Download

1 / 16
160 likes | 184 Views
Explore challenges, basics, architecture, problems, and solutions of distributed crossbar scheduling in the OSMOSIS overview. Learn about the bipartite graph matching algorithm, pointer-based parallel iterative matching, and coping with uncertainty.

E N D
Distributed Crossbar Schedulers Cyriel Minkenberg1, Francois Abel1, Enrico Schiattarella2 1 IBM Research, Zurich Research Laboratory 2 Dipartimento di Elettronica, Politecnico di Torino
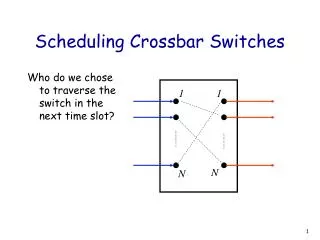
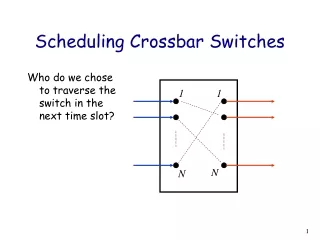
Outline • OSMOSIS overview • Challenges in the OSMOSIS scheduler design • Basics of crossbar scheduling • Distributed scheduler • Architecture • Problems • Solutions • Results • Implementation
VOQs Com- biner Tx 2 Rx EQ 8x1 1x8 8x1 control WDM Mux Star Coupler control OpticalAmplifier 8x1 1x128 2 Rx EQ control all-optical packet transfer 5 4b SOA switch command packet waiting 1 central scheduler (BGM) 3 request 2 grant 4a OSMOSIS Overview All-optical Switch 64 Ingress Adapters 64 Egress Adapters • 64 ports @ 40 Gb/s, 256-byte cells => 51.2 ns time slot • Broadcast-and-select architecture (crossbar) • Combination of wavelength- and space-division multiplexing • Fast switching based on SOAs • Electronic input and output adapters, electronic arbitration 8 Broadcast Units 128 Select Units 1 1 1 Fast SOA 1x8 Fiber Selector Gates Fast SOA 1x8 Wavelength Selector Gates VOQs 1 Tx 128 8 control 64 64 control links central scheduler (bipartite graph matching algorithm)
Architectural Scheduler Challenges • Latency < 1 ls • Pr: Long permission latency (RTT + scheduling) • So: Speculation • Multicast support • Pr: Fair integration with unicast scheduling, control channel overhead • So: Independent schedulers with filter, merge & feedback scheme • Scheduling rate = cell rate • Pr: Produce one high quality matching every 51.2 ns • So: Deeply pipelined matching with parallel sub-schedulers (FLPPR) • FPGA-only scheduler implementation • Pr: Does a 64-port scheduler fit in one FPGA device? • If not, how do we distribute it over multiple devices while maintaining an acceptable level of performance?
maximal, size=3 inputs outputs maximum, size=4 maximal, size=2 inputs inputs outputs outputs Crossbar Scheduling: Bipartite Graph Matching • A crossbar is a non-blocking fabric that can transfer cells from any input to any output with the following constraints: • At most one cell from any input • At most one cell to any output • Equivalent to Bipartite Graph Matching (BGM) request matrix inputs outputs
Pointer-based Parallel Iterative Matching • One matching must be computed in every time slot, so we need fast and simple algorithms • Suitable class of algorithms is parallel, iterative, and based on round-robin pointers • i-SLIP (McKeown), DRRM (Chao) • These algorithms have a number of desirable features: • 100% throughput under uniform i.i.d. traffic • Starvation-free: any VOQ is served within finite time under any traffic pattern • Iterative: sequential improvement of the matching by repeating steps • Amenable to fast hardware implementation; high degree of parallelism and symmetry
DRRM Operation VOQ state input selectors output selectors • Step 0: Initially, all inputs and outputs are unmatched • Step 1: Each unmatched input requests the first unmatched output in round-robin order for which it has a packet, starting from pointer R[i]. R[i] (R[i] + 1) modulo N iff the request is granted in Step 2 of the first iteration • Step 2: Each output grants the first input in round-robin order that has requested it, starting from pointer G[o]. G[o] (G[o] + 1) modulo N • Iterate: Repeat Steps 1 and 2 until no more edges can be added or a fixed number of iterations are completed • Key to good performance is pointer desynchronization • If all VOQs are non-empty, pointers eventually all point to different outputs • No conflicts: maximum performance IS[1] OS[1] IS[2] OS[2] IS[3] OS[3] IS[4] OS[4]
