Download

1 / 65
720 likes | 989 Views
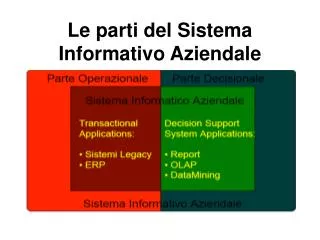
Introduzione I livelli del sistema informativo Il sistema informativo direzionale Data Warehouses / Data Marts Concetto e caratteristiche Architetture (Inmon vs Kimball) Approccio metodologico (top-down, bottom-up) Modellazione (star-schema, snowflake-schema) Software (Datastage)

E N D
Introduzione • I livelli del sistema informativo • Il sistema informativo direzionale • Data Warehouses / Data Marts • Concetto e caratteristiche • Architetture (Inmon vs Kimball) • Approccio metodologico (top-down, bottom-up) • Modellazione (star-schema, snowflake-schema) • Software (Datastage) • Data Presentation / Data Analysis • Navigazione OLAP (slice&Dice, drill-down) • Reporting • Data Mining • Software (Business Objects, SAS) • Decision Making • Cruscotti direzionali
Tipologie di sistemi informativi: note Transaction processing systems: • Support the operational level of the organization, possibly integrating needs of different functional areas (ERP); • Perform and record the daily transactions necessary to the conduct of the business • Execute simple read/update operations on traditional databases, aiming at maximizing transaction throughput • Their activity is described as: OLTP (On-Line Transaction Processing) Knowledge level systems: provide digital support for managing documents (office automation), user cooperation and communication (groupware), storing and retrieving information (content distribution), automation of business procedures (workflow management) Management level systems: support planning, controlling and semi-structured decision making at management level by providing reports and analyses of current and historical data Executive support systems: support unstructured decision making at the strategic level of the organization
Uno sguardo al software Business Objects Business Objects Business Objects SAS Datastage DB2
Il concetto di Data Warehouse “Una piattaforma sulla quale vengono archiviati e gestiti dati provenienti dalle diverse aree dell’organizzazione. Tali dati sono aggiornati, integrati e consolidati dai sistemi di carattere operativo per supportare tutte le applicazioni di supporto alle decisioni ” (Gartner Group) “Un insieme di dati subject oriented, integrato, time variant, non volatile costruito per supportare il processo decisionale”(W.H.Inmon)
Concetto di data warehouse: note Esistono moltissime definizioni che identificano con precisione il concetto di Data Warehouse, in particolare ne possiamo citare due che ne sottolineano le caratteristiche peculiari: “Una piattaforma sulla quale vengono archiviati e gestiti dati provenienti dalle diverse aree dell’organizzazione; tali dati sono aggiornati, integrati e consolidati dai sistemi di carattere operativo per supportare tutte le applicazioni di supporto alle decisioni ” (Gartner Group) “Un insieme di dati subject oriented, integrato, time variant, non volatile costruito per supportare il processo decisionale”(W.H.Inmon) Il Data Warehouse è una collezione di dati a supporto del processo decisionale, attraverso il Data Warehouse il management ha l’opportunità concreta di trovare le risposte a tutte quelle domande che hanno un alto impatto sulle performance aziendali; chi ricopre ruoli decisionali deve avere la possibilità di usufruire di tutti gli strumenti che possono rendere la guida dell’azienda massimamente sicura.
