Download

1 / 27
270 likes | 437 Views
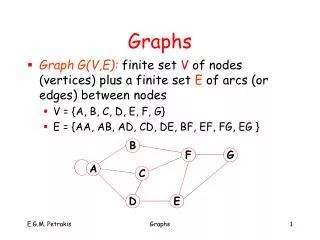
Graphs. Ellen Walker CPSC 201 Data Structures Hiram College. Basic Graph Terminology. Edge (link). cycle. C. A. C. A. No cycle. D. D. B. cycle. B. Vertex (node). Path. E. E. Directed Graph. Undirected Graph. V = {A,B,C,D,E} E = {(A,B), (A,E), (A,D), (D,E), (A,C).(C,A)}.

E N D
Graphs Ellen Walker CPSC 201 Data Structures Hiram College
Basic Graph Terminology Edge (link) cycle C A C A No cycle D D B cycle B Vertex (node) Path E E Directed Graph Undirected Graph V = {A,B,C,D,E} E = {(A,B), (A,E), (A,D), (D,E), (A,C).(C,A)} V = {A,B,C,D,E} E = {{A,B}, {A,C}, {A,D}, {A,E}, {D, E}}
More Terminology C • A is adjacent to B, C, D and E (degree is 4) • D is adjacent to A and E ( degree of D is 2) • There are 2 connected components (ABCDE and FG) • Path BAE is a simple path ; Path BABAC is not. • Path ADEA is a cycle A D B F E G
Graph Application Example: Prerequisites CPSC 171 CPSC 240 CPSC 172 CPSC 152 CPSC 386 CPSC 201 CPSC 331 CPSC 361 CPSC 400 CPSC 401
Graph Application Example: Travel Planning 2.5 CLE 1 DEN 1 2 2 ORD PHL 4 4 1.5 SFO 1.5 4 CVG 2 4 CLT SJC 4
Graphs and Trees • Every tree is a graph • It is connected • It has no cycles • Either all links are directed “downward” away from the root, or it is undirected • Every connected, no-cycle, undirected graph can be a tree • