Download

1 / 45
460 likes | 881 Views
Lecture 4. Decision Support System OLAP introduction, definitionand operations Cube computation Intersting OLAP Application: Discovery using OLAP cubes SQL Extensions for OLAP and analytiics.

E N D
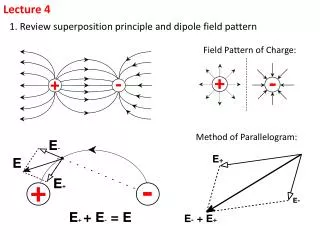
Lecture 4 • Decision Support System • OLAP introduction, definitionand operations • Cube computation • Intersting OLAP Application: Discovery using OLAP cubes • SQL Extensions for OLAP and analytiics
Decision-support systems are used to make business decisions often based on data collected by OLTP systems. Examples of business decisions: What product brands would be popular this season? Who to advertise the ski package deal? What services to upgrade in the new year. Examples of data used for making decisions Transaction retail data Customer data Performance data Decision Support Systems
Data analysis tasks are simplified by specialized tools and SQL extensions Example tasks For each product category and each region, what were the total sales in the last quarter and how do they compare with the same quarter last year As above, for each product category and each customer category Statistical analysis packages (e.g., : S++) can be interfaced with databases Data mining seeks to discover knowledge automatically in the form of statistical rules and patterns from Large databases. A data warehouse archives information gathered from multiple sources, and stores it under a unified schema, at a single site. Important for large businesses which generate data from multiple divisions, possibly at multiple sites Data may also be purchased externally Decision-Support Systems: Major categories
Decision Support Systems: Datawarehouse • A data warehouse archives information gathered from multiple sources, and stores it under a unified schema, at a single site. • Major properties of a data warehouse: • Subject-focused: focused around a particular subject; irrleevant data is not included • Integrated and consolidated: Integrating data from multiple, heterogeneous sources; issues like data cleaning, consistency are involved. • historical: historical data is of more significance than in OLTP dbs. • Rare updates: Unlike in OLTP DBs, there is no concept of transactions that update data; data once loaded will only typically be acessed not updated (only deletions at the end).
Online Analytical Processing (OLAP) Interactive analysis of data, allowing data to be summarized and viewed in different ways in an online fashion (with negligible delay) The object of interest in OLAP is a cube. A cube allows data to be viewed in multiple dimensions. An n-dimensional cube is defined as a group of k-dimensional (k<=n) cuboids arranged by the dimensions of the data. A cell of a cuboid represents an association of a measure m (eg total sales) with a member of every dimension (product->group=”toys”, location->state=”NJ”, time->year=2003”). The n-D cuboid is called a base cuboid. The top most 0-D cuboid, which holds the highest-level of summaries, is called the apex cuboid. Data Analysis and OLAP
ABCD ABC ABD ACD BCD AB AC AD BC BD CD A B C D all Cube lattice for a 3-d data cube Cube Lattice
2003 Period->year 2002 PA 2.5M 2001 NY NJ toys clothes cosmetics Item->category Data cube with dimension heirarchy item location category brand city state country period day Location->state month year
item_key period_key location_key item_name day street Item_key Item_type month city period_key brand year state location_key country Num_units_sold Amount_sold Modelling of dimensions and measures in a datawarehouse • Star schema:A fact table in the middle containing the dimension keys surrounded by a set of dimensional tables. The fact table contains the set of measures on which the attributes are to be aggregated.