Fruizione dei dati: problematiche Le tipiche problematiche del management relativamente alla fruizione di dati possono essere riassunte come segue: • Assenza di sintesi nella reportistica • Risultati diversi da fonti diverse per la stessa tematica • Impossibilità di navigare nei dati ragionando con oggetti “business” • Inaffidabilità di alcuni dati critici • Costi elevati per sintetizzare report e analisi • Scarsa “collaborazione” o impossibilità di comunicazione dei sistemi informativi transazionali per interrogare i dati • Assenza di coerenza fra i dati • Lentezza nell’interrogazione di dati non ottimizzati per l’analisi
Data Warehouse: caratteristiche • Bassi tempi di attesa fra l’interrogazione dei dati e l’output di risultati • Consistenza dei dati • Dati ricombinati e separati rispetto agli oggetti di calcolo definiti dal business • Presentazione chiara della sintesi delle analisi • Dati coerenti e “ripuliti” • Evidenza di problematiche connesse ad assenza dei dati • Sistema in sola lettura
Caratteristiche del data warehouse: note Queste problematiche sono così universali che possono essere considerate come requirements fondamentali per la costruzione di un sistema di Data Warehouse, il quale si poggia perciò su alcune caratteristiche molto importanti: 1- Il Data Warehouse deve consentire l’accesso a dati aziendali garantendo bassi tempi di attesa fra l’interrogazione dei dati e l’output di risultati. 2- I dati esposti devono essere consistenti: un particolare valore (le vendite del prodotto A nella città B nel periodo di tempo C) deve essere sempre lo stesso indipendentemente dal momento dell’interrogazione o dalla modalità di interrogazione dei dati. 3- I dati esposti possono essere ricombinati e separati rispetto agli oggetti di calcolo definiti dal business. 4- Nel concetto di data warehouse rientrano anche gli strumenti software necessari a facilitare l’interrogazione dei dati e a garantire una presentazione chiara della sintesi delle analisi. 5- Il Data Warehouse deve contenere dati coerenti e “ripuliti”: capita che fonti importanti di dati per il Data Warehouse trascinino errori di diverso genere che possono avere un impatto devastante sulla qualità dei dati stessi, parte fondamentale del processo di realizzazione di un sistema di Data Warehouse è rappresentata proprio da attività di recupero, trasformazione e pulitura dei dati. 6- La qualità del Data Warehouse può mettere in luce problematiche nascoste all’interno dei processi aziendali, tipicamente l’assenza di dati relativamente ad una particolare attività dovuta all’opzionalità di compilazione dei dati (causa principale dell’assenza di dati) può evidenziare, proprio grazie al Data Warehouse, la necessità di verificare a livello di processi aziendali l’opportunità di definirla come obbligatoria (e non opzionale). 7- Il Data Warehouse è un sistema in sola lettura, gli utenti non eseguono azioni di aggiunta, modifica o eliminazione dei dati.
Trattamento dei dati aziendali Questi punti mettono in evidenza come sia necessario porre l’attenzione sull’esistenza di due universi completamente diversi nell’ambito del trattamento dei dati aziendali : On line transaction processing (OLTP) è l’insieme dei sistemi transazionali pensati e ottimizzati per garantire la massima sicurezza nella gestione delle transazioni On line Analytical processing (OLAP) è l’insieme dei sistemi di analisi dei dati pensati e ottimizzati per garantire la massima performance e la massima “estensione” delle interrogazioni
Architetture OLAP ROLAP (Relational OLAP): uses relational DBMS to store and manage warehouse data (i.e., table-oriented organization), and specific middleware to support OLAP queries MOLAP (Multidimensional OLAP): uses array-based data structures and pre-computed aggregated data. It shows higher performance than OLAP but may not scale well if not properly implemented HOLAP (Hybird OLAP): ROLAP approach for low-level raw data, MOLAP approach for higher-level data (aggregations)
I motivi del successo Il recente successo della “filosofia” OLAP (tanto elevato da rendere, in molte realtà, il data Warehouse una soluzione necessaria quasi quanto la presenza dei sistemi OLTP) è dovuto almeno in parte a: Disponibilità di potenza elaborativa per gestire grossi volumi di dati a basso costo Possibilità di distribuzione delle informazioni tramite tecnologia intranet/Internet
Costruzione del DWH Data Capture DWH Storage Management Information Delivery Informix Extract Data Mart Oracle Data Mart Secondary Transform MVS Data Warehouse Data Mart SQL Server Load External Data Data Mart
Costruzione del DWH: note Dal punto di vista tecnico/architetturale la definizione di un ambiente data warehouse può essere così semplificata:1- I dati sorgente, oggetto dell'analisi, vengono forniti dai sistemi transazionali e possono essere di varia natura (sistemi ERP, fogli excel database personali, dati core di applicazioni aziendali, ecc.). 2- Tali dati sono caricati nel data warehouse attraverso procedure di ETL (extraction, transformation e loading) (che possono essere il risultato dello sviluppo di un'interfaccia applicativa in SQL, C, ecc. o possono essere definite e costruite con complessi tool di ETL presenti sul mercato) 3- Nel data warehouse (sorvoliamo sulle complessità relative al disegno della struttura e alle aree di staging, della gestione dei metadati, ecc.) i dati sono presenti al massimo dettaglio e storicizzati e spesso raggiungono dimensioni comunque poco compatibili con l'interrogazione diretta attraverso tool di analisi: vengono così generati dal data warehouse aggregati tematici di dati (datamart) sui quali verranno scatenate le query per le analisi. 4- Un notevole numero di tool permettono di effettuare analisi di ogni tipo o di migliorare ulteriormente le performance delle interrogazioni, i server OLAP (database multidimensionali) possono precalcolare le possibili combinazioni analitiche e memorizzarle fisicamente in un file binario (con esplosione delle dimensioni), tool di analisi appositi possono interrogare i dati sfruttando puntatori che indicano la posizione del dato precalcolato anziché attendere i tempi di elaborazione del motore database. I server OLAP possono memorizzare i dati con diverse modalità utilizzando strutture relazionali (ROLAP) o multidimensionali (MOLAP), per database smisurati (centinaia di giga) spesso si utilizza una modalità ibrida (HOLAP).
