Download

1 / 16
160 likes | 369 Views
1. Stat 231. A.L. Yuille. Fall 2004. PAC Learning and Generalizability . Margin Errors. Structural Risk Minimization. 2. Induction: History. Francis Bacon described empiricism. Formulate hypotheses and test by experiments. English Empiricist School of Philosophy.

E N D
1. Stat 231. A.L. Yuille. Fall 2004 • PAC Learning and Generalizability. • Margin Errors. • Structural Risk Minimization. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
2. Induction: History. • Francis Bacon described empiricism. Formulate hypotheses and test by experiments. English Empiricist School of Philosophy. • David Hume. Scottish. Scepticism. “Why should the Sun rise tomorrow just because it always has”? • Karl Popper. The Logic of Scientific Induction. Falsifiability Principle. “A hypothesis is useless unless it can be disproven”. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
3. Risk and Empirical Risk • Risk • Specialize: Two classes: M=2. Loss Function is the number of misclassifications. I.e. Empirical Risk: dataset -- set of learning machines (e.g. all thresholded hyperplanes). Lecture notes for Stat 231: Pattern Recognition and Machine Learning
4. Risk and Empirical Risk • Key Concept: the Vapnik-Chervonenkis (VC) dimension h. • The VC dimension is a function of the set of classifiers • It is independent of the distribution P(x,y) of the dataset. • The VC dimension is a measure of the “degrees of freedom” • of the set of classifiers. Intuitively, the size of the dataset n must be larger than the VC dimension before you can learn. • E.G. Cover’s theorem. Hyperplanes in d space must have at least 2(d+1) samples to prevent the chance of finding a chance dichotomy. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
5. PAC. • Probably Approximately Correct (PAC). • If h < n, is the VC dimension of the classifier set, then with probability at least • where • For hyperplanes h = d+1. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
6. PAC • Generalizability: Small empirical risk implies, with high probability, small risk provided is small. • Probably Approximately Correct (PAC). • Because we can never be completely sure that we havn’t been mislead by rare samples. • In practice, require h/n to be small with small Lecture notes for Stat 231: Pattern Recognition and Machine Learning
7. PAC • This is the basic Machine Learning result. There are a number of variants. • VC dimension is one measure of the capacity of the set of classifiers. Other measures give tighter bounds but are harder to compute: annealed VC entropy, and growth function. • VC dimension is d+1 for thresholded hyperplanes. It can also be bounded nicely for separable kernels. (Later this lecture). • Forthcoming lecture will sketch the derivation of PAC. It makes use of probability of rare events (e.g. Cramer’s theorem, Sanov’s theorem). Lecture notes for Stat 231: Pattern Recognition and Machine Learning
8. VC for Margins • VC is the largest number of data points which can be shattered by the classifier set. • Shattered means that all possible dichotomies of the dataset can be expressed by a classifier in the set. (c.f. Cover’s hyperplane) • VC dimension is (d+1) for thresholded hyperplanes in d dimensions. • But we can tighter VC dimensions by considering the margins. These bounds can be extended directly to kernel hyperplanes. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
9. VC Margin Hyperplanes • Hyperplanes The are normalized wrt data • Then the set of classifiers • satisfying, has VC dimension satisfying: • where is the radius of the smallest sphere containing the datapoints. Recall is the margin. (Margin >. • Enforcing a large margin effectively limits the VC dimension. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
10. VC Margin: Kernels. • Same technique applies to kernels. • Claim: finding the minimum sphere R than encloses the data depends only on the feature vectors by the kernel (kernel trick). • Primal: minimize • Lagrange multipliers. • Dual: maximize • s.t. • Depends on dot-product only! Lecture notes for Stat 231: Pattern Recognition and Machine Learning
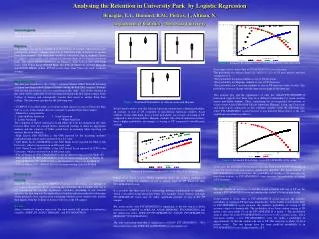
11. Generalizability for Kernels • The capacity term is a monotonic function of h. • Use the Margin VC bound to decide which kernels will do best for learning the US Post Office handwritten dataset. • For each kernel choice, solve the dual problem to estimate R. • Assume that the empirical risk is negligible – because it is possible to classify digits correctly using kernels (but not linear). • This predicts that the fourth order kernel has the best generalization – this compares nicely with the results of the classifiers when tested. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
12. Generalization for Kernels Lecture notes for Stat 231: Pattern Recognition and Machine Learning
13. Structural Risk Minimization • Standard Learning says: pick • Traditional: use cross-validation to determine if • is generalizing. • VC theory says, evaluate the bound • Ensure there are sufficient number of samples to ensure that is is small. • Alternative: Structural Risk Minimization. Divide the set of classifiers into a hierarchy of sets .,... with corresponding VC-dims ... Lecture notes for Stat 231: Pattern Recognition and Machine Learning
14. Structural Risk Minimization • Select classifiers to minimize: • Empirical Risk + Capacity Term. • Capacity Term determines the “generalizability” of the classifier. • Increasing the amount of training data allows you to increase p • and use a richer class of classifiers. • Is the bound tight enough? Lecture notes for Stat 231: Pattern Recognition and Machine Learning
15. Structural Risk Minimization Lecture notes for Stat 231: Pattern Recognition and Machine Learning
16 Summary • PAC Learning and the VC dimension. • The VC dimension is a measure of capacity of the set of classifiers. • The risk is bounded by the empirical risk plus a capacity term. • VC dimensions can be bounded for linear and kernels by the margin concept. • This can predict which filters are best able to generalize. • Structured Risk Minimization – penalize classifiers that have poor bounds for generalization. Lecture notes for Stat 231: Pattern Recognition and Machine Learning