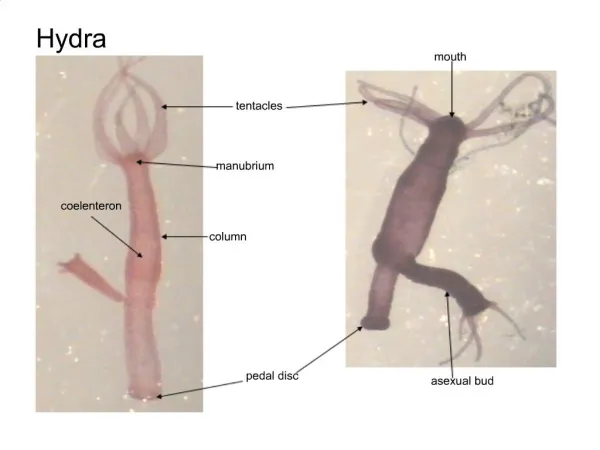
Download
1 / 1
10 likes | 145 Views
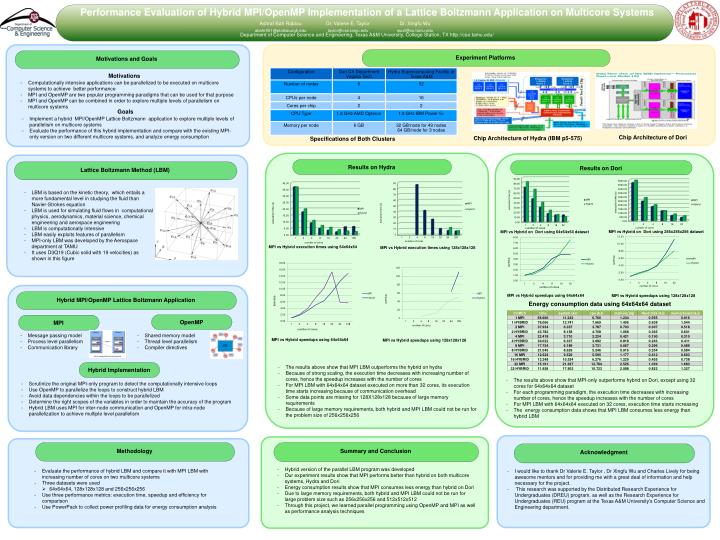
Performance Evaluation of Hybrid MPI/ OpenMP Implementation of a Lattice Boltzmann Application on Multicore Systems Department of Computer Science and Engineering, Texas A&M University, College Station, TX http://cse.tamu.edu/. MPI. OpenMP. Hybrid Implementation. Results on Hydra.

E N D
Performance Evaluation of Hybrid MPI/OpenMP Implementation of a Lattice Boltzmann Application on Multicore Systems Department of Computer Science and Engineering, Texas A&M University, College Station, TX http://cse.tamu.edu/ MPI OpenMP Hybrid Implementation Results on Hydra Summary and Conclusion Hybrid MPI/OpenMP Lattice Boltzmann Application Experiment Platforms Methodology Lattice Boltzmann Method (LBM) Motivations and Goals Results on Dori Acknowledgment Motivations • Computationally intensive applications can be parallelized to be executed on multicore systems to achieve better performance • MPI and OpenMP are two popular programming paradigms that can be used for that purpose • MPI and OpenMP can be combined in order to explore multiple levels of parallelism on multicore systems Goals • Implement a hybrid MPI/OpenMP Lattice Boltzmann application to explore multiple levels of parallelism on multicore systems • Evaluate the performance of this hybrid implementation and compare with the existing MPI-only version on two different multicore systems, and analyze energy consumption Chip Architecture of Dori Chip Architecture of Hydra (IBM p5-575) Specifications of Both Clusters • LBM is based on the kinetic theory, which entails a more fundamental level in studying the fluid than Navier-Strokes equation • LBM is used for simulating fluid flows in computational physics, aerodynamics, material science, chemical engineering and aerospace engineering • LBM is computationally intensive • LBM easily exploits features of parallelism • MPI-only LBM was developed by the Aerospace department at TAMU • It uses D3Q19 (Cubic solid with 19 velocities) as shown in this figure MPI vs Hybrid on Dori using 256x256x256 dataset MPI vs Hybrid on Dori using 64x64x64 dataset MPI vs Hybrid execution times using 64x64x64 MPI vs Hybrid execution times using 128x128x128 MPI vs Hybrid speedups using 64x64x64 MPI vs Hybrid speedups using 128x128x128 Energy consumption data using 64x64x64 dataset • Message passing model • Process level parallelism • Communication library • Shared memory model • Thread level parallelism • Compiler directives MPI vs Hybrid speedups using 64x64x64 MPI vs Hybrid speedups using 128x128x128 • The results above show that MPI LBM outperforms the hybrid on hydra • Because of strong scaling, the execution time decreases with increasing number of cores, hence the speedup increases with the number of cores • For MPI LBM with 64x64x64 dataset executed on more than 32 cores, its execution time starts increasing because of communication overhead • Some data points are missing for 128X128x128 because of large memory requirements • Because of large memory requirements, both hybrid and MPI LBM could not be run for the problem size of 256x256x256 • The results above show that MPI-only outperforms hybrid on Dori, except using 32 cores for 64x64x64 dataset • For each programming paradigm, the execution time decreases with increasing number of cores, hence the speedup increases with the number of cores • For MPI LBM with 64x64x64 executed on 32 cores, execution time starts increasing • The energy consumption data shows that MPI LBM consumes less energy than hybrid LBM • Scrutinize the original MPI-only program to detect the computationally intensive loops • Use OpenMP to parallelize the loops to construct hybrid LBM • Avoid data dependencies within the loops to be parallelized • Determine the right scopes of the variables in order to maintain the accuracy of the program • Hybrid LBM uses MPI for inter-node communication and OpenMP for intra-node parallelization to achieve multiple level parallelism • Hybrid version of the parallel LBM program was developed • Our experiment results show that MPI performs better than hybrid on both multicore systems, Hydra and Dori • Energy consumption results show that MPI consumes less energy than hybrid on Dori • Due to large memory requirements, both hybrid and MPI LBM could not be run for large problem size such as 256x256x256 and 512x512x512 • Through this project, we learned parallel programming using OpenMP and MPI as well as performance analysis techniques • Evaluate the performance of hybrid LBM and compare it with MPI LBM with increasing number of cores on two multicore systems • Three datasets were used • 64x64x64, 128x128x128 and 256x256x256 • Use three performance metrics: execution time, speedup and efficiency for comparison • Use PowerPack to collect power profiling data for energy consumption analysis • I would like to thank Dr Valerie E. Taylor , Dr Xingfu Wu and Charles Lively for being awesome mentors and for providing me with a great deal of information and help necessary for the project. • This research was supported by the Distributed Research Experience for Undergraduates (DREU) program, as well as the Research Experience for Undergraduates (REU) program at the Texas A&M University's Computer Science and Engineering department.