Uno sguardo al software Data Capture DWH Storage Management Information Delivery Informix Extract Data Mart Oracle Data Mart Business Objects Secondary Transform MVS Datastage SAS Data Warehouse DB2 Data Mart Datastage DB2 SQL Server Load External Data Data Mart
Architetture DWH Liberare le informazioni aziendali e fornirle in modo concreto e chiaro a coloro che in azienda prendono decisioni tattiche e strategiche PARADIGMI di maggior successo WILLIAM INMON RALPH KIMBALL
La business intelligence negli ultimi 10 anni ha vissuto una crescita di interesse continuo, questo, accanto ad ovvi benefici, ha portato anche una componente di confusione che, in assenza di uno standard, influisce negativamente nella comprensione a tutto campo del concetto di business intelligence; tale confusione trae origine anche da alcuni paradigmi che si sono affermati negli ultimi anni e che rispecchiano filosofie e tecniche diverse per risolvere il medesimo problema : liberare le informazioni aziendali e fornirle in modo concreto e chiaro a coloro che in azienda prendono decisioni tattiche e strategiche.Una visione, per quanto approssimativa, dei paradigmi di maggiore successo, può essere utile a chiarire differenze e punti in comune.
Architetture DWH:William Inmon Corporate information factory Le informazioni supportano tre livelli di processi organizzativi:
In questa prima parte affronteremo l'architettura suggerita e sviluppata da William "Bill" Inmon. Corporate information factory La corporate information factory (CIF) è un’architettura concettuale largamente accettata che descrive e categorizza le informazioni per definire e gestire una robusta infrastruttura di Business intelligence.Tali informazioni supportano tre livelli di processi organizzativi :Business operations: riguardano la gestione giorno per giorno delle informazioni relative alle attività operative del business, dipendono direttamente dai sistemi transazionali aziendali e sono informazioni fortemente automatizzate, che non evolvono ne cambiano nel tempo, sono informazioni puntuali e di dettaglio caratteristiche del controllo della “produzione” della propria azienda.Business intelligence: riguardano le informazioni che vengono cercate all’interno dell’azienda per migliorare le prestazioni, per conoscere meglio i propri clienti, per analizzare le caratteristiche del proprio prodotto e la storia che lo coinvolge, rispetto al livello Business operations, sono informazioni di tipo dinamico, che evolvono continuamente nel tempo, per le loro caratteristiche hanno un fondamentale ruolo nelle decisioni strategiche aziendali.Business management: è la funzione nella quale la conoscenza derivata dal livello Business intelligence viene istituzionalizzata e introdotta a tutti i livelli in azienda.
