Download

1 / 18
180 likes | 328 Views
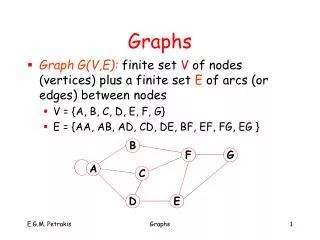
Graphs. CSC 220 Data Structure. Introduction. One of the Most versatile data structures like trees. Terminology Nodes in trees are vertices in graphs. Lines connecting vertices are edges . Each edge is bounded by two vertices at its ends.

E N D
Graphs CSC 220 Data Structure
Introduction • One of the Most versatile data structures like trees. • Terminology • Nodes in trees are vertices in graphs. • Lines connecting vertices are edges. • Each edge is bounded by two vertices at its ends. • Two vertices are said to be adjacent to one another if they are connected by a single edge.
Introduction (Terminology) • Vertices adjacent to a given vertex are called its neighbors. • A path is a sequence of edges. • A graph is said to be connected if there is at least one path from every vertex to every other vertex. • A non-connected graph consists of several connected components.
Connected vs Non-connected graph Connected graph Non-Connected graph
Directed and Weighted Graphs • Undirected graphs - edges don’t have a direction. • Can travel in any direction. • Directed graphs – can traverse in only the indicated direction. • Weight – number that represents physical distance or time or cost between two vertices.
Representing Graphs • Vertices can be represented by a vertex class (i.e.similar to node or link in LL). • Vertex objects can be placed in • an array, • list or • other data structure. • Graphs can be represented using adjacency matrix or adjacency list.
Representing Graphs • Adjacency matrix – 2-dimensional array in which elements indicate whether an edge is present between two vertices. • Edge is represented by 1. • Or Edge is represented by weight • Adjacency List – array of lists or list of lists. • Each individual list shows what vertices a given vertex is adjacent to.
Search • Fundamental operation, to find out which vertices can be reached from a specified vertex. • An algorithm that provides a systematic way to start at a specified vertex and then move along edges to other vertex. • Every vertex that is connected to this vertex has to be visited at the end. • Two common approaches : • depth-first (DFS) and • breadth-first search (BFS).
DFS • Can be implemented with a stack to remember where it should go when it reaches a dead end. • DFS goes far way from the starting point as quickly as possible and returns only if it reaches a dead end. • Used in simulations of games
DFS There are 3 rules -- start with a vertex R1 a. go to any vertex adjacent to it that hasn’t yet been visited b. push it on a stack and mark it R2 if can’t follow R1, then possible pop up a vertex off the stack R3 if can’t follow R1 and R2, you’re done
DFS • Steps: -- start with a vertex -- visit it -- push it on a stack and mark it -- go to any vertex adjacent to it that hasn’t yet been visited -- if there are no unvisited nodes, pop a vertex off the stack till you come across a vertex that has unvisited adjacent vertices
Breadth-First Search BFS • Implemented with a queue. • Stays as close as possible to the starting point. • Visits all the vertices adjacent to the starting vertex
BFS • Steps: -- start with visiting a starting vertex -- visit the next unvisited adjacent vertex, mark it and insert it into the queue. -- if there are no unvisited vertices, remove a vertex from the queue and make it the current vertex. -- continue until you reach the end.
MST • DSF application -> display visited edges • Example Application • Reduce paths and pins in VLSI (Chip) design and fabrication