Download

1 / 109
1.09k likes | 1.35k Views
第七章图 ( Graphs). 图的基本概念 图的存储表示 图的遍历 最小生成树 活动网络 最短路径. v 1. v 2. v 3. v 4. v 5. 图例. 结点. 边 : (v2, v5). 图的构成: 结点集 : V={v 1 ,v 2 ,v 3 ,v 4 ,v 5 }, 边集 : E={(v 1 ,v 2 ),(v 1 ,v 4 ),(v 2 ,v 3 ),(v 2 ,v 5 ),(v 3 ,v 4 ),(v 3 ,v 5 )}. v 1. v 2. v 3. v 4. 图例. 有向边 <v3, v4>

E N D
第七章图(Graphs) • 图的基本概念 • 图的存储表示 • 图的遍历 • 最小生成树 • 活动网络 • 最短路径
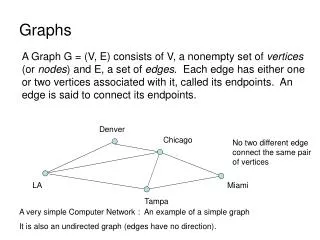
v1 v2 v3 v4 v5 图例 结点 边: (v2, v5) • 图的构成: • 结点集:V={v1,v2,v3,v4,v5}, • 边集: • E={(v1,v2),(v1,v4),(v2,v3),(v2,v5),(v3,v4),(v3,v5)}
v1 v2 v3 v4 图例 有向边<v3, v4> V3:始点, v4: 终点 • 图的构成: • 结点集:V={v1,v2,v3,v4}, • 有向边集:E={<v1,v3>,<v1,v2>,<v3,v4>,<v4,v1>}
v1 v2 v1 v2 v3 v3 v4 v4 v5 图的概念 图是由顶点(vertex)集合及顶点间的关系集合组成的一种数据结构: Graph=( V, E ) 其中 V = { x | x 某个数据对象} 是顶点的有穷非 空集合; E = {<x, y> | x, y V } 是顶点之间关系的有穷集合,也叫做边(edge)的集合。
v1 v2 v1 v2 v3 v3 v4 v4 v5 • 有向图G1 V1={v1,v2,v3,v4}, E1={<v1,v3>,<v1,v2>,<v3,v4>,<v4,v1>} • 无向图G2 V2={v1,v2,v3,v4,v5}, E2={<v1,v2>,<v1,v4>,<v2,v3>,<v2,v5>,<v3,v4>,<v3,v5>, <v2,v1>,<v4,v1>,<v3,v2>,<v5,v2>,<v4,v3>,<v5,v3>} 或者 E2={(v1,v2),(v1,v4),(v2,v3),(v2,v5),(v3,v4),(v3,v5)} (a) G1=(V1,E1) (b) G2 = (V2, E2)
v1 v2 v3 v4 图的术语 v1的出度 OD(v4) = 1 v3邻接到v4 v4的入度 ID(v4)=1 性质: 入度之和 = 出度之和 = 边数 结点的度数: TD(v) = ID(v)+OD(v)
v1 v2 v3 v4 v5 v1和v4互为邻接点 v4的度数为2 TD(v4)=2 度数之和 = 边数的二倍 (因为每个边“贡献”了两个度数)
子图设有两个图 G=(V, E) 和 G’=(V’, E’)。若 V’ V 且 E’E, 则称 图G’ 是 图G 的子图。 • 权某些图的边具有与它相关的数, 称之为权。这种带权图叫做网络。 • 完全图若有 n 个顶点的无向图有 n(n-1)/2 条边, 则此图为完全无向图。有 n 个顶点的有向图有n(n-1) 条边, 则此图为完全有向图。
v1 v2 v3 v4 路径: (1) <v1, v3>, <v3, v4> (简单路径) (2) <v1, v3>, <v3, v4>, <v4, v1> (环) (3) <v3, v4>
