Download

1 / 27
270 likes | 363 Views
Towards a Science of Knowledge Base Performance Analysis. Mike Dean mdean@bbn.com 4 th International Workshop on Scalable Semantic Web Knowledge Base Systems (SSWS2008) Karlsruhe, Germany 27 October 2008 http://asio.bbn.com/2008/10/iswc2008/mdean-ssws-2008-10-27.ppt. Outline. Metrics

E N D
Towards a Science ofKnowledge BasePerformance Analysis Mike Dean mdean@bbn.com 4th International Workshop on Scalable Semantic Web Knowledge Base Systems (SSWS2008) Karlsruhe, Germany 27 October 2008 http://asio.bbn.com/2008/10/iswc2008/mdean-ssws-2008-10-27.ppt
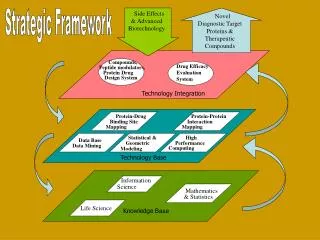
Outline • Metrics • ParliamentTM Knowledge Base • Analysis of the Billion Triples Challenge Corpus • Conclusions
Metrics • I find it helpful to compare latencies in terms of machine instructions • 3 GHz processor ~ 3 billion instructions/sec • Subroutine call ~ 10 instructions • Round-trip local host inter-process communication ~ 100,000 instructions • Reading 4K from a 7200rpm SATA drive ~ 45 million instructions • Speed of light • 4 inches ~ 1 instruction • Round-trip US transcontinental ~100 million instructions • Round-trip geosynchronous satellite ~ 1.5 billion instructions • It pays to have your data in memory whenever possible
Usual Triple StoreImplementation Approaches • RDBMS • Inherent scalability and ACID properties • Generic, table-per-class, or table-per-property • Column stores (VLDB 2007 Best Paper) • B-Trees • Multiple indexes on spo, pos, osp • Can easily be distributed • … • Most implementations “intern” URIs and literal values into fixed-length integers
(Ancient) History • Several mainframe technologies I used as a teenager left a lasting impression • Multics • Memory-mapped filesystem (survives as Unix mmap) • CODASYL (Network) DBMSs • Linked-list “chains” with hashed lookups • Page allocation and locking • Similar structure to later OODBMSs (e.g. Objectivity), which added inheritance
ParliamentTM • Lightweight embedded triple store • Started as DAML DB in September 2001 • Multiple re-implementations over the years • Simple rule engine added • Now part of AsioTM tool suite • Still the primary triple store used in BBN projects • Will soon be released as open source under BSD license on SemWebCentral.org
Java C# C/C++ Drive parser R D Q L R D Q L R Q L S e R Q L ARP parser Jena 1 model Sesame SAIL Drive model Java Native Interface Platform Invoke Raptor parser rules accessors DAML DB Sleepycat Berkeley DB Embedding • Embedded storage layer • Used with higher-level parsers, APIs, query, and reasoning mechanisms • Efficient, persistent, and scalable • Memory mapped files (same as OS virtual memory)
Example <rdf:RDF xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#' xmlns='http://www.daml.org/2001/01/gedcom/gedcom#' > <Individual rdf:ID='thornton'> <name>Thornton Dean</name> <sex>M</sex> <birth> <Birth> <date>1844-05-10</date> <place rdf:resource="&fips55;VA#c165"/> </Birth> </birth> </Individual> <Individual rdf:ID='sol'> <name>Solomon Job Hensley</name> <sex>M</sex> <birth> <Birth> <date>1855-04-12</date> <place rdf:resource="&fips55;VA#c165"/> </Birth> </birth> </Individual> </rdf:RDF>
LUBM Results [Rohloff, Dean, Emmons, Ryder, Sumner SSWS2007]
Desires • A means of formally comparing performance between Parliament, RDBMS, and B-Tree implementations • I don’t know how to do this • Probably based on counts of some shared primitive operations • Work on formal system and/or database performance models should be relevant here
Billion Triples Challenge • A new Semantic Web Challenge track in 2008 • Do “something interesting” with a large subset of a billion provided triples • 12 real web data sets • Not a scientific sample • Enough to be interesting and probably representative • Stable snapshot • Our analysis initially arose from discussing a possible application • We now know “yes, there is enough data to support what we wanted to do” • Tools and techniques should be generally applicable to other corpora
Billion Triples Corpus http://www.cs.vu.nl/~pmika/swc/btc.html
Analysis • Stream processing of the compressed data set archives • Statement counts • Datatype, language, predicate, and type counts • Use of RDF, RDFS, OWL, FOAF, and other vocabularies • (May include duplicate statements) • Load each dataset into its own Parliament KB • (Eliminates duplicates within dataset) • (Both programs used code based on Peter Mika’s WARC example with the OpenRDF RIO parser and no inference) • Process the statement and resource tables • Mark each node as resource and/or literal • URI, blank node, and literal counts • Chain length statistics and histograms • (Parliament worked very well here. Each operation took 1-736 seconds.)
