Download

1 / 90
920 likes | 1.28k Views
1- Experimentos com Um Único Fator: A Análise de Variância (ANOVA). Fator é uma variável independente em estudo, por exemplo, solventes, aditivos. Estes fatores geralmente envolvem diversos níveis. A ANOVA é utilizada para verificar se

E N D
1- Experimentos com Um Único Fator: A Análise de Variância (ANOVA) Fator é uma variável independente em estudo, por exemplo, solventes, aditivos. Estes fatores geralmente envolvem diversos níveis. A ANOVA é utilizada para verificar se existem diferenças significativas entre os níveis dos fatores (tratamentos). Aqui assume-se que o delineamento é completamente casualizado. Estes experimentos só podem ser realizados quando as unidades experimentais são homogêneas. Por exemplo, 12 leitões da mesma raça, mesmo sexo, mesma idade e com pesos iniciais próximos. 1.1 Um exemplo. Uma bioquímica (Tecnologia de Alimentos) está interessada em estudar a extração de pigmentos naturais, com aplicação como corante em alimentos. Numa primeira etapa tem-se a necessidade de escolher o melhor solvente extrator. A escolha do(s) melhor(es) solventes foi realizada através da medida da absorbância de um pigmento natural do fruto de baguaçú. Fator = solventes; a=5 níveis; n=5 repetições.
Unidade experimental: 10 gramas de polpa do fruto de baguaçú. Casualização: a partir de 1 kg de polpa, foram sendo retiradas amostras de 10gr, onde foram aplicados os tratamentos, numa ordem aleatória. As observações obtidas de absorbância são mostradas na tabela 1.1 Tabela 1.1 Dados de absorbância de cada um dos solventes
Desenho esquemático para absorbância de cada solvente • Existe uma forte suspeita de que o tipo de solvente esteja afetando a absorbância. • Distribuições simétricas. • Sem presença de valor discrepante.
1-2 A Análise de Variância Objetivo: testar se existe diferenças nas médias de absorbância para os a=5 tipos (níveis) de solventes.
Modelo estatístico (one-way): i=1,2,...,a j=1,2,...,n yij= é a ij-ésima observação; é uma constante para todas as observações (média geral); i é o efeito do i-ésimo tratamento; ij é o erro aleatório(erros de medida, fatores não controláveis, diferenças entre as unidades experimentais, etc.). Pressuposições: 1) os erros aleatórios são independentes; 2) os erros aleatórios são normalmente distribuídos; 3) os erros aleatórios tem média 0 (zero) e variância 2; 4) a variância, 2, deve ser constante para todos os níveis do fator. 5) as observações são adequadamente descritas pelo modelo Ou, então:
Duas situações: 1) modelo de efeito fixo (níveis selecionados pelo pesquisador); 2) modelo de efeito aleatório (amostra aleatória). Neste caso, vamos estimar e testar hipóteses sobre a variabilidade de i 1-3 Análise de Variância do Modelo de Efeito Fixo Hipóteses: H0: 1= 2=...= a H1: i j para pelo menos um par (i,j) 1-3.1 Decomposição da soma de quadrados total Corrigida para a média SSTotal= SSTratamentos+ SSErro
Considere a SQErro A parte dentro dos colchetes dividida por (n-1) é a variância do tratamento i. A variância combinada dos a tratamentos é: 7 7 7
Considere a SQTrat A parte dentro dos colchetes dividido por a-1 é a variância entre tratamentos. 8 8 8
Graus de liberdade: SSTotal tem an-1 graus de liberdade; SSTratamentos tem a-1 g.l. e SSerro tem a(n-1) g.l. Quadrados médios: Esperanças dos quadrados médios: Teste de hipótese:
1-3.2 Análise Estatística F0 = QMTratamentos / QMErro Critério para rejeição de H0: F0 > F,a-1,N-a . Pode-se usar o valor p (em inglês: p-value: É a probabilidade de rejeitar a hipótese nula devido a variações aleatórias. Exemplo: para = 5%, assim, se o valor p for menor do que 0,05 rejeitar H0, caso contrário, não rejeitar H0. Fórmulas operacionais para o cálculo das somas de quadrados:
Valor p N = an
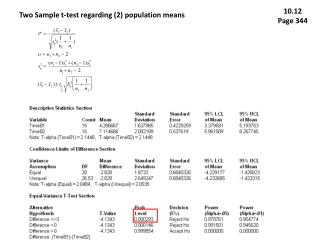
Exemplo 1-1. O experimento de absorbância Coeficiente de variação (CV)= 5,19% F.05;4;20=2,87 F,01;4;20=4,43 Rejeita-se H0, e concluímos que as médias de tratamentos diferem entre si; os solventes afetam signifi- cativamente as médias de absorbância.