period_key dept_key item_key location_key dept_name day item_name street dept_key Item_key dept_head Item_type month city period_key period_key Dept_function brand year state location_key location_key country Num_employees Num_units_sold Amount_sold expenses Modelling of dimensions and measures in a datawarehouse • Fact constellation: Multiple fact tables share dimension tables
multidimensional OLAP (MOLAP) : use multidimensional arrays to store data cubes; the advantage is faster performance; the disadvantage is that data needs to be precomputed limiting the data that can be looked at; proprietary tachnology. Examples: Business Objects, Cognos, Hyperion relational OLAP (ROLAP): uses relational database features; can handle larger amounts of data; the disadvantage is slower performance. Examples: Microstrategy hybrid OLAP (HOLAP):Hybrid systems, which store some summaries in memory and store the base data and other summaries in a relational database, OLAP Implementation Architecture
OLAP cube operations • Roll up (drill-up): summarize data by climbing up hierarchy or by reducing the number of dimensions. • Drill down (roll down):from higher level summary to lower level summary or detailed data, or introducing new dimensions. • Slice operation:Selects the dimensions of the cube to be viewed. Eg view “Sales volume” as a function of “category ” by “Country “by “year”. • Dice operation: Specifies the values along one or more dimensions. Eg view “Sales volume” as a function of “category ” by “Country “by “year for the year 2004. • Pivot operation: Reorient the cube by replacing one or more of the dimensions
OLAP Cube Computation Top-down Approach: • Start by computing the base cuboid (groupby for which no cube dimensions are aggregated).A single pass is made over the data, a record is examined and the appropriate base cell is incremented. • The remaining groupbys are computed by aggregating over already computed finer grade groupby. If a groupby can be computed from one or more possible parent groupbys, the algorithm uses the parent which is smallest in size. • If a groupby can be computed from one or more possible parent groupbys, the algorithm uses the parent which is smallest in size.
ABCD ABC ABD ACD BCD AB AC AD BC BD CD A B C D all Figure 4: Top-down cube computation Top-down approach
Top-down optimizations: Pipe-sort and pipe-hash • The basic idea of both algorithms is that a minimum spanning tree should be generated from the original lattice such that the cost of traversing edges will be minimized. The optimizations for the costs these algorithms include are: • Cache-results: This optimization aims at ensuring the results of a groupby is cached (in memory), so that it can be used by other group-bys in future. • Amortize-scans: This optimization amortizes the cost of a disk read by computing maximum possible number of group-bys, together in memory. • Share-sorts: For a sort-based algorithm, this aims at sharing sorting cost across multiple group-bys. • Share-partitions: For a hash-based algorithm, when the hash-table is too large to fit in memory, data is partitioned and aggregated to fit in memory. This can be achieved by sharing this cost across multiple group- bys.
C c3 61 62 63 64 c2 45 46 47 48 c1 29 30 31 32 c 0 B 60 13 14 15 16 b3 44 28 56 9 b2 B 40 24 52 5 b1 36 20 1 2 3 4 b0 a0 a1 a2 a3 A Multiway Array Aggregation for MOLAP • Arrays are partitioned into chunks (a small subcube which fits in memory). • If sparse array, use compressed array addressing: (chunk_id, offset) • Compute aggregates in “multiway” by visiting cube cells in the order which minimizes the # of times to visit each cell, and reduces memory access and storage cost. • Objective find the best order to do multi-way aggregation
C c3 61 62 63 64 c2 45 46 47 48 c1 29 30 31 32 c 0 B 60 13 14 15 16 b3 44 28 B 56 9 b2 40 24 52 5 b1 36 20 1 2 3 4 b0 a0 a1 a2 a3 A Multiway Array Aggregation for MOLAP • After scan {1,2,3,4}: • b0c0 chunk is computed • a0c0 and a0b0 are not computed
C c3 61 62 63 64 c2 45 46 47 48 c1 29 30 31 32 c 0 B 60 13 14 15 16 b3 44 28 B 56 9 b2 40 24 52 5 b1 36 20 1 2 3 4 b0 a0 a1 a2 a3 A Multiway Array Aggregation for MOLAP We need to keep 4 a-c chunks in memory We need to keep a single b-c chunk in memory • After scan 1-13: • a0c0 and b0c0 chunks are computed • a0b0 is not computed (we will need to scan 1-49) We need to keep 16 a-b chunks in memory
Multiway Array Aggregation for MOLAP • Method: the planes should be sorted and computed according to their size in ascending order. • The proposed scan is optimal if |C|>|B|>|A| • MOLAP cube computation is faster than ROLAP • Limitation of MOLAP: computing well only for a small number of dimensions • If there are a large number of dimensions use the iceberg cube computation: process only “dense” chunks
OLAP Cube computation: Bottom-up approach • Computing only the cuboid cells whose count or other aggregates satisfying the condition: HAVING COUNT(*) >= minsup • The motivation is that we don’t want to compute all cells for the cube. Only cells that have the measure above a certain threshold is interesting.