Le componenti principali che formano l’architettura CIF possono essere suddivise per maggiore chiarezza e semplicità in tre classi distinte : 1. I sistemi transazionali : che rappresentano tutte le applicazioni aziendali che costruiscono l’informazione operativa dell’azienda stessa, ne fanno parte tutti i software che gestiscono o producono dati aziendali: ERP, software di gestione ordini/acquisti, software di gestione delle risorse umane, della logistica, ecc. i dati raccolti da tali sistemi non sono informazioni di business: la loro struttura è compatibile con le caratteristiche dei sistemi che sono determinate da alcuni vincoli come la normalizzazione dei dati e l’assenza di ridondanza delle informazioni, la migliore gestione possibile di “inserimenti, modifiche e eliminazione” dei dati, la distribuzione di dati atomici in diversi punti degli archivi che li ospitano. 2. Il “contenitore” di dati per analisi e supporto alle decisioni “tattiche”: è rappresentato da una configurazione di dati chiamata Operational data store che fornisce informazioni, con uno scarto temporale minimo, dei sistemi transazionali tradotte in oggetti di business e organizzate per consentire analisi di dettaglio. 3. Il “contenitore” di dati per analisi e supporto alle decisioni “strategiche”: è rappresentato da una configurazione di dati chiamata data warehouse, che fornisce informazioni periodiche, storicizzate e riorganizzate secondo le regole aziendali che fornisce informazioni e oggetti di business per consentire analisi a supporto delle decisioni strategiche.
Architetture DWH:Ralph Kimball Staging area e data warehouse Due strati che riguardano specificamente le informazioni utili alla definizione di un sistema di business intelligence:
Di seguito l'architettura teorizzata da Ralph Kimball. Staging area e data warehouse Un’architettura meno estesa dal punto di vista dei sistemi informativi aziendali, è rappresentata dalla definizione di due strati che riguardano specificamente le informazioni utili alla definizione di un sistema di business intelligence : 1. il primo strato è definito Data staging area è direttamente alimentato dai sistemi sorgente (ERP, ecc.) ed è il luogo dove i dati vengono estratti, trasformati e caricati seguendo le regole che definiscono gli oggetti di business necessari alle analisi, la staging area è una porzione dell’architettura “tecnica” non accessibile agli utenti finali e nella quale non vengono eseguite interrogazioni : i dati sono “preparati” perché possano essere importati nel data warehouse. 2. il secondo strato è definito come Data warehouse presentation servers : è il luogo dove viene fisicamente creato il data warehouse e dove i dati vengono esposti in maniera chiara e compatibile con le regole e gli oggetti di business, tale strato è accessibile agli utenti finali attraverso gli strumenti di queryng e di reporting, ed è costituito da un raggruppamento di “porzioni logiche” dei dati disponibili (datamart) organizzate e rese conformi attraverso un’architettura denominata “warehouse bus”.
Architetture DWH:Inmon vs Kimball • In entrambe le architetture è presente uno strato di raccolta e “pulizia” dei dati sorgente, fonte dati del sistema analitico front-end. • Nella prima architettura (CIF) il concetto di ODS assume importanza soprattutto nello strato relativo alle informazioni di tipo Business operations, nella seconda architettura l’ODS non è invece considerato sufficientemente orientato al business anche se possiede il vantaggio di essere sempre “in linea” temporalmente con i sistemi transazionali. • Ralph Kimball propone come linea guida di evitare l’incorporamento di ODS in una soluzione di data warehouse
Punti di contatto e di distanza tra le due architetture di riferimento per la creazione di un data warehouse. Non è semplice poter identificare un’architettura di riferimento che possa rappresentare un standard, tale impossibilità è però mitigata dal fatto che, pur nelle differenze di contenuti e rappresentazione, le due architetture riportate presentano molti punti in comune e la sostanziale differenza sembra attribuibile principalmente a due soli punti, il primo di terminologia, il secondo di estensione del concetto di business intelligence alla presenza del livello ODS: 1. Le due architetture presentano una componente di raccolta dei dati che è definita come data warehouse nell’architettura CIF e staging area nell’architettura costituita da staging area e data warehouse, pur con le dovute differenze in entrambe le architetture è presente uno strato di raccolta e “pulizia” dei dati sorgente, fonte dati del sistema analitico front-end.2. Nella prima architettura (CIF) il concetto di ODS assume importanza soprattutto nello strato relativo alle informazioni di tipo Business operations, nella seconda architettura l’ODS non è invece considerato sufficientemente orientato al business anche se possiede il vantaggio di essere sempre “in linea” temporalmente con i sistemi transazionali.E’ il secondo punto che evidenzia una certa distanza fra i due paradigmi, Ralph Kimball, teorizzatore dell’architettura basata su area di staging e data warehouse, propone come linea guida di evitare l’incorporamento di ODS in una soluzione di data warehouse :“If you have an operational data store in your systems environment, or in your plans, examine it carefully. If it is meant to play an operational, real-time role, then it truly is an operational data store and should have its own place in the systems world. If, on the other hand, it is meant to provide reporting or decision support, we encourage you to skip the ODS and meet these needs directly from the detailed level of the data warehouse.” Di fatto, però, entrambe le soluzioni propongono metodologie che, se seguite con scrupolo, garantiscono il corretto sviluppo di progetti di business intelligence.
