Download

1 / 20
200 likes | 221 Views
Explore methods of state tying to reduce speech recognition system parameters without compromising accuracy. Compare data-driven clustering and decision tree approaches using distance measures and tree nodes. Evaluate reduction in word error rates.

E N D
State Tying for Context Dependent Phoneme Models K. Beulen E. Bransch H. Ney Lehrstuhl fur Informatik VI, RWTH Aachen –University of Technology, D-52056 Aachen EUROSPEECH97,Sep97 Present by Hsu Ting-Wei 2006.05.01
Reference • J. J. Odell, The Use of Context in Large Vocabulary Speech Recognition, Ph.D. Thesis, Cambridge University, Cambridge, March 1995. • 羅應順,自發性中文語音基本辨認系統之建立,交大電信,94.6
1.Introduction • In this paper several modifications of two well known methods for parameter reduction of Hidden Markov Models by state tying are described. • The two methods are: • A data driven method which clusters triphone states with a bottom up algorithm. • A top down method which grows decision trees for triphone states . Decision tree State tying Bottom up Top down Data driven
1.Introduction (cont.) • We investigate the following aspects: • The possible reduction of the word error rate by state tying • the consequences of different distance measures for the data driven approach and • modifications of the original decision tree approach such as node merging Node merging Distance measures
Corpus • Test corpus : • 5000 word vocabulary of the WSJ November 92 task • Evaluation corpus : • 3000 word vocabulary of the VERBMOBIL ’95 task • The reduction of the word error rate by state tying : • 14% for the WSJ task • 5% for the VERBMOBIL task compared to simple triphone models.
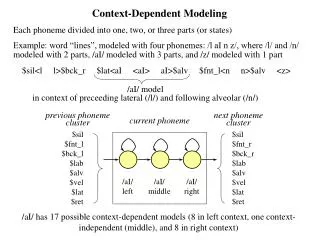
2.State tying • Aim: Reduce the number of parameters of the speech recognition system without a significant degradation in modeling accuracy. • Steps: • Establish triphone list of the training corpus • Estimate the mean and variance of the triphone state by using a segmentation of the training data • The triphone states are then subdivided into subsets according to their central phoneme and their position within the phoneme model. Inside these sets the states are tied together according to a distance measure. • Additionally it has to be assured that every model contains a sufficient amount of training data. mean1 mean2 ㄅㄧㄠ ㄅㄧㄩ State tying
3.Data driven method • Two steps • The triphone states being very much alike due to a distance measure are clustered together (seen >= 50 times in the training corpus) • The states which do not contain enough data are clustered together with the nearest neighbor • Drawback • For triphones which were not observed in the training corpus no tied model is available (Backing off models) • Usually these models are simple generalizations of the triphones such as diphones or monophones • Cluster Criteria • The approximative divergence of two states • The log-likelihood difference
3.Data driven method (cont.) • Data driven clustering flow chart:
4.Decision tree method • Construct steps: • Collect all states in the root of tree • Find a binary question which can be solved by maximum log-likelihood. • Cluster the data into two parts, one is “Yes” and the other one is “No”. • Repeat the step 2 until the maximum log-likelihood below the threshold. • Advantage • No backing off models are needed because using the decision trees one can find a generalized model for every triphone state in the recognition vocabulary
4.Decision tree method (cont.) Question: Is the left context a word boundary? Bias: Most questions ask for a very special phoneme property, so most triphone states belong to the right subtree. Heterogamous:All the questions from the root to the leaf were answered by “No”. The number of triphone states The number of observations which belong to this leaf
4.Decision tree method (cont.) • We also tested the following modifications of the original method: • 4.1 No Ad-hoc subdivision • 4.2 Different triphone lists • 4.3 Cross validation • 4.4 Gender dependent(GD) coupling • 4.5 Node merging • 4.6 Full covariance matrix
4.1 No Ad-hoc subdivision • Instead of one distinct tree for every phoneme and state, a single tree • Split every node until it contains only states with one central phoneme • Split every node until every word in the vocabulary can be discriminated • In the experiments we found out that such heterogemous nodes are very rare and do not introduce any ambiguities in the lexicon.
4.2 Different triphone lists 1. 2. 3. 4. 4: Contain those triphones from the training corpus which can also be found in the test lexicon
4.3 Cross validation Triphone list 1(50 observations) was used to estimate the Gaussian models of the tree nodes. Triphone list 2 (20 observations) was used to cross validate the splits .At every node the split with the highest gain in log-likelihood was made which also achieved a positive gain for the triphones of list 2
4.4 Gender dependent (GD)coupling Advantage: Construct gender dependent decision trees.Disadvantage: The training data for the tree construction is being halved.Every tree node contains two separate models for male and female data. The log-likelihood of the node data can then be calculated as the sum of the log-likelihoods of the two models
4.5 Node merging The merged node represents the triphone states for which the disjunction of the conjuncted answers are true. So every possible combination of questions can be constructed.
4.6 Full covariance matrix • Replaced the diagonal covariance matrices of the Gaussian models by full covariance matrices. • This modification results in a large increase in the number of parameters of the decision tree. • Smoothing method:
5. Conclusion • Two well known methods for parameter reduction of Hidden Markov Models by state tying are described. • There are some ways to adjust the methods of state tying , and they produce some good results.