路径:在图 G=(V, E) 中, 若存在边的序列 (vi, vp1)、(vp1, vp2)、...、(vpm, vj) 则称顶点序列 ( vi vp1 vp2 ... vpm vj ) 为从顶点vi 到顶点 vj 的路径。 • 路径长度 • 非带权图的路径长度是指此路径上边的条数。 • 带权图的路径长度是指路径上各边的权之和
简单路径若路径上各顶点 v1,v2,...,vm 均不互相重复, 则称这样的路径为简单路径。 • 回路若路径上第一个顶点 v1 与最后一个顶点vm 重合, 则称这样的路径为回路或环。 • 连通图与连通分量在无向图中, 若从顶点v1到顶点v2有路径, 则称顶点v1与v2是连通的。 • 如果图中任意一对顶点都是连通的, 则称此图是连通图。 • 非连通图的极大连通子图叫做连通分量。
v1 v2 v3 v1 v2 v4 v5 v3 v4 v5 生成树 • 强连通图 在有向图中, 若对于每一对顶点vi和vj, 都存在一条从vi到vj和从vj到vi的路径, 则称此图是强连通图。 • 生成树一个连通图的生成树是它的极小连通子图,在n个顶点的情形下,有n-1条边。
图的存储结构 存储原则: 存储结点集和边集的信息. (1)存储结点集; (2)存储边集: 存储每两个结点是否有关系。 邻接矩阵
图的存储结构 有向图的邻接矩阵
邻接矩阵表示法 在图的邻接矩阵表示中: • 有一个记录各个顶点信息的顶点表, • 还有一个表示各个顶点之间关系的邻接矩阵。 #define MAX_VERTEX_NUM 20 //最大顶点个数 typedef struct { VertexType vexs[MAX_VERTEX_NUM]; //顶点向量 int arcs [MAX_VERTEX_NUM] [MAX_VERTEX_NUM] ; //邻接矩阵 int vexnum,arcnum; //图的当前顶点数和弧数 }MGraph;
容易计算结点的度数; • 容易判定两个结点间是否有边相连; • 容易判定结点之间是否有路径相连(计算Am); • 对于有向图,需要n个单元存储结点数据, n*n个单元存储邻接矩阵; • 无向图的邻接矩阵是对称的, 可以压缩存储; • 存储量与结点数有关, 与边数无关; 若边数<<n2, 则邻接矩阵是稀疏矩阵;
邻接表 每个结点拉出一个邻接边链表 (以此结点为始点的所有邻接点) 所有结点存储与一个表中
以A为始点的边链 以A为终点的边链
图的邻接表存储表示 #define MAX_VERTEX_NUM 20 typedef struct ArcNode{//单链表结点结构 int adjvex;//该弧所指向的顶点的位置 struct ArcNode *nextarc;//指向下一条弧的指针 InfoType *info; //该弧相关信息的指针 }ArcNode; typedef struct VNode {//顶点结构 VertexType data;//顶点信息 ArcNode *firstarc; //指向第一条依附该顶点的弧的指针 }VNode,AdjList[MAX_VERTEX_NUM]
Typedef struct { //邻接表结构 AdjList vertices; int vexnum,arcnum;//图的当前顶点数和弧数 }ALGraph;
邻接表的特点 • 顶点vi的度恰为第i个链表中的结点数; • 在有向图中,第i个链表(出边表)中的结点个数是顶点的出度; • 求入度必须遍历整个邻接表: 在所有链表中其邻接点域的值为i的结点的个数是顶点vi的入度。 • 为了求入度的便利, 可以建立逆邻接表, 即链表为入边表;
设图中有 n 个顶点,e 条边,则用邻接表表示无向图时,需要 n 个顶点结点,2e 个边结点;用邻接表表示有向图时,若不考虑逆邻接表,只需 n 个顶点结点,e 个边结点。
邻接表 (B,D)边出现在D的边链表中 (B,D)边出现在B的边链表中 如果以边为处理对象, 如删除一个边, 则需扫描每个结点的边表, 找到同一条边.