Approccio metodologico al DWH I guru: Ralph Kimball e Bill Inmon L’approccio metodologico relativo alla realizzazione di soluzioni di data warehouse dipende direttamente dall’organizzazione aziendale, dalla tipologia di utenti dall’architettura tecnica del sistema e dalle criticità evidenziate.
Approccio top-down Implementazione estensiva del sistema, il cui disegno originale tiene in considerazione tutte le principali aree di interesse aziendale. I datamart dipendenti costituiscono un subset di dati aziendali altamente specializzati per aree di interesse o dipartimenti aziendali. Rappresenta l'approccio migliore per la costituzione del data warehouse. Difficoltà di gestione del progetto onnicomprensivo, che rischia di paralizzare l’attività e di fornire risultati troppo in avanti nel tempo.
Note sull’approccio top-down L’approccio top-down è quello che prevede una implementazione estensiva del sistema, il cui disegno originale tiene in considerazione tutte le principali aree di interesse aziendale. Si parla in questo caso di Enterprise data warehouse, che può essere successivamente suddiviso in un insieme di datamart, per motivi tecnici ed organizzativi, pur mantenendo rigorosamente accorpata la visione totalitaria d’insieme della soluzione. I datamart dipendenti costituiscono un subset di dati aziendali altamente specializzati per aree di interesse o dipartimenti aziendali. Il punto debole di questo approccio teoricamente rigoroso è nella difficoltà di gestione del progetto onnicomprensivo, che rischia di paralizzare l’attività e di fornire risultati troppo in avanti nel tempo, questo tipo di approccio (caldamente suggerito da Bill Inmon) rappresenta l'approccio migliore per la costituzione del data warehouse, va valutata la sua applicabilità relativamente allo sforzo che il cliente prevede di sostenere, se il sistema di data warehouse rappresenta (come dovrebbe) un progetto strategico per il cliente il budget non può che essere correttamente proporzionato.
Approccio bottom-up Implementazione non coordinata nella quale ogni datamart viene realizzato per rispondere ad uno specifico fabbisogno informativo di una utenza dipartimentale. L’Enterprise data warehouse è il risultato dell’insieme dei singoli datamart indipendenti, che si alimentano direttamente dai sistemi operazionali. Il vantaggio di tale approccio pragmatico è unicamente conseguire risultati utili per l’utente in un arco temporale limitato con costi diretti relativamente contenuti.
Note sull’approccio bottom-up L’approccio bottom-up prevede una implementazione non coordinata nella quale ogni datamart viene realizzato per rispondere ad uno specifico fabbisogno informativo di una utenza dipartimentale. In questo caso l’Enterprise data warehouse è il risultato dell’insieme dei singoli datamart indipendenti, che si alimentano direttamente dai sistemi operazionali. Il vantaggio di tale approccio pragmatico è unicamente conseguire risultati utili per l’utente in un arco temporale limitato con costi diretti relativamente contenuti. Tale approccio può essere valutato solo per progetti con budget di sviluppo molto bassi e, soprattutto, il cliente deve essere ben informato sui rischi del costo di manutenzione di un data warehouse di tale tipo.
Approccio “incrementale”Enterprise datamart Architecture (EDMA) Alla base di questo approccio, definito in letteratura anche approccio “federato”, è la creazione di un modello informativo comune che minimizzi i problemi di integrazione tra datamart. L’utilizzo di un’architettura data warehouse Bus consente l’individuazione e la condivisione di dimensioni e fatti razionalizzate rispetto ai processi aziendali. Il concetto di dimensioni e fatti conformi rende possibile rilasciare velocemente il datamart, certi che le successive attività a livello di data warehouse non potranno creare isole informative.