1-3.3 Estimação dos parâmetros do modelo Estimativas da média geral e dos efeitos dos tratamentos: Estimativa pontual de i: dado i= + i, temos: Um intervalo de confiança para i é dado por:
Intervalo de confiança para a diferença entre qualquer duas médias i-j: Exemplo 1-3. Dados de absorbância
Critério de rejeição de H0: i.-j..= 0. Se o intervalo de confiança contém o valor da hipótese nula não se rejeita a hipótese de nulidade, caso contrário rejeita-se a hipótese. 1-3.4 Dados desbalanceados. O número de observações dentro de cada tratamento é diferente. Nesse caso, as SQTotal e SQTratamentos são dadas por:
1-4 Diagnóstico do Modelo Verificar se as pressuposições básicas do modelo são válidas. Isso é realizado através de uma análise de resíduos. Define-se o resíduo da ij-ésima observação como: 1-4.1 A suposição de normalidade Vamos usar o gráfico normal de probabilidades: sob normalidade dos erros, estes devem seguir uma reta de 45o.
Alguns valores negativos dos resíduos(mais extremos) deveriam ser maiores; alguns valores positivos dos resíduos deveriam ser menores, com exceção do último valor que deveria ser maior. • Contudo este gráfico não é grosseiramente não normal. • Existe um resíduo que é muito maior que os demais, este valor é denominado outlier. É um problema sério. Deve-se fazer uma investigação sobre esse valor (erro de cálculo, digitação, algum fato experimental). Só eliminar um outlier se tiver uma justificativa não estatística, caso contrário, fazer duas análises: uma com e outra sem o outlier. Usar métodos não paramétricos. Transformação. • Outlier: dij=eij/RQ(QMErro). Se algum resíduo padronizado for maior do que |3| ele é um outlier. Obs. RQ = raíz quadrada.
1-4.2 Gráfico de resíduos no tempo Para verificar se existe correlação entre os resíduos. Uma tendência de ter resíduos positivos e negativos indica uma correlação positiva. Isto implica que a suposição de independência dos erros foi violada. Isto é um problema sério, e até difícil de resolver. Se possível evitar este problema. A casualização adequada pode garantir a independência.
1-4.3 Gráfico dos resíduos versos valores preditos A distribuição dos pontos é aleatória. Útil para verificar se as variâncias são heterogêneas (forma de megafone). Na presença de heterogeneidade de variâncias é usual aplicar uma transformação nos dados. Pode-se usar os testes não-paramétricos. A heterogeneidade de variância também ocorre nos casos de distribuições assimétricas, pois a variância tende a ser função da média.
Algumas transformações para homogeneizar as variâncias são dadas a seguir. As conclusões são realizadas para os dados transformados. Poisson: y*=y ou y*=1+y; dados de contagens, variância é função da média. Log normal: y*=log y; somente valores positivos, variável contínua com assimetria. Binomial: y*=arco seno y. dados na forma de proporções. Teste de Bartlett para igualdade de variâncias O teste estatístico é dado por: Onde:
é a variância amostral do i-ésimo tratamento. Rejeita-se H0 quando Exemplo 1-4 Conclui-se que as 5 variâncias são iguais. Mesma conclusão com o uso do valor p (= 0,4378).
Teste de Levene 1) Calcular os resíduos da análise de variância; 2) Fazer uma análise de variância dos valores absolutos desses resíduos; 3) Se as variâncias são homogêneas, o resultado do teste F será não significativo. Exemplo: dados de absorbância. Rejeita-se a hipótese de que as variâncias são homogêneas.
1-4.4 Escolha da transformação para estabilizar a variância Escolha empírica da transformação Em muitos experimentos onde há repetições, podemos estimar o parâmetro através da equação de regressão: Como e são desconhecidos, usamos as suas estimativas s e y(barra), esta é a média da amostra.
