Download

1 / 15
150 likes | 283 Views
Create and assess protein networks through molecular characteristics of individual proteins. Yanay Ofran et al. ISMB ’06 Presenter: Danhua Guo 12/07/2006. Roadmap. Motivation Introduction Methods Results and Discussion Conclusion. Motivation.

E N D
Create and assess protein networks through molecular characteristics of individual proteins Yanay Ofran et al. ISMB ’06 Presenter: Danhua Guo 12/07/2006
Roadmap • Motivation • Introduction • Methods • Results and Discussion • Conclusion
Motivation • Study of biological systems relies on network topology. • Integrating protein information into the network enhance the analysis of biological systems.
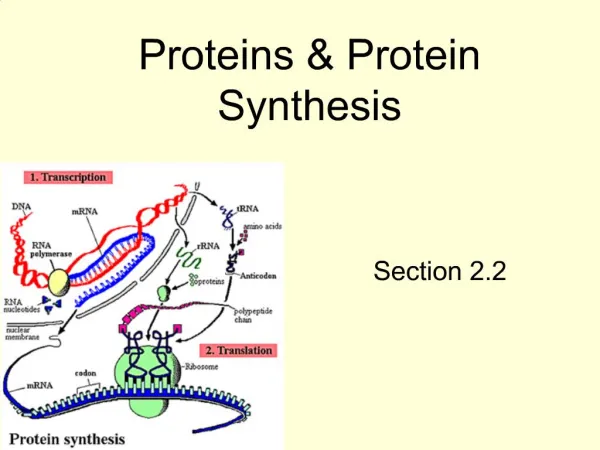
Introduction • Protein-Protein Interaction (PPI) Network • Help identify process or functions • Major problem • Generation problem • Experimental errors: should not be in the network • “In vitro”: should be include in the network • Data representation problem • Essential connection between PPI and protein
Introduction • An ideal framework • Macro level: network topology • Micro level: characteristics of each protein • Localization • Functional annotation
Introduction • Protein interaction Network Assessment Tool (PiNAT)
Methods • Large-scale Assessment of PPIs • Based on localization • Based on GO annotation (if applicable) • Automatic generation of networks • Get submitted list of proteins from user • Search DIP and IntAct • Display of networks in the cellular context • Alzheimer’s disease related pathway
Methods • Localization criteria • LOCtree: classify eukaryotic proteins (60%) • Threshold: confidence score >=4 • PHDhtm: predict transmembrane helices (7%) • Threshold: average score among 20 reliable predictions >8.5 • Experiment on 4800 interactions (2191 proteins) • High-confidence prediction: 2312 (1482 proteins) • Total protein pairs: 1,097,421 • Binomial approximation to the cumulative hypergeometric probability distribution to get a p-value for over and under representation
Methods • GO criteria • The functionality annotation of a protein • Distance between 2 GO terms measure the similarity • m,n: respective numbers of annotations in i and j • simGo: GO similarity defined by Lord et al. • Ck, Cp: respective individual annotation in protein i and j • Cjmax: Ck’s most similar term in j • Cimax: Cp’s most similar term in i
Methods • Display of networks in the cellular context • Based on LOCtree and PHDhtm predictions • Generate Graph Markup Language (GML) • Localization overide rule: • High PHDhtm > High LOCtree > Low PHDhtm > Low LOCtree
Results • Interactions across subcellular compartments • Intra-compartment interactions: high score • Distant compartment: low score • Nearby compartment: likely
Results • Likely and unlikely interactions across GO • Likely: >3.25 • Unlikely: <1.3 • Neutral: else
Result • Alzheimer in the perspective of PiNAT • Reflects the unclarity regarding Amyloid beta A4 protein (APP) ’s localization • APP interacts extensively with almost every compartment of the cell
Result • APP’s role in Alzheimer • APP-related PPI deemed “unlikely” • Conflicts between 2 scoring systems
Conclusion • Molecular knowledge and network structure can enhance our understanding of biological processes. • PiNAT is efficient and meaningful.