ABCD ABC ABD ACD BCD AB AC AD BC BD CD B C A D all Figure 5: Bottom-up cube computation Bottom-up cube compuation • BUC (Beyer & Ramakrishnan, SIGMOD’99) • Apriori property: • Aggregate the data, then move to the next level • If minsup is not met, stop! • This can be applied to other aggregates like MIN, MAX, SUM by using the concept of monotonicity of a query
Monotonicity of a query • A query is monotonic for a cell C in database D if the condition Q(C) is FALSE imples Q(C’) is FALSE for any subcell C’ of C in database D. • Suppose we have measure M, with every value of M>=0. Suppose, we have a query Q()=SUM(M)>1000 and that for a cell A=a1B=b1, SUM(M1)=600. Q() is FALSE for C. Q() is also FALSE for any subcell of C. Why? Thus Q is monotonic for C. • However for arbitrary queries involving MIN, MAX, SUM, AVG and operators (<,=,>) it is NP-hard to determine whetehr a given query is monotonic at a given cell C.
View monotonicity • A view for a a cell C on set of measures (m1, m2, ..mn} is the set of values assigned for the measures in the set. • For example, a view on cell C on (avg(sales), MAX(sales)) might be (50k, 500k). • A query Q() is view monotonic on a view V if for any cell C in any database D, s.t. V is the view for C, the condition Q is FALSE for C implies Q is FALSE for all C’ subset of C. • Suppose we have a query COUNT(*)>=100 and AVG(salesMilk)<=20. and view V { (COUNT()=500, MIN(salesMilk)=10, MAX(salesMilk)=40), SUM(salesMilk)=19970}. The query Q is view monotonic for view V.
Checking for view monotonicity • Suppose we have a query Q in disjunctive normal form consisting of m conjuncts in J dimensions and K distinct measure attributes. Then the monotonicity of Q for a given view can be tested in O(m(J+klogk)) time. • The idea is to reduce the set of constraints to a set of linear inequalities in terms of COUNT().
Discovery Driven Exploration of OLAP Data cubes • A business analyst is interested in exploring the data cubes, looking for regions of anomalies ie where the value is unexpected. • This is useful in finding problem areas or new opportunities. • For a user to drill down or rollup through the cube to find these interesting regions is laborious and boring . An interesting value may not be so obvious or may lay deep into the data. • Rather, let the system automatically identify such regions and guide the user discovery process.
Surprising cells • A value in a cell of a data cube is surprising if it is significantly different from the anticipated value based on a statistical model. This model computes the anticipated value of a cell in context of its position in the data cube and combines trends along different dimensions that the cell belongs to. • Assume Gaussian distribution, Exceptions fall outside 99% probability: • SurpriseCell = S, if S >2.5 • SurpriseCell = 0, if S <2.5 • Where
Estimating the measure m • The estimate is a function f of contributions of higher-level group-bys. • For example, the estimate for cell at position i on dim A, j on dim B, k on dim C is computed in terms of the top-level group-by, group-by A, group-by B, group-by C, group-by Ab, group-by AC, group-by BC. • Estimate based on trimmed means. • Estimate M for a cell at position (i1,i2,i3,… in) is found by Log M = CG • Where C stands for “contribution” • G is a possible Group-By and • CNone = mean of all values • CDrIr = ADrIr - CNonewhere ADrIr = mean over values along Irth member of dimension DrThus, this denotes how much ADrIr differs from overall average • CDrIrDsIs = ADrIrDsIs- CDrIr - CDsrs - CNone • And so on.
Estimating the measure m (contd) • Coefficients corresponding to any group-by G obtained by subtracting from the average A value all the coefficients from higher level group-bys than G. • Very hard to compute (short cuts and optimizations presented in paper) • Assumes logarithms of measures are distributed as Gaussian, all with the same variance. • These expressions use ‘trimmed’ mean; exclude 25% outliers
Examples of how the estimate is computed • The log of the estimate for (Product=’clothes’, Store=’NJ’, Year=’2001’) is computed as summation of contributions from the following cells (C[Product=’clothes’, store=’NJ’], C[Product=’clothes’, Year=’2001’], C[Store=’NJ’, year=’2001’], C[Product=’clothes’], C[Store=’NJ’], C[Year=’2001’], C[None] or C[all] ) • C[None]=trimmed mean of the 0-D cuboid =trimmed mean of measure M for the set of tuples in the base table. • C[Year=’2001’]=trimmed mean of measure M for all the members in the cell [Year=’2001’] (ie the set of tuples with year=’2001’) – C[None] • C[Product=’clothes’, Year=’2001’]=trimmed mean of measure M for members in the cell [year=’2001’, product=’clothes’-C[Year=’2001’]-C[Product=’clothes’]-C[None]
Computing the standard deviation • Initially tried using root mean square of Actual – Estimate. This provides poor fit for OLAP data • If Poisson distiribution is assumed then the variance is equal to the mean; but this would underestimate the standard deviation here. • The technique set variance=(Estimate)P • Assume Gaussian distribution, using Maximum Likelihood criterion then the value p must satisfy the equation: • (Measure-Estimate)2/(Estimate)p log Estimate = log Estimate
Type of surprise values • SurpriseCell (SelfExp): as defined earlier • SurpriseCellDrill (InExp): Maximum surprise of all cells that can be reached from this cell by drilling down. • SurpriseCellPath (PathExp): Maximum surprise of all cells that can be reached from this cell by drilling down a particular dimension. • To visually depict the degree of exception of each cell, cues such as background color are used.