邻接多重表 • 将邻接表中代表同一个边的结点合并; 边表合并为多重表; • 在邻接多重表中,每一条边只有一个边结点, 为有关边的处理提供了方便。
边结点结构: mark ivex jverx ilink jlink mark:记录是否处理过的标记; ivex, jvex: 该边的两顶点位置; ilink:指向下一条依附于顶点ivex的边; jlink:指向下一条依附于顶点jvex的边。
mark ivex jverx ilink jlink typedef emnu {unvisited,visited} Visited; typedef struct EBox{ Visited mark; //访问标记 int ivex,jvex;//该边依附的两个顶点的位置 struct EBox *ilink,*jlink;//分别指向依附这两个顶点的下一条边 InfoType *info; //该边信息指针 }EBox;
顶点结点的结构: data: 存放与该顶点相关的信息, firstedge: 指示第一条依附于该顶点的边的指针 data firstedge typedef struct VexBox{ VertexType data; EBox *firstedge //指向第一条依附该顶点的边 }VexBox;
typedef struct { VexBox adjmulist[MAX_VERTEX_NUM]; int vexnum,edgenum; //无向图的当前顶点数和边数 } AMLGraph;
图的抽象数据类型 ADT Graph{ 数据对象V: V是具有相同特性的数据元素的顶点集。 数据关系R: R={VR} VR={<v,w> | v,w∈V且P(v,w) ,谓词 P(v,w) 定义了弧<v,w>的意义或信息 }
基本操作P: CreateGraph(&G,V,VR); 初始条件:V是图的顶点集,VR是图中弧的集合。 操作结果:按V和VR的定义构造图G。 DestroyGraph(&G); 初始条件:图G存在。 操作结果:销毁图G。 FirstAdjVex(G,v); 初始条件:图G存在,v是G中某个顶点。 操作结果:返回v的第一个邻接顶点。若顶点在G中 没有邻接顶点,则返回“空”。
NextAdjVex(G,v,w); 初始条件:图G存在,v是G中某个顶点, w是v的邻接顶点。 操作结果:返回v的(排在w之后的)下一个邻接顶点。 若w是v的最后一个邻接点,则返回“空”。 InsertVex(&G,v); 初始条件:图G存在,v和图中顶点有相同特征。 操作结果:在图G中增添新顶点v。 DeleteVex(&G,v); 初始条件:图G存在,v是G中某个顶点。 操作结果:删除G中顶点v及其相关的弧。
InsertArc(&G,v,w); 初始条件:图G存在,v和w是G中两个顶点。 操作结果:在G中增添弧<v,w>, 若G是无向的则还增添对称弧<w,v>。 DeleteArc(&G,v,w); 初始条件:图G存在,v和w是G中两个顶点。 操作结果:在G中删除弧<v,w>, 若G是无向的则还删除对称弧<w,v>。
DFSTraverse (G,v,Visit()); 初始条件:图G存在,v是G中某个顶点, Visit是顶点的应用函数。 操作结果:从顶点v起深度优先遍历图G, 并对每个顶点调用函数Visit一次且仅一次。 BFSTraverse (G,v,Visit()); 初始条件:图G存在,v是G中某个顶点, Visit是顶点的应用函数。 操作结果:从顶点v起广度优先遍历图G, 并对每个顶点调用函数Visit一次且仅一次。 }ADT Graph
v0 v1 v3 v2 v4 v5 6 5 1 5 5 6 4 2 3 6 习题 • 试分别在邻接矩阵和邻接表表示的图上实现运算FirstAdjVex(G,v)和NextAdjVex(G,v,w); • 试根据邻接矩阵建立图的邻接表表示。 • 画出下图的邻接表表示:
v1 v3 v2 v4 v5 v6 v7 v8 图的遍历 图的遍历:从某个结点出发,访问图的每个结点恰好一次。 深度优先从v开始遍历: 1)访问v,访问v的邻接点w1,访问w1的邻接点w2, …,直至wm的邻接点全被访问过; 2)退回最近一个有未访问邻接点的wk, 重复1)直至所有与v连通的结点均被访问过。
v1 v3 v2 v4 v5 v6 v7 v8 图的深度优先遍历 深度优先从v1开始遍历:
为了避免重复访问,设置一个标志顶点是否被访问过的辅助数组 visited [ ]: • 它的初始状态为 0; • 若顶点 i被访问,则置 visited [i] 为 1,防止它被多次访问。 深度优先从v开始遍历: 1)访问v; 2)依次深度优先从v的未被访问的邻接点遍历, 直至所有与v连通的结点均被访问过。
void DFSTraverse(Graph G,Status(*Visit)(int v)){ //对图G作深度优先遍历。 VisitFunc=Visit; //使用全局变量VisitFunc,使DFS不必设函数指针参数 for(v=0;v<G.vexnum;++v) visited[v]=FALSE; //访问标志数组初始化 for(v=0;v<G.vexnum; ++v) if( !visited[v] ) DFS(G,v); //对尚未访问的顶点调用DFS }
void DFS (Graph G,int v){ //从第v个顶点出发递归地深度优先遍历图G。 visited[v]=TRUE; VisitFunc(v); //访问第v个顶点 for(w =FirstAdjVex(G, v); w>=0; w =NextAdjVex(G, v, w)) if(!visited[w]) DFS(G,w); //对v的尚未访问的邻接顶点w递归调用DFS }
算法分析 void DFS (Graph G,int v){ //从第v个顶点出发递归地深度优先遍历图G。 visited[v]=TRUE; VisitFunc(v); //访问第v个顶点 for(w =FirstAdjVex(G, v); w>=0; w =NextAdjVex(G, v, w)) if(!visited[w]) DFS(G,w); //对v的尚未访问的邻接顶点w递归调用DFS } 每个结点一次 循环工作量: 寻找结点v的邻接点 每个结点最多调用一次
时间复杂度: • 访问每个结点的时间:O(n); • 寻找每个结点的所有邻接结点工作量; • 设图中有 n 个顶点,e 条边。 • 如果用邻接表表示图,沿Firstedge link 链可以找到某个顶点 v 的所有邻接顶点 w。 • 无向图有 2e 个边结点,有向图有e个边,所以扫描边的时间为O(e); 时间复杂度为O(n)+O(e)=O(n+e); • 如果用邻接矩阵表示图,则查找每一个顶点的所有的边,所需时间为O(n),则遍历图中所有的顶点所需的时间为O(n)+O(n2 ) = O(n2).