Note sull’approccio incrementale L’approccio “incrementale” combina i vantaggi dei due approcci sopra descritti (e vede in Ralph Kimball il primo sostenitore).Alla base di questo approccio, definito in letteratura anche approccio “federato”, infatti, è la creazione di un modello informativo comune.Dal modello informativo comune vengono sviluppati in maniera coerente modelli dati dell’Enterprise data warehouse e/o dei datamart; questi ultimi possono essere sia dipendenti che indipendenti.L’implementazione prevede di mettere a fattor comune tra diversi progetti di datamart i processi di acquisizione di dati dai sistemi transazionali.E' tuttavia fondamentale segnalare che è comunque opportuno consigliare l'eliminazione datamart indipendenti, non appena sviluppati quelli derivanti direttamente dall'ambiente integrato del data warehouse; è importante verificare tempi e costi dello sviluppo temporaneo di datamart indipendenti. Il risultato dei processi di acquisizione viene centralizzato su aree di appoggio comuni (cosiddette aree di staging) su cui vengono svolti i successivi processi di trasformazione.Il modello informativo comune e la fruizione delle aree di staging minimizza i problemi di integrazione tra datamart, l’utilizzo di un’architettura data warehouse Bus consente l’individuazione e la condivisione di dimensioni e fatti razionalizzate rispetto ai processi aziendali.Il concetto di Warehouse Bus (partorito da Ralph Kimball) è l'uovo di Colombo che in molti casi consente un approccio incrementale paragonabile nei risultati a quello Top Down di Inmon.Alla definizione di dettaglio nel data warehouse di un particolare processo basato sul concetto di dimensioni e fatti conformi è possibile rilasciare velocemente il datamart aggregato, certi che le successive attività a livello di data warehouse non potranno creare isole informative.
La modellazione del DWH • Relational OLAP • Dimensioni: approccio di tipo “data driven” • Fatti: approccio di tipo “business driven” • Livello di granularità: dato atomico • Uso di viste materializzate
L’adozione dello snowflake Spesso le DT raggiungono notevoli dimensioni (pensiamo alla dimensione Cliente di una catena di supermercati, i singoli clienti potrebbero essere centinaia di migliaia o milioni), in questo caso lo SC può presentare qualche problema, soprattutto nel caso di dimensioni che hanno importanti attributi gerarchici a bassa cardinalità. Un esempio: Nella dimensione prodotto (formata da 300.000 records) sono presenti numerosissimi attributi (diciamo 100 campi di tipo descrittivo), da un punto di vista business, esiste in questa dimensione il concetto di Linea di prodotto che raggruppa una serie di articoli prodotto (che rappresentano la granularità minima e quindi il concetto di singolo prodotto), poniamo il caso che le linee prodotto siano 50 per i 300.000 articoli.Cosa succede se il concetto di linea di prodotto è accompagnata da una serie di informazioni aggiuntive (ospitate per esempio da 20 campi nella dimensione) relative proprio alla linea di prodotto e non all'articolo ? La bassa cardinalità del tipo di prodotto causerebbe nella denormalizzazione un'impressionante ridondanza di dati e i 20 campi descrittivi relativi al tipo di prodotto contribuirebbero (oltre che alla ridondanza) ad un possibile massiccio aumento di dimensioni che potrebbe influire negativamente sulle prestazioni rispetto ad un rinormalizzazione snowflake (non preoccupiamoci delle dimensioni, ma delle prestazioni).
Dimensioni varianti • Tipo I • Tipo II • Tipo III
Strumenti per l’ETL:Data Stage ANY TARGET ANY SOURCE E T L CRM ERP SCM RDBMS Legacy Real-time Client-server Web services Data Warehouse Other apps. CRM ERP SCM BI/Analytics RDBMS Real-time Client-server Web services Data Warehouse Other apps.
OLAP (On-Line Analytical Processing) • Reporting based on (multidimensional) data analysis • Read-only access on repositories of moderate-large size (typically, data warehouses), aiming at maximizing response time • Data Mining • Discovery of novel, implicit patterns from, possibly heterogeneous, data sources • Use a mix of sophisticated statistical and high performance computing techniques
Strumenti per l’analisi OLAP:Business Objects Database Aziendali Database transazionali Data Marts Rappresentazione Business Oriented Designer Supervisor Punto di controllo Thin client Gli utenti accedono al database usando uno strato semantico (UNIVERSO) che fornisce loro una rappresentazione Business Oriented dei database. Web Intelligence Query, Reporting OLAP