Distribution Issues • Problem: Scheduler does not fit in a single device due to area constraints • Quadratic complexity growth of priority encoders • Monolithic implementation (implicit temporal and spatial assumptions) • All results are available before the next time slot (or iteration) • All required information is available to all selectors • Distributed implementation breaks these assumptions • Main problem: input selector issues a request at t0 and receives result (granted or not) at t0 + RTT • Input selector does not know results of requests issued during last RTT • Selectors are only aware of local status info (e.g. matches made in previous iterations) • The time required for information to travel from the inputs to the outputs and back is called round-trip time (RTT) • = RTT / (cell duration) input status update and selection IS[1] IS[N] request RTT RTT >> cell duration grant OS[1] OS[N] output selection and status update time
Coping with Uncertainty (1) • Problem: Uncertainty in the algorithm’s status • The pointer-update mechanism breaks • No desynchronization Throughput loss • Solution: Maintain a separate pointer set for each time slot in the RTT • Basic idea: No pointer is reused before the last result is available • Each input (output) selector maintains distinct request (grant) pointers, labeled R[ t ] and G[ t ], with t [0, -1] • At time slot t the input selectors use set R[t mod ] to generate requests; each request carries the ID of pointer set used • Output selectors generate grants using G[ t ] in response to requests from R[ t ] • Each pointer set is updated independently from the others, so they all desynchronize independently. Therefore, all the good features DRRM are preserved • Pointer sets are only updated once every RTT, hence they take longer to desynchronize
Coping with Uncertainty (2) • Problem: Uncertainty in the algorithm’s status • The VOQ-state update mechanism breaks • How many requests were successful? • Excess requests may lead to “wasted” grants, leading to reduced performance • Solution: Maintain a pending request counter for every VOQ • P(i,j) tracks the number of requests issued for VOQ(i,j) over the last RTT • Increment when issuing new request • Decrement when result arrives • Filter requests: if P(i,j) exceeds the number of unserved cells in VOQ(i,j) do not submit further requests • This massively reduces the number of wasted grants
R[t0;1] R[t3;1] R[t0;3] R[t1;2] G[t0;4] R[t1;2] R[t2;2] R[t3;2] G[t0;3] R[t1;2] R[t2;2] R[t3;2] R[t1;2] G[t0;2] R[t2;2] R[t3;2] R[t0;4] R[t1;2] R[t2;2] R[t3;2] R[t2;2] R[t1;2] R[t0;2] R[t3;2] R[t2;2] R[t3;2] R[t1;1] R[t2;1] Multi-pointer Approach (RTT = 4) pending request counters 1 1 VOQ state 2 1 • Hardware cost • ( -1) additional pointers at each input/output, each log2N bits wide • N2 pending request counters • N-to-1 multiplexers • Selection logic is not duplicated 0 0 0 0 G[t0;1] IS[1] OS[1] G[t1;1] G[t2;1] G[t3;1] IS[2] OS[2] request pointer set grant pointer set IS[3] OS[3] IS[4] OS[4] request pointers input selectors output selectors grant pointers
Multiple Iterations • Additional uncertainty: Which inputs/outputs have been matched in previous iterations? • Inputs should not request outputs that are already taken: Wasted requests • Outputs should not grant inputs that are already taken: Violation of one-to-one matching property • Because of issue 2 above, the output selectors must be aware of all grants in previous iterations, also by other selectors • Implement all output selectors in one device • Input selectors use a request flywheel pointer to create request diversity across multiple iterations • PRC filtering applies only to first iteration • Can lead to “premature” grants
Distributed Scheduler Architecture VOQ state input selectors output selectors switch command channels IS[1] OS[1] control channel IS[2] OS[2] control channel Control channel interfaces (each on a separate card) Allocators (on midplane) IS[3] OS[3] control channel IS[4] OS[4] control channel
Optical Switch Controller Module (OSCM) Midplane (OSCB; prototype shown here) with 40 daughter boards (OSCI; top right). Board layout (bottom right)