v1 v3 v2 v4 v5 v6 v7 v8 广度优先遍历 基本思想 • 访问v1; • 访问v1的邻接点w1,w2,…,wm; • 依次访问w1, w2, …的未被访问的邻接点, • 如此进行下去,直至访问完所有结点。 • 算法的实现需要 • 设置一个数组visited[]标记结点是否访问过; • 设置一个队列纪录当前层访问的结点以备访问下一层结点。
基本思想 • 访问v1; • 访问v1的邻接点w1,w2,…,wm; • 依次访问w1, w2, …的未被访问的邻接点, • 如此进行下去,直至访问完所有结点。 • 取一个结点未访问结点v, 访问v,标记,入队; • (访问 v的所有邻接点):取队头元素,每次取v的下一个未访问的邻接点访问,标记并入队; • 重复2, 直至队列空; • 如果图中仍然有未访问的结点,重复1, 直至所有结点均已标记为访问过。
void BFSTraverse(Graph G,Status(*Visit)(int v)){ //按广度优先非递归遍历图G。 //使用辅助队列Q和访问标志数组visited。 for(v=0;v<G.vexnum;++v) visited[v]=FALSE; InitQueue(Q); //置空的辅助队列Q
for(v=0; v<G.vexnum; ++v) if(!visited[v] ) { //v尚未访问 visited[v]=TRUE;visit(v); EnQueue(Q,v); //v入队列 while(!QueueEmpty(Q)) { DeQueue(Q,u) //队头元素出队并置为u for(w=FirstAdjVex(G,u); w; w=NextAdjVex(G, u, w)) if(!Visited[w]) { //w为u的尚未访问的邻接顶点 visited[w]=TRUE; Visit(w); EnQueue(Q,w); }//if }//while }//if }//BFSTraverse 复杂度与深度优先相同
v1 v3 v2 v4 V1 v5 v6 v7 V1 V2 V3 V2 V3 v8 V4 V6 V4 V5 V6 V7 V8 V7 V8 V5 图的连通性 • 对于连通的无向图,从一个结点出发可以访问所有结点;结点与遍历时通过的边构成图的生成树; 深度优先生成树 广度优先生成树
A D G L F C A B E K I M C D E F J B G H H I K J L M • 对于不连通的无向图,则需从多个顶点出发访问;结点与遍历时经过的边构成生成树林。 voidDFSTraverse(Graph G,Status(*visit)(int v)) { visitFunc=Visit; for(v=0;v<G.vexnum;++v) visited[v]=FALSE; for(v=0;v<G.vexnum; ++v) if( !visited[v] ) DFS(G,v); } 每次循环 生成一棵树 void DFS (Graph G,int v){ visited[v]=TRUE;VisitFunc(v); for(w =FirstAdjVex(G,v); w>=0; w =NextAdjVex(G, v, w)) if(!visited[w]) DFS(G,w); } 深度优先生成森林
T q p void DFSForest (Graph G,CSTree &T){ //建立无向图G的深度优先生成森林的孩子兄弟链表T。 T=NULL; for( v=0; v<G.vexnum; ++v) visited[v]=FALSE; for( v=0;v<G.vexnum; ++v) if ( !visited[v]){ //第v顶点为新的生成树的根结点 p=(CSTree)malloc(sizeof(CSNode)) //分配根结点 *p={GetVex(G,v),NULL,NULL};//给该结点赋值 if(!T) T = p; //是第一棵生成树的根 else q->nextsibling = p ; //是其它生成树的根(前一棵的根的“兄弟”) q = p; //q指示当前生成树的根 DFSTree(G,v,p); //建立以p为根的生成树 } }//DFSForest