Statements • Statement (subject, predicate, object) • Resource object • rdf:type predicate • Other predicate • Literal object • rdf:datatype • Plain literal • xml:lang • Neither datatype nor language
Resources and Literals • Node • Resource • URI • Blank Node • Literal
Chain Lengths • How long are the linked-list chains used by Parliament? • How many statements share the same subject, predicate, or object? • Histograms proved unwieldy • Presenting summary statistics instead • rdf:type statements significantly impact results
RDF/RDFS/OWL Usage • 80,309,558 rdf:type statements in 11 data sets • 4,033,540 rdfs:subClassOf statements in 6 data sets • 2,988,396 owl:Class instances in 6 data sets • 1,492,214 rdf:_1 statements in 7 data sets • 1,042,032 owl:Restriction instances in 5 data sets • 480,771 owl:sameAs statements in 9 data sets • 299,962 rdfs:Class instances in same 6 data sets as owl:Class • ~238,000 reified statements in 4 data sets • 50,482 instances of rdf:Bag in 5 data sets • 22,154 instances of owl:Ontology in 5 data sets • 14,913 owl:import statements in 3 data sets • 83 rdf:_2000 statements in 3 data sets • 1 rdf:_10763 statement in 1 data set
Popular Vocabularies • FOAF • 29,308,169 Person instances in 7 data sets • 25,864,527 knows statements in 6 data sets • Dublin Core • 43,591,844 title statements in 7 data sets • 4,416,716 date statements in 6 data sets • Geospatial • 7,075,380 wgs84_pos:lat statements in 9 data sets • 4,436 georss:point statements in 5 data sets • SKOS • 6,619,912 subject statements in 4 data sets • 403,912 Concept instances in 4 data sets • RSS 1.0 • 2,893,750 item instances in 6 data sets • OWL-S • 92 0.9-1.2 Profiles in 3 data sets • OWL-Time • No usage?
Errors • 95,937 Java exceptions • Lots of bad languages and datatypes • Lots of namespace/URI typos/confusion • Slightly different statement counts, due to exceptions, duplicates, etc. • 1,063,616,774 statements (4% less)
Next Steps • Increased factoring of rdf:type statements • How many rdf:type’s are associated with each resource? • Compare to LUBM synthetic data • Analyze the combined corpus • Determine how many URIs are (still) resolvable? Start with the predicates. • Discussion of specific datasets • SemTech 2009 submission
Data Set Characterization • Metrics that can impact selection/tuning of KB implementations • Statement count • Number of classes and predicates • Statements per subject/predicate/object • Degree of interconnectedness (percentage of non-literal statements, with/without rdf:type) • RDFS and OWL reasoning employed • Use of reification
Conclusions • Needs • Better means of formally characterizing KB implementations and data sets • Please help!
More Information • http://parliament.projects.semwebcentral.org • Parliament download (soon) • http://asio.bbn.com/2008/10/btc/ • Full raw Billion Triples Corpus analysis results