Download

1 / 9
90 likes | 370 Views
Edit and Imputation o f the 2011 Abu Dhabi Census Glenn Hui and Hanan AlDarmaki Statistics Centre - Abu Dhabi. UNECE CES Work Session on Statistical Data Editing (Oslo, Norway, 26 September 2012). Outline. Census Overview Edit and Imputation Methodologies

E N D
Edit and Imputation of the 2011 Abu Dhabi Census Glenn Hui and Hanan AlDarmaki Statistics Centre - Abu Dhabi • UNECE CES • Work Session on Statistical Data Editing • (Oslo, Norway, 26 September 2012)
Outline • Census Overview • Edit and Imputation Methodologies • Societal Differences and Challenges • Performance Analysis • Data Editing in the 2005 Census • Conclusions
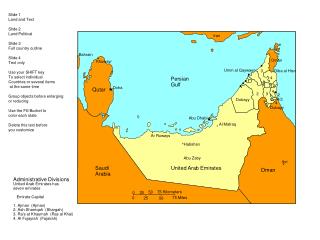
2011 Abu Dhabi Census Overview • First census conducted by SCAD • Main collection via CAPI, October 2011 • 20 questions • Three methodologies used for edit and imputation, each with its own purpose: • Donor • Deterministic • Manual
Edit and Imputation Methodologies • Donor Imputation • Canadian Census Edit and Imputation Systemv4.5 (CANCEIS) hot deck module • Substitutes invalid value with value from “donor” record • Deterministic Imputation • Correct data via hard-coded rules (SAS) • Applied mostly for out-of-scope responses • Manual Imputation • Manually check and modify data. • Difficult cases like very large households.
Societal and Cultural Differences • Very large household sizes: ~5 persons average • Contrast to typical ~2.5 averages in Western countries • Error rates increase with family size; used less exacting DLTs to account for this • Households of 17+ treated as individual records, with some manual imputation as well
Societal Differences continued • Complex relationships in large households • Extended families • High proportion of household servants • Multiple wives – special consistency rules required • Large Expatriate Population • Many live in shared living arrangements • Significant portion live in employer-provided camps • Shares and collectives treated as 1-person households
Imputation Performance • Test Data: Starting with clean data, introduced two types of errors: missing data and “interchange” errors. • Most performance measures from Euredit project (Charlton, 2003) • Example Statistics • Predictive Accuracy: R2 generated by regressing true on imputed values, used to assess predictive ability. • Estimation Accuracy: Difference in means of true and imputed values, m1, used to assess aggregate imputation accuracy. • Imputation performance for Age Charlton, J. C. (2003).“Evaluating New Methods for Data Editing and Imputation - Results from the Euredit Project”, UNECE Statistical Data Editing Work session. Madrid, Spain.
Data Editing in the 2005 Census • 2005: Manual and Deterministic imputation • Phase 1: validation edits, outlier detection via SQL • Small subset imputed via deterministic imputation • Phase 2: Most failed records corrected manually • Comparison to 2011 • 2005 performance unknown • 2005: Three methodologists, several months’ preparation • 15 data clerks, 4+ months • 2011: Two methodologists, 5 months total
Conclusions • Modern edit and imputation methodology successfully applied in distinct cultural context • Reliable results • Measurable changes • More efficient approach • Special thanks to CANCEIS E&I unit, Statistics Canada