SQL Extended Aggregation • SQL-92 aggregation quite limited. Many useful aggregates were not part of the standard SQL. • Data cube • Complex aggregates (median, variance) • binary aggregates (correlation, regression curves) • ranking queries (“assign each student a rank based on the total marks” • SQL:1999 OLAP extensions provide a variety of aggregation functions to address above limitations. They are supported by several databases including Oracle and IBM DB2.
The cube operation computes union of group by’s on every subset of the specified attributes Consider the query select item, location, year, sum(revenues)from sales group by cube(item, location, year) This computes the union of eight different groupings of the sales relation: { (item, location, year), (item, location), (item, year), (location, year), (item), (location), (year), ( ) } where ( ) denotes an empty group by list. For each grouping, the result contains the null value for attributes not present in the grouping ie “all”. Extended Aggregation in SQL:1999
Extended Aggregation (Cont.) • The function grouping() can be applied on an attribute. It returns 1 if the value is a null value representing “all”, and returns 0 in all other cases. select item, location, year, sum(revenues), grouping(item) as item-flag, grouping(location) as location-flag, grouping(year) as year-flag from sales group by cube(item, location, year) • Can use the function decode() in the select clause to replace such nulls by a value such as all • Decode syntax: decode ( expression , search , result [, search , result]... [, default] ) • E.g. replace item-name in first query by decode( grouping(item), 1, ‘all’, item)
The rollup construct generates group by on every prefix of specified list of attributes E.g. select item, location, year, sum(revenues)from sales group by rollup(item, location, year) Generates union of four groupings: { (item, location, year), (item, location), (item), ( ) } Multiple rollups and cubes can be used in a single group by clause Each generates set of group by lists, cross product of sets gives overall set of group by lists Extended Aggregation (Cont.)
Analytic Functions • AVG * • CORR * • COVAR_POP * • COVAR_SAMP * • COUNT * • CUME_DIST • DENSE_RANK • FIRST • FIRST_VALUE * • LAG • LAST • LAST_VALUE * • LEAD • MAX * • MIN * • NTILE • PERCENT_RANK • PERCENTILE_CONT • PERCENTILE_DISC • RANK • RATIO_TO_REPORT • REGR_ (Linear Regression) Functions * • ROW_NUMBER • STDDEV * • STDDEV_POP * • STDDEV_SAMP * • SUM * • VAR_POP * • VAR_SAMP * • VARIANCE *
Analytic function syntax • The Syntax of analytic functions is: • Analytic-Function(<Argument>,<Argument>,...)OVER ( <Query-Partition-Clause> <Order-By-Clause> <Windowing-Clause>) • Example: Running total of the employee salary SQL> select eid, deptno, salary, sum(salary) OVER (ORDER BY deptno, eid) as RUNTOTAL from emp; EID DEPTNO SALARY RUNTOTAL ---------- ---------- ---------- ---------- 1 1 50000 50000 3 1 40000 90000 4 2 30000 120000 5 2 60000 180000 2 3 10000 190000 6 3 80000 270000
Ranking is done in conjunction with an order by specification. SQL> select eid, salary, rank() over (order by salary desc) as salRank from emp; EID SALARY SALRANK ---------- ---------- ---------- 6 80000 1 5 60000 2 1 50000 3 7 50000 3 3 40000 5 4 30000 6 2 10000 7 An extra order by clause is needed to ensure they are in sorted order Ranking may leave gaps: e.g. 2 employees share the 3rd salary rank and next one has the rank of 5. dense_rank does not leave gaps, so next dense rank would be 4 Ranking
Ranking (Cont.) • Ranking can be done within partition of the data. SQL> select eid, salary, deptno, rank() over (partition by deptno order by salary desc) as salRak from emp; EID SALARY DEPTNO SALRAK ---------- ---------- ---------- ---------- 1 50000 1 1 7 50000 1 1 3 40000 1 3 5 60000 2 1 4 30000 2 2 6 80000 3 1 2 10000 3 2 • Multiple rank clauses can occur in a single select clause • Ranking is done after applying group by clause/aggregation