Exemplo 1-5 (Arquivo: plasma.sas) Um pesquisador está interessado em estudar a influência das idades de crianças doentes no nível de plasma, foram testadas 5 idades distintas, ou sejam, ID1= 0 ano, ID2=1 ano, ID3=2 anos, ID4=3 anos e ID5=4 anos. Os resultados de nível de plasma foram:
O teste F da ANAVA indica que as 5 médias de níveis de plasma diferem significativamente entre si. O gráfico dos resíduos indica heterogeneidade de variâncias.
Para estudar a possibilidade de uma transformação nos dados, plotamos log do desvio padrão versus log da média. A equação de uma regressão linear simples para os dados é dada por:
Como o coeficiente angular é próximo de 1,5 e, de acordo com a tabela, podemos usar a transformação INVERSO DA RAÍZ QUADRADA.
Normalidade: de acordo com o gráfico abaixo podemos considerar que os dados seguem uma distribuição normal.
1-4.5 Gráfico dos resíduos versus outras variáveis Se a distribuição dos pontos no gráfico mostrar algum padrão (tendência, isto é, se os pontos não estão distribuídos aleatoriamente no gráfico) a variável afeta a resposta, assim, esta variável deve ser melhor controlada ou incluída na análise. Por exemplo, as análises foram feitas com dois espectrofotômetros.
1-5 Interpretando os resultados 1-5.1 Comparações entre médias de tratamentos (Fatores qualitativos) Quando o teste F da análise de variância for significativo, indica que existe diferenças entre as médias reais de tratamentos. Entre quais médias ou grupos? 1-5.2 Contrastes Desejamos verificar se a médias dos solventes E50, EAW e E70 não diferem da média dos solventes MAW e MM. Esta hipótese é escrita como: Temos o contraste: A soma de quadrados é dada por: Com 1 grau de liberdade (sempre).
Se o delineamento é desbalanceado então: TESTE: SQc/QMErro. Vamos obter uma estatística F com 1 e N-a graus de liberdade. 1-5.3 Contrastes Ortogonais Dois contrastes com coeficientes ci e disão ortogonais se: Exemplo: vamos considerar um experimento com 3 tratamentos (a=3), sendo um deles o controle. ortogonais
Os contrastes devem ser escolhidos antes de realizar o experimento. Para a tratamentos podemos ter a-1 contrastes ortogonais; podemos ter vários conjuntos de a-1 contrastes ortogonais. Exemplo: dados de absorbância. Temos 5 médias de tratamentos e, portanto, 4 g.l. 4 contrastes ortogonais. Contrastes C1=2y1.+2y2.-3y3.+2y4.-3y5. C2= y1.+ y2. -2y4. C3= y1.- y2. C4= y3. -y5. Hipóteses: C1=1,4889; C2=-0,10956; C3=-0,0275; C4=0,2588 SQC1=0,3695; SQC2=0,0100; SQC3=0,00189; SQC4=0,15987
1-5.4 Método de Scheffé para comparação de contrastes 1 - Não sabe a priori quais contrastes comparar 2 - Deseja comparar mais do que a-1 contrastes Considere m contrastes de médias: A estimativa do contraste é dado por: O erro padrão do contraste é dado por:
Critério do teste: o valor com o qual Cu deve ser comparado é dado por: Se |Cu| S,u, então rejeita-se a hipótese de que o contraste u é igual a zero. Exemplo 1-1. Dados de absorbância. Considere os 2 contrastes de interesse As estimativas desses contrastes são:
Erros padrões dos contrastes: Os valores críticos ( = 0,01) são dados por: Como |C1| S0,01;1 conclui-se que o contraste C1 é diferente de zero, isto é, os tratamentos E50, EAW e E70 em média diferem dos tratamentos MAW e M1M. Como |C2| S0,01;2 conclui-se que o contraste C2 é igual a zero, portanto, os tratamentos E50 e EAW, em média, não diferem do tratamento E70.
1-5.5 Comparações entre Pares de Médias Hipótese: Número de comparações: a(a-1)/2. Devem ser realizadas após o teste F da análise de variância rejeitar a hipótese nula Método da Diferença Mínima Significativa (LSD) A estatística a ser utilizada é dada por: Para um teste bilateral, o par de médias, i e j, é significativamente diferente se: LSD
concluímos que o par de médias i e j, difere significativamente. Critério do teste: se Exemplo: dados de absorbância. Para =0,05, o valor da LSD é: * diferença significativa para =5%.
