Download

1 / 116
1.17k likes | 1.32k Views
Workbook 10 Network Applications. Pace Center for Business and Technology. Chapter 1. An Introduction to TCP/IP Networking. Key Concepts Most Linux networking services are designed around a client-server relationship.

E N D
Workbook 10Network Applications Pace Center for Business and Technology
Chapter 1. An Introduction to TCP/IP Networking Key Concepts • Most Linux networking services are designed around a client-server relationship. • Network server applications are generally designed to be "always running", starting automatically as a system boots, and only shutting down when the system does. Generally, only the root user may manage server processes. • Network client applications are generally running only when in use, and may be started by any user. • Most Linux network servers and clients communicate using the TCP/IP protocol. • The TCP/IP address of both the client process and the server process consists of an IP address and a port. • Network servers usually use assigned, "well known" ports, as cataloged in the /etc/services file. Network clients generally use randomly assigned ports. Often, well know ports reside in the range of privileged ports, below port number 1024. • The hostname command can be to examine a machine's current IP address, while the netstat -tuna command can be used to examine all open ports.
Clients, Servers, and the TCP/IP Protocol Most networking applications today are designed around a client-server relationship. The networking client is usually an application acting on behalf of a person trying to accomplish a particular task, such as a web browser accessing a URL, or the rdate command asking a time server for the current time. The networking server is generally an application that is providing some service, such as supplying the content of web pages, or supplying the current time. The design of (applications acting as) network clients and (applications acting as) network servers differs dramatically. In order to appreciate the differences, we will compare them to the agents in a more familiar client-server relationship, a customer buying a candybar from a salesperson.
The Server Servers are Highly Available Just as a salesperson must always be running the register, even when customers are not around, processes implementing networking services need to be running, ready to supply services upon request. Usually, processes implementing network services are started at boottime, and continue to run until the machine is shutdown. In Linux (and Unix), such processes are often referred to as daemons. Generally, only the root user may start or shutdown processes acting as network servers. Servers have Well Known Locations In addition to being available when a customer wants service, salespeople stay where they know customers can find them. Just as customers can look up the locations of unfamiliar candybar salesmen in telephone books and find them by street address, networking clients can look up the locations of unfamiliar network servers using a hostname, which is converted into the IP Address used to access the service.
The Server The Client In contrast, the candybar customer needs to be neither highly available nor well known. A customer doesn't hang around a store from dawn until dusk just in case he decides he wants a candybar. Likewise, clients generally do not need to to stay at well known locations. Our customer doesn't stay at home all day, just in case somebody wants to come by to sell him a candybar. Processes that implement network clients are started by normal users, and generally are only running as long a necessary to complete a task. When someone breaks for lunch, he closes his web browser. Also, client applications do not need to have fixed addresses, but can move from place to place. More on this next.
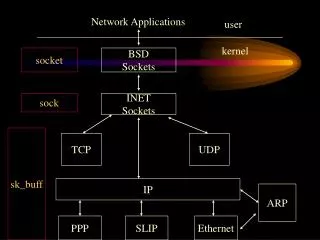
The Server TCP/IP Addresses Every process which is participating in a TCP/IP conversation must have an IP Address, just as every participant in a phone conversation must have a phone number. Additionally, every process in a TCP/IP conversation must have port number, whose closest analogy might be a telephone extension associated with a phone number. Computers on a network are identified by IP address. The IP address comes in the form of four integers, each ranging from 0 to 255 (not coincidentally, the amount of information that can be encoded in one byte of memory), and traditionally written separated by periods, such as 192.168.0.3. This representation is often informally referred to as a dotted quad. Processes on computers are identified by a port number, which is an integer ranging from 1 to 65535 (not coincidentally, the amount of information that can be encoded in two bytes of memory). Whenever a process wants to participate in a TCP/IP conversation with another process, it must first be assigned a port number by the kernel. The TCP/IP protocol allows two processes, each identified by a combination of an IP address and port number, to locate one another. The IP address is used to locate the machine that the process is running on (this is the "IP" part of the protocol), and the port number is used to locate the correct process on the machine (this is the "TCP" part).
