periodically so it is aware of the state each machine is in • The Load Balancer will replace the Postmaster in talking to the client. When connected to, it chooses the machine with the smallest CPU usage and tells that machine to create a new Backend Instance. It then forwards contact information back to the client and disconnects.
Load Balancer and Creating a New Backend Instance Diagram 2: Shows the data flow amongst the Load Balancer and the Server Processes scaled out on different machines
CPU Maxing Issues • If a machine's CPU consumption reaches its configured maximum, it will not be given new clients by the Load Balancer. • Machines which are being used more heavily than first assumed, can put in a request with the Load Balencer to have one of its current users re-connect to another machine. This request is activated by the Data Synchronization subsystem. • Requests are granted or denied depending on the number of other machines and their respective workloads.
What happens if a machine dies? • If a machine dies the Load Balancer will not receive the CPU usage stats from the machine. • It will then know that the machine has died and needs to be fixed and that no new clients should be directed there • This works if the machine is dedicated only to processing • If the machine holds necessary storage data, other machines will be unable to access it and will return a server error • If the central server machine (the initial point of access) dies, the system, like the pre-enhancement system, will not be able to receive any connections.
The States of a Machine Diagram 3: The states of a machine
First Approach: Forward Pointers • As an alternative to the bulletin board, it was proposed that if a machine did not know where certain data live, it would instead ask its neighbor, who would perform the same process • This system avoids the use of shared memory, but has the "worst case scenario" of a machine needing to query every other machine before it can update its map of the data system. • This could cause significant time lag and it was decided that a small portion of shared memory would be necessary • Doesn't include a convenient way to implement synchronized statistics.
Advantages/Disadvantages Performance - Worst case: if the data do not exist will go through every machine. Very slow. Reliability - Load Balancer will prevent machines from overloading Scalability - Splitting Backend Instances from Postmaster onto different machines allows horizontal scaling out. No shared memory. Manageability - Troubleshooting becomes more difficult as more machines add complexity Security - Still only one point of entry to system Affordability - Ease to implement forward pointing Access Managers
Chosen Approach: Bulletin Board Subsystem • The bulletin board subsystem is a repository that maintains a listing of all data locations, updates statistical changes. • When a machine creates a new table, or shifts a data location, it posts an update on the bulletin board for all machines to see. • When each machine gets an update from the board, it will increment a counter. • When all computers have checked an update it can be removed from the bulletin board, minimizing its size. • Computers will poll the bulletin board at fixed intervals to remain up to date. • Also, if a computer does not know the location of a piece of data it will check the bulletin board before determining that it does not exist.
Advantages/Disadvantages Performance - Worst case only has to check Bulletin Board Reliability - Load Balancer will prevent machines from overloading Scalability - Splitting Backend Instances from Postmaster onto different machines allows horizontal scaling out. Bulletin Board still has to be scaled up, but it is comparatively small Manageability - Troubleshooting becomes more difficult as more machines add complexity Security - Still only one point of entry to system Affordability - Difficult to implement repository style of Bulletin Board
Changes to Access Control • If all Backend Instances over multiple machines tried to contact a central Access Manager a bottleneck would occur on the machine • so each machine will have its own Access Manager that has control over the data on that machine • If a different Access Manager needs to access data on a different machine, must talk to that machine's Access Manager • therefore all Access Managers must be able to communicate with each other
Data Synchronization Subsystem • New subsystem in charge of maintaining synchronized data • Maintains tables of where data live • One Data Sync subsystem will contain the bulletin board for data updates between Access Managers and every Data Sync subsystem will be able to consult that bulletin board • Updates statistics and keeps tables up to date • Since locks are maintained by whichever machine the retrieved data is sitting on, this subsystem does not have to worry about the current lock-state of data in the system
Access Control Diagram 4: Shows the data flow within the Database Control subsystem and the connection between Access Managers on different machines
Concurrency Issues • Concurrency issues were solved in the original PostgreSQL by using MVCC and the lock manager • The main reason to have the accesses talk to each other is that if a piece of data is locked by its local access (whether because that machine or others are using it) then other's cannot also use it, which keeps MVCC and locks as they currently are. • This adds no new concurrency issues to PostgreSQL
Team Issues • Team issues are handled primarily by seperation of functionality such that different developers can change functionality without effecting changes elsewhere. • Since the Access subsystem already acts as a facade for the backend processes, our changes to Access should not affect other subsystems. • Because separation of functionality is maintained, team issues after our improvement is implemented should remain the same as they were before.
Use Case Diagram 5: Establishing connecting between user and Backend Instance
Testing impact of enhancement with other features • Regression Testing is required to test that nothing has been broken and no integration problems have occured • Stress test to see if the Load Balancer actually works in preventing overloaded machines • Test that the Access Manager can handle finding data that is not on its own machine by referring to the Bulletin Board.
Lessons Learned • There are many different ways to architecturally implement one change • Worst case scenarios for implementations must be considered • Choosing an exact implementation took a while since so many possibilities and trade offs between performance and ease of implementation had to be considered • Effective distribution is difficult to build into a legacy system and should typically be planned from the start
Limitations • Difficult to know if new implementation will cause integration issues among subsystems • Had to assume systems could have certain functionality, for example: Access Manager subsystems could talk to each other across machines • Objects such as the Bulletin Board and Load Balancer will still need to scale up as the project scales out because they contain an amount of information proportional to the amount of machines in the system
Conclusions • High level ideas for Implementation developed quickly but deciding on low level implementation proved to be more difficult • The performance of the system proved to be the largest differentiator between the two implementations we chose between • This improvement will be invaluable to PostgreSQL users because the system will now be able to scale to handle extremely large loads