Ranking (Cont.) • Other ranking functions: • percent_rank (within partition, if partitioning is done): As an analytic function, for a row R, PERCENT_RANK calculates the rank of R minus 1, divided by 1 less than the number of rows being evaluated (the entire query result set or a partition). • cume_dist cumulative distribution: CUME_DIST calculates the cumulative distribution of a value in a group of values. The range of values returned by CUME_DIST is >0 to <=1. Tie values always evaluate to the same cumulative distribution value. For a row R, assuming ascending ordering, the CUME_DIST of R is the number of rows with values lower than or equal to the value of R, divided by the number of rows being evaluated • row_number (returns a running serial number to a partition of records) non-deterministic in presence of duplicates) • SQL:1999 permits the user to specify nulls first or nulls last. NULLS LAST is the default for ascending order, and NULLS FIRST is the default for descending order • rank ( ) over (order by salarydesc nulls last) as s-rank
For a given constant n, the ranking the function ntile(n) takes the tuples in each partition in the specified order, and divides them into n buckets with equal numbers of tuples. SQL> select salary, ntile(4) over (order by salary) as quartile from emp; SALARY QUARTILE ---------- ---------- 10000 1 30000 1 40000 2 50000 2 50000 3 60000 3 80000 4 Antother example, we can sort employees by salary, and use ntile(3) to find which range (bottom third, middle third, or top third) each employee is in, and compute the total salary earned by employees in each range: select threetile, sum(salary)from (select salary, ntile(3) over (order by salary) as threetilefrom emp) as sgroup by threetile Ranking (Cont.)
LEAD/LAG FUNCTION • LEAD allows to look at rows coming after the current row and return the value as part of the current row. The general syntax of LEAD is shown below: LEAD (<sql_expr>, <offset>, <default>) OVER (<analytic_clause>) The syntax of LAG is similar except that the offset for LAG goes into the previous rows <sql_expr> is the expression to compute from the leading row.<offset> is the index of the leading row relative to the current row.<offset> is a positive integer with default 1.<default> is the value to return if the <offset> points to a row outside the partition range. SELECT deptno, eid, salary, LEAD(salary, 1, 0) OVER (PARTITION BY dept ORDER BY saaryl DESC NULLS LAST) NEXT_LOWER_SAL, LAG(salary, 1, 0) OVER (PARTITION BY dept ORDER BY sal DESC NULLS LAST) PREV_HIGHER_SAL FROM emp ORDER BY deptno, salary DESC;
E.g.: “Given sales values for each date, calculate for each date the average of the sales on that day, the previous day, and the next day” Such moving average queries are used to smooth out random variations. In contrast to group by, the same tuple can exist in multiple windows Window specification in SQL: Ordering of tuples, size of window for each tuple, aggregate function E.g. given relation sales(date, value) select date, sum(value) over (order by date row between 1 preceding and 1 following)from sales Examples of other window specifications: between unbounded preceding and current range between 10 preceding and current row All rows with values between current row value –10 to current value range interval 10 day preceding Not including current row For ROW type windows the definition is in terms of row numbers before or after the current row. For RANGE type windows the definition is in terms of values before or after the current ORDER. Windowing
Windowing (Cont.) • Can do windowing within partitions • E.g. Given a relation transaction(account-number, date-time, value), where value is positive for a deposit and negative for a withdrawal • “Find total balance of each account after each transaction on the account” select account-number, date-time,sum(value) over (partition by account-number order by date-timerow between current row and unbounded preceding)as balancefrom transactionorder by account-number, date-time
OTHER Interesting functions • Variance and standard deviation functions • Covariance function • Correlation function • Linear Regression functions: • Slope • Y-intercept • Goodness of fit