Sockets In order to illustrate a typical TCP/IP transaction, we will examine the conversation between a fictitious student's mozilla web browser, running on the machine station3.example.com, which translates into an IP address of 123.45.67.89, and the httpd web server running at academy.redhat.com, which translates into an IP address of 66.187.232.51. The process usually resembles the following. As the machine academy.redhat.com is booted, the httpd process is started. It first allocates a socket, binds it to the port 80, and begins listening for connections. At some point later, perhaps measured in minutes, perhaps days, the mozilla process is started on the machine station3.example.com. It also allocates a socket, and requests to connect to port 80 of the machine 66.187.232.51. Because it did not request a particular port number, the kernel provides a random one, say 12345. As it requests the connection, it provides its own IP address and (randomly assigned) port number to the server. The server chooses to accept the connection. The established socket is now identified by the combined IP address and port number of both the client and server.
Sockets Once the socket is established, the mozilla process and the httpd process can read information from and write information to one another as easily as reading and writing from a file. (Remember... "everything is a file", even network connections! For most practical purposes, a socket is just another file descriptor.) The highlighted verbs in this section, bind, listen, connect, accept, and even read and write, are well defined terms in Linux (and Unix). They also are the names of the programming system calls that implement each step.
Sockets In the TCP/IP protocol, a socket is defined by the combined IP address and port number of both the server and the client. For example, what if our student was running multiple versions of Mozilla, each making requests of academy.redhat.com, or what if multiple users were using the machine station3.example.com simultaneously, all accessing academy.redhat.com? How would the web server keep straight which conversation it was having with which client? Each client process would be assigned a distinct port number, and therefore converse with the httpd daemon using a distinct socket.
More about Ports Well Known Services and the /etc/services File In our example, we mentioned that the httpd process requested to bind to port 80, and in turn the mozilla process requested to connect to port 80 of the server. How did each agree that port 80 was the appropriate port for the web server? Traditional Internet services, such as a web server, or ftp server, or SMTP (email) server, are referred to as well known services. On Linux (and Unix) machines, a catalog of well known services, and the ports assigned to them, is maintained in the file /etc/services. Notice that both the client and server need to agree on the appropriate port number, so the /etc/services file is just as important on the client's machine as on the server's. Just because a service is listed in the /etc/services file does not mean that you are implementing (or even capable of implementing) that well known service.
Privileged Ports Unlike clients, processes implementing network servers generally request which port they would like to bind to. Only one process may bind to a port at any given time (Why must this be?). Otherwise, how would a client distinguish which process it would like to connect to? Ports less than 1024 are referred to as privileged ports, and treated specially by the kernel. Only processes running as the root user may bind to privileged ports. (This helps ensure that, if elvis had an account on the machine academy.redhat.com, he couldn't start up a rogue version of a web server which might hand out false information.) Originally, the well known ports and the privileged ports were meant to coincide, but in practice there are more well known ports than privileged ones.
Determining Current TCP/IP Networking Services Using hostname to Display the Current IP Address The hostname command, without arguments, displays a machine's current hostname. With the -i command line switch, machine's IP address is displayed instead. What if there are multiple IP addresses? The design of the hostname command is a little misguided, because machines can easily have more than one IP address (one for each of multiple network interface cards, for instance.) In such situations, there is no reason why any one IP address should be privileged over the others. For historical reasons, however, the kernel keeps track of a parameter it refers to as its hostname, and the hostname -i command displays the IP address associated with it.
Using the netstat Command to Display Open Ports When a port is used by a socket, it is referred to as an open port. The netstat command can be used to display a variety of networking information, including open ports. Unfortunately, when called with no command line switches, the netstat command's output is overwhelmed by the least interesting information, local "Unix" sockets that are used to communicate between processes on the same machine. When called with the following command line switches, however, more interesting information is displayed.
Using the netstat Command to Display Open Ports Many more switches are available, as a quick look at the netstat(8) man page will reveal. The above switches were chosen from the many, not only because when combined, they produce interesting output, but also because they are easy to remember: just think "tuna". When invoked with the above switches, netstat's output is akin to the following.
Using the netstat Command to Display Open Ports Of the many lines, we may weed away those associated with the udp protocol, and focus instead on columns 4, 5, and 6 of the rows associated with tcp.
Understanding IPv6 Addresses The IP protocol which we discussed above, with friendly IP addresses such as "66.187.232.51", is known as Internet Protocol version 4, or "IPv4", and is by far the dominant IP protocol in use today. With the IPv4 protocol, you can have around 4 billion distinct IP addresses. When the IPv4 protocol was developed in the early 1970's, this was plenty of addresses, and the IPv4 protocol has served us well. By learning a few tricks such as masquerading, where many machines can "hide behind" a single public IP address, we still manage to live with it well. As appliances become more intelligent, however, and networking (particularly wireless networking) becomes cheaper, we are approaching a day where every toaster is going to want its own IP address, and 4 billion address wont' be enough. Changes are on the horizon. These changes are coming in the form of Internet Protocol Version 6, or "IPv6". Among many other changes, the IPv6 protocol takes the obvious step, and makes IP addresses bigger. Four times bigger. An IPv6 address, in full form, looks like fe80:0000:0000:0000:0211:22ff:fe33:4411. Instead of writing addresses as familiar decimal numbers (like "127"), they are written in hexadecimal numbers (like "fe33").