Teste de Tukey Duas médias são diferentes significativamente se a diferença das médias amostrais (em valor absoluto) for superior a DMS (Diferença Mínima Significativa): Onde q é um apropriado nível de confiança superior da amplitude studentizada para k médias (tratamentos) e f graus de liberdade associados a estimativa s2de 2 (QMErro). Exemplo: dados de absorbância. O valor da Diferença Mínima Significativa é: Conclusão: pelo teste de Tukey, ao nível de significância de 5%, as médias dos tratamentos E50 e EAW, assim como as médias dos tratamentos EAW e E70 não apresentam diferenças significantes. As médias dos tratamentos E50 e E70 apresentam diferença significante.
E70 = 0,6363 A EAW = 0,5669 A B E50 = 0,5393 B MAW = 0,4496 C M1M = 0,1968 D Médias seguidas de mesma letra, em uma mesma coluna, não apresentam diferenças significantes, ao nível de significância de 5%, pelo teste de Tukey.
Teste de Dunnett: comparação com um controle Interesse é comparar cada uma das a-1 médias com a média do tratamento controle, assim temos a-1 comparações. Deseja-se testar a hipótese: Onde a é a média do tratamento controle. A hipótese de nulidade é rejeitada, ao nível de significância , se Exemplo: dados de absorbância. Considere o tratamento M1M como sendo o controle. Neste exemplo, a=5, a-1=4 e f=20 e ni=na=5. Para =5%, da tabela (valores críticos do teste de Dunnett) obtemos d0,05(4;20)=2,65. Assim, o valor crítico é dado por:
Conclusão: todas as médias diferem significativamente da média do tratamento controle. Qual teste usar? O LSD é eficiente para detectar diferenças verdadeiras nas médias se ele for aplicado apenas depois do teste F da ANOVA se significativo a 5%. Idem para o Duncan. Estes métodos não contém o erro tipo I (erro geral ou experimentwise error). Como o Tukey controla este erro ele é o preferido pelos estatísticos. O SNK é mais conservador do que o Duncan.
Doses de Observações Totais Médias fósforo 0 kg/ha 2,38 6,77 3,50 5,94 18,59 4,65 25 kg/ha 6,15 8,78 8,99 9,10 33,02 8,26 50 kg/ha 9,07 8,73 6,92 8,48 33,20 8,30 1-5.6 Modelo de Regressão Fator quantitativo: interesse em encontrar uma equação de regressão que leva em conta toda a faixa de valores análise de regressão Exemplo: produção de milho em kg/parcela. Desvio Padrão 2,05 1,40 0,95 0,69 75 kg/ha 9,55 8,95 10,24 8,66 37,40 9,35 0,40 100 kg/ha 9,14 10,17 9,75 9,50 38,56 9,64
Os traços no gráfico representam os valores médios para cada uma das doses. • Pelo gráfico de dispersão, verifica-se claramente que a relação não é linear. • Podemos ajustar um polinômio de 20 grau para representar este relacionamento, isto é, Onde 0, 1 e 2 são parâmetros desconhecidos e que devem ser estimados e é o erro aleatório. Para o exemplo a equação ajustada é dada por: . R2=66,9%66,9 % da variabilidade dos dados é explicada pelo modelo quadrático.
- Estimar a produção média de milho para doses dentro da região de experimentação; -Otimização. Estimação: X=90 Ŷ=9,58 8,6E(Y)10,5 Otimização:
1-6 Modelo de Efeito Aleatório Se o pesquisador seleciona aleatoriamente a níveis de um fator de uma população de níveis desse fator, então o fator é dito aleatório. A inferência é feita para toda a população de níveis. Exemplo: uma pesquisadora estudou o conteúdo de sódio em cervejas selecionando aleatoriamente 6 marcas de um grande número de marcas dos EUA e do Canadá. Ela, então, escolheu 8 garrafas de cada marca aleatoriamente de supermercados e mediu a quantidade de sódio (em miligramas) de cada garrafa.
O modelo estatístico: i é o efeito do i-ésimo tratamento e assume-se que seja NID(0,2) ij é o erro aleatório e assume-se que sejam NID(0, 2) i e ij são independentes Testar hipóteses sobre os efeitos dos tratamentos não faz sentido, assim, vamos testar as hipóteses sobre a variância dos tratamentos.
Se 2=0, então todos os tratamentos são idênticos; mas se 2>0 a variabilidade entre tratamentos é significativa. Quando temos um modelo de efeitos aleatórios o interesse está em estimarmos os componentes de variâncias: 2 e 2. Prova-se que: Portanto,