Download

1 / 11
110 likes | 296 Views
Lecture 5 slides on Central Limit Theorem Stratified Sampling How to acquire random sample Prepared by Amrita Tamrakar. Central Limit Theorem. Assume a given population of numbers P={ x 1 ,x 2 ,…….infinity}. x i x j. Let x p = average of P, σ p = variance of P,

E N D
Lecture 5 slides on • Central Limit Theorem • Stratified Sampling • How to acquire random sample • Prepared by • Amrita Tamrakar
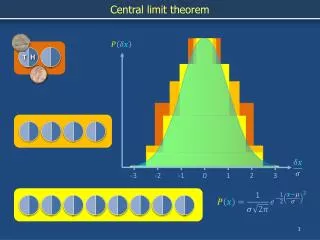
Central Limit Theorem Assume a given population of numbers P={ x1,x2,…….infinity} xi xj
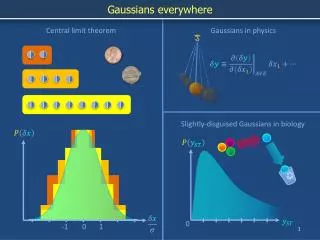
Let xp= average of P, σp= variance of P, • k = tuples from sample, µs= average of sample. • Does µsremain fixed? • Standard Error formula says, E(µs) = xp • If σs= variance of the average of sample then E(µs) = xp σs2= σp2 / k Interesting phenomenon If we plot µ, it is not going to be skewed but give a bell curve even though the actual population may be any distribution.
The Central limit theorem says: As we repeat sampling random distribution, the randomness disappears and gets a bell shaped curve which gets tighter as we proceed. Skewed Distribution of salary 200k 0k 40k Plot µ x = exact avg
Our main objective is Not to reduce the error but to give exact error interval. Hence we need to find the variance. There are two options to find variance σp 1) Use a materialized view with an extra column e.g.. 0 for females, 1 for males 2) Calculate the sample variance many times to get an unbiased original variance .i.e. Use sample variance as a surrogate of original variance. Which one will be better?
Error Interval with Confidence level • To give the error interval with 95% confidence. • Find a point d which will give an area=0.95 from the curve, then x±d will be the error with 95% confidence ∫ =1 Area=0.95 x-d x x+d Alternatively, to find out d we can calculate 1.96*sd Where standard deviation (sd)=σp /√ k http://www.math.duke.edu/~wka/math135/confidence.pdf
Stratified Sampling Will stratification of salary give a more accurate results? Population P broken into r strata (P1…Pr ) : Sample Mean σ1 Sample Size k1 P1 σ2 k2 P2 σr kr Pr 200k 0 k N1 50k N2 100k Nr Technique to stratify is to minimize variance in each strata.
Total sample = k1+k2+……+kr Mean of sample µs= • Challenges : • Stratification : How to break into strata • Allocation : How many samples from 1st group, 2nd group…….? i.e. how to allocate samples 0k 30k 40k 70k In this graph, can we say get more samples from 30-70k range (allocation strategy) ?
How data is organized in database? • in disc blocks • To read a single record , need to read the entire disc block • Clustered index , B+ tree are some of the indexing techniques. • Two approaches for sampling • Online sampling • Offline sampling also called pre-computed sampling
Effects : • Online sampling costly in-terms of response time. • Offline sampling can be done during pre-processing time. • Reuse the sample again. • How to get sample data : • Generate a random number between 0-106 and pull out the record with that record id. • OR • Bernoulli's theorem : • Go to each record • Toss a coin • If head then pull out the record, else leave it. • Note: May not get the exact sample size
How to maintain freshness of data in random sample via offline method? • Doesn’t matter much as they are done for history data • What if the original query changes? May be it was directed towards particular field only.. • Generate the random sample again as it doesn’t matter much towards the performance since it is pre-processed. • E.g. generate once in 3 months. • Oracle, sqlserver are having the random sampling functionality added in their newer versions.