Understanding IPv6 Addresses Some merciful conventions in representing IPv6 addresses help. Once within an address, a series of zero segments, such as 0000:0000:0000, can be replaced with a double colon (::). For any segment which begins with leading zeros, such as 0211, the leading zeros can be dropped. With these two shortcuts in mind, the above address could be written a little more friendly as fe80::211:22ff:fe33:4411.
Understanding IPv6 Addresses Red Hat Enterprise Linux is getting ready for a future transition to IPv6, and many applications can already handle either IPv4 or IPv6 connections. For our purposes, because it is not yet widely adopted, we're going to ignore IPv6 as much as possible. Fortunately, there's just a few forms of IPv6 addresses we need to be able to recognize, summarized in the table below. Whenever these forms of IPv6 address are encountered ( ::ffff:192.168.0.1, ::1, and ::), you can simply think of them as their IPv4 equivalents ( 192.168.0.1, 127.0.0.1, and 0.0.0.0, respectively).
Understanding IPv6 Addresses Listening Sockets Listening are sockets are sockets owned by a server, before any clients have come along. For example, at the end of step one of our sample TCP/IP connection above, the httpd process would have a socket open in the listening state. Notice in the above output that for listening sockets, only the local half of the address is defined. Established Sockets As the name implies, established sockets have both a client process and a server process with established communication. Pulling it All Together
Understanding IPv6 Addresses These two sockets are listening for connections, but only on the loopback address. They must belong to services expecting to receive connections from other processes on the local machine, but not from other machines. To determine what services these ports belong to, we do some greping from the /etc/services file. Apparently, whatever process has claimed port 25 is listening for email clients. This is probably the sendmail daemon. The process listening on port 631 is listening for print clients. This is probably the cupsd printing daemon. Both of these services are discussed in more detail in this Workbook.
Understanding IPv6 Addresses These lines reflect both halves of an established connection between two processes, both on the local machine (notice the loopback IP address for both of them). The first is bound to port 59330 (probably a randomly assigned client port), and the second to the port 631. Some process on the local machine must be communicating with the cupsd daemon. Our final extracted lines represent established connections between clients on remote machines, and services on our local machine's external interface (192.168.122.156). The first is a connection to an IPv6 aware service on port 22. Again, we try a little grepping to look up the well known service associated with port 22. Apparently, this line represents an active connection between a ssh client on a remote machine with IP address 192.168.122.1, and a sshd daemon on our local machine. The latter is a connection to an IPv4 only service bound to port 653, probably an NFS related service.
Online Exercises Chapter 1. An Introduction to TCP/IP Networking Online Exercises Lab Exercise Objective: Gain familiarity with TCP/IP configuration and activity. Estimated Time: 10 mins. Specification • Create the file ~/lab11.1/ipaddr, which contains your machine's IP address, as reported by the hostname command, as its single word. • Create the file ~/lab11.1/listening_ports, which contains a list of all ports less then 1024 on your current machine which are open in the listening state, one port per line. Deliverables • The file ~/lab11.1/ipaddr, which contains your machine's current IP address (as reported by the hostname command) as its single word. • The file ~/lab11.1/listening_ports, which contains a list of all ports less then 1024 on your current machine which are open in the listening state, one port per line.
Chapter 2. Linux Printing Key Concepts • Red Hat Enterprise Linux uses the CUPS printing system for managing printers. • The CUPS printing system is designed around the concept of a print queue, which combines a spooling directory, a filter, and a print device. • The lpstat command browses available print queues. • The lpr, lpq, and lprm commands are used to submit ("request") print jobs, query for outstanding jobs, and remove pending print jobs, respectively. • Print submission applications examine the PRINTER environment variable to determine the default print queue. • The lp and cancel commands behave similarly to the lpr and lprm commands. • The cupsd daemon supports a web interface, which can be accessed at http://localhost:631.
