Download

1 / 14
140 likes | 285 Views
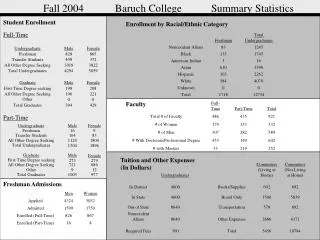
1. Stat 231. A.L. Yuille. Fall 2004. Perceptron Rule and Convergence Proof Capacity of Perceptrons. Multi-layer Perceptrons. Read 5.4,5.5 9.6.8 Duda, Hart, Stork. 2. Linear Separation. N samples where the Can we find a hyperplane in feature space through the origin,

E N D
1. Stat 231. A.L. Yuille. Fall 2004. • Perceptron Rule and Convergence Proof • Capacity of Perceptrons. • Multi-layer Perceptrons. • Read 5.4,5.5 9.6.8 Duda, Hart, Stork. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
2. Linear Separation • N samples where the • Can we find a hyperplane in feature space through the origin, that separates the two types of samples Lecture notes for Stat 231: Pattern Recognition and Machine Learning
3. Linear Separation • For the two-class case, simplify by replacing all samples with Then find a plane such that • The weight vector is almost never unique. • Determine the weight vector that has the biggest margin m(>0), where (Next lecture). • Discriminative: no attempt to model probability distributions. Recall that the decision boundary is a hyperplane if the distributions are Gaussian with identical covariance. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
4. Perceptron Rule • Assume there is a hyperplane separating the two classes. How can we find it? • Single Sample Perceptron Rule. • Order samples • Set loop over j, if is misclassified, set repeat until all samples are classified correctly. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
5. Perceptron Convergence • Novikov’s Theorem: the single sample Perceptron rule will converge to a solution weight, if one exists. • Proof. Suppose is a separating weight. • Then • decreases by at least for each misclassified sample. • Initialize weight at 0. Then number of weight changes is less than Lecture notes for Stat 231: Pattern Recognition and Machine Learning
6. Perceptron Convergence • Proof of claim. • If • Using Lecture notes for Stat 231: Pattern Recognition and Machine Learning
7. Perceptron Capacity • The Perceptron was very influencial and unrealistic claims were made about its abilities (1950’s, early 1960’s). • The model is an idealized model of neurons. • An entire book was published in the mid 1960’s describing the limited capacity of Perceptrons (Minsky and Papert). Some classifications, exclusive or, can’t be performed by linear separation. • But, from Learning Theory, limited capacity is good. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
8. Generalization and Capacity. • The Perceptron is useful precisely because it has finite capacity and so cannot represent all classifications. • The amount of training data required to ensure Generalization will need to be larger than the capacity. Infinite capacity requires infinite data. • Full definition of Perceptron capacity must wait till we introduce Vapnik Chevonenkis (VC) dimension. • But the following result (Cover) gives the basic idea. . Lecture notes for Stat 231: Pattern Recognition and Machine Learning
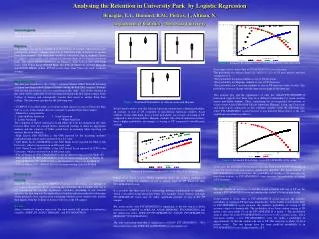
9. Perceptron Capacity • Suppose we have n sample points in a d dimensional feature space. Assume that these points are in general position – no subset of (d+1) points lies in a (d-1) dimensional subspace • Let f(n,d) be the fraction of the 2^n dichotomies of the n points which can be expressed by linear separation. • It can be shown (D.H.S) that f(n,d) =1, for • otherwise • There is a critical value 2(d+1). f(n,d)=1 for n << 2(d+1), • f(n,d) =0 for n >> 2(d+1), transition rapid for large d. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
10. Capacity and Generalization • Perceptron capacity is d+1. The probability of finding a separating hyperplane by chance alignment of the samples decreases rapidly for n > 2(d+1). Lecture notes for Stat 231: Pattern Recognition and Machine Learning
11. Multi-Layer Perceptrons • Multilayer Perceptrons were introduced in the 1980’s to increase capacity. Motivated by biological arguments (dubious). • Key Idea: replace the binary decision rule by a Sigmoid function: (Step function as T tends to 0). • Input units activity • Hidden units • Output units Weights connecting the Input units to the hidden units, and the hidden units to the output units. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
12. Multilayer Perceptrons • Multilayer perceptrons can represent any function provided there are a sufficient number of hidden units. But the number of hidden units may be enormous. • Also the ability to represent any function may be bad, because of generalization/memorization. • Difficult to analyze multilayer perceptrons. They are like “black boxes”. When they are successful, there is often a simpler, more transparent alternative • The Neuronal plausibility for multilayer perceptrons is unclear. Lecture notes for Stat 231: Pattern Recognition and Machine Learning
13. Multilayer Perceptrons • Train the multilayer perceptron using training data • Define error function for each sample • Minimize the error function for each sample by steepest descent: • Backpropagation algorithm (propagation of errors). Lecture notes for Stat 231: Pattern Recognition and Machine Learning
Summary • Perceptron and Linear Separability. • Perceptron rule and convergence proof. • Capacity of Perceptrons. • Multi-layer Perceptrons. • Next Lecture – Support Vector Machines for Linear Separation. Lecture notes for Stat 231: Pattern Recognition and Machine Learning