Introducing CUPS Introducing CUPS Red Hat Enterprise Linux uses the Common Unix Printing System (CUPS) for managing printers. Rather than interacting with a printer directly, users submit print requests to print queues which are managed by the cupsd daemon. Print requests which are pending in a print queue are referred to as print jobs. Once a job has been submitted to the queue, users may return immediately to whatever tasks are at hand. If the printer is busy with another document, or out of paper, or unreachable over the network, the cupsd daemon will monitor the situation, and send (or resend) the print job to the printer as it becomes available. The cupsd daemon uses the Internet Printing Protocol (IPP), which is a direct extension of the HTTP protocol designed to allow print queue management in an operating system independent manner. As a result, CUPS management has much in common with web server management.
Introducing CUPS The following figure identifies the elements which participate in Linux printing. The various elements are discussed in more detail below.
Print Queues • A print queue is a combination of the following elements. • A spooling directory, where pending jobs may be temporarily stored. • A series of filters which reformat various formats of input files into a format appropriate for whatever back end device is connected to the queue. • A back end device, such as a locally attached printer, or a print queue defined on a remote machine. The following lists some of the various back end devices supported by CUPS. • locally attached parallel port printers • locally attached USB printers • networked printers using the LPD interface • networked printers using the JetDirect interface • IPP based print queues on remote machines • LPD based print queues on remote machines • SMB (Microsoft) network print services
Browsing Available Print Queues: lpstat Print queues are either available because they have been defined on the local machine, or discovered using CUPS's ability to browse the local network for published printers. The lpstat command can be used to scan available print queues from the command line. The following command line switches may be used to qualify the lpstat command.
Browsing Available Print Queues: lpstat See the lpstat(1) man page for more details. In the following, elvis is discovering that his system's default print queue is named simply "printer", and that he has several print queues available to him, which seem to all refer to IPP based print queues on a local print server.
Submitting and Managing Jobs: lpr, lpq,and lprm CUPS uses traditional UNIX commands to interface with the print system: lpr for submitting files and data to be printed, lpq for examining the status of outstanding print jobs, and lprm for removing pending print jobs from the queue. All three commands use the following techniques for specifying which print queue to use, in the specified order. • If the -P command line switch is found, its argument is used to specify the print queue. • If -P is not used, then if the PRINTER environment variable exists, it is used to define the default print queue. • Otherwise, the system default print queue is used.
Submitting Jobs with lpr Jobs may be submitted with the lpr command. Any arguments are interpreted as files to submit. If no arguments are specified, standard in is read instead. The following options may be used to qualify the lpr command. As an example, in the following, blondie uses the lpr command to print the file README, using the sales print queue.
Monitoring Jobs with lpq The lpq command lists pending jobs in a queue. In the following example, blondie will submit the output of the df command to the printer legal, and then examine the contents of the queue.
Removing Jobs with lprm Blondie suspects that something is wrong with the legal printer, and decides to start using the sales printer as her default printer. She first sets up the PRINTER environment variable to reflect her new preferences, the uses the lprm command to remove her job from the legal queue. Notice in the first lpq command, and the last lpr command, the PRINTER environment variable implicitly specified the sales print queue.
Alternate Front End Commands: lp and cancel In Unix, in the days preceding CUPS, two parallel implementations of printing infrastructure were implemented. The first used the three commands introduced above, namely lpr, lpq, and lprm. The other used lp, lpstat, and cancel for analogous roles. We have already seen that lpstat is supported, and is the preferred tool for discovering available print queues. The commands lp and cancel are also available as slight variations of the lpr and lprm commands. Consult the shared lp(1) man page for details.
The CUPS Web Interface Lastly, we would be remiss to leave the topic of CUPS without mentioning the native web interface provided by the cupsd daemon. As mentioned, most clients interact with the cupsd daemon using the IPP protocol, which is an extension of the HTTP protocol. Because of the similarities, the cupsd daemon behaves in may ways like a web daemon, including the serving of CGI style management pages. In order to view CUPS's management pages, point a web browser to the localhost address, but override the default port 80 with the CUPS daemons well known service port, 631. The cupsd daemon will return with a CUPS "homepage", from where printers and print jobs can be browsed, and copious online documentation is available.
Chapter 3. Managing Print Files Key Concepts • The primary printing format in Linux is PostScript. • Utilities such as ps2pdf and pdf2ps can convert PostScript to PDF and back. • evince previews PostScript and PDF documents. • enscript converts text file into decorated PostScript. • mpage can rearrange individual pages from a PostScript document.
PostScript In Linux, most printers expect to receive either ASCII text, or graphics using the PostScript format. Unlike most graphics formats, PostScript is actually a scripting language which has been tailored to the task of rendering graphics on the printed page. The PostScript Language's sophistication allows it to perform powerful tasks, but a PostScript interpreter must be used to render PostScript files as images. Many printers implement native PostScript interpreters, and are referred to as PostScript printers. Whenever a PostScript printer receives a text file which begins with the characters %!PS, the remainder of the file is interpreted as a PostScript script, rather than printed as ASCII text directly. (Note the similarity to Unix's #!/bin/bash scripting mechanism).
PostScript In Linux (and Unix), an application called Ghostscript, or simply gs, implements a PostScript interpreter. Implementing a PostScript interpreter is a significant task, and although several applications in Linux can be used to view or manipulate PostScript files, almost all use Ghostscript as the back end to perform the actual rendering of PostScript into more accessible graphics formats. Rather than using the low level Ghostscript interpreter directly, the easy to use evince application is usually used to view PostScript documents.
Viewing PostScript Documents with the evince Document Viewer. Many applications will print PostScript directly to files instead of delivering them to a print queue. For example, in the following dialog, by selecting "Print to File", the firefox web browser is being asked to print the current web page not to a print queue, but to a PostScript file titled example.ps.
Viewing PostScript Documents with the evince Document Viewer. As the head command illustrates, a PostScript file is a simple text file beginning with the PostScript "magic" %!PS. The PostScript file can be viewed with the evince document viewer.
Decorating Text for Printing with enscript The enscript utility converts text files into PostScript, often decorating the text with syntax highlighting (referred to as pretty printing), a header, or formatting multiple text pages per printed page (referred to as printing 2-up, 4-up, etc..). A little awkwardly, the enscript command sends a text file directly to the lpr command by default, with the result that enscripted files are immediately printed. The -o command line switch is often used to specify an output PostScript file instead. As an example, elvis could easily create a PostScript version of the GPL license.
Decorating Text for Printing with enscript So far, the formatting has been fairly minimal: A title, a date, and a page number. The enscript command comes with a host of more sophisticated formatting options, however. Some of the more commonly used command line switches are found in the following table.
Decorating Text for Printing with enscript Many more options exist. Consult the enscript(1) man page for more information. As an example, the following command line would render the C header file malloc.h as PostScript with 2 columns per page, rotated, and decorated with a fancy header and syntax highlighting.
Rearranging PostScript with mpage The mpage command can be used to extract pages from the middle of a multi-page PostScript document, or reformat the document to be printed with multiple pages per printed sheet. While designed to operate on PostScript, mpage can be fed plain text files as well, which it will simply render as PostScript before handling. Arguments are considered input files, with the output is directed to standard out.
Rearranging PostScript with mpage As an example, mpage could be used to convert the layout of the gpl.ps file generated earlier to "4 UP".
Converting PostScript to PDF and PDF to PostScript Unfortunately, on operating systems which are not Unix based, PostScript documents are pretty useless. The rest of the world deals with the alternate PDF format. Fortunately, Red Hat Enterprise Linux contains easy to use utilities that allow PostScript documents to be converted to PDF documents (ps2pdf), and vice versa (pdf2ps). The syntax of the ps2pdf command is trivial, where the first argument is the input PostScript filename (or a “-” to imply standard in), and the second argument is the output PDF filename (or a “-” to imply standard out). The pdf2ps command works similarly. As a quick example, in order to share his work with a friend who prefers PDF documents, elvis now uses the ps2pdf command to convert his malloc.ps file into PDF format, which is of comparable quality, but dramatically more compact.
Converting PostScript to PDF and PDF to PostScript Note that as a nice benefit, the PDF format allows evince to display document thumbnails in a side pane.
Chapter 4. Email Overview Key Concepts • Email Management involves an MUA (Mail User Agent), which is used to present newly delivered mail to a user, and allow the user to compose new responses, and an MTA (Mail Transport Agent), which manages the background task of exchanging email with remote machines. • Depending on the details of a computer's Internet access, the job of receiving email may be delegated to a mailbox server, which would then allow user's to access their delivered email using the POP or IMAP protocols. • Again depending on the details of a computer's Internet access, the job of delivering email may be delegated to a remote outgoing SMTP server. • Generally, locally delivered but unread mail is spooled in the file /var/spool/mail/$USER, where USER is the username of the recipient. • One of the simplest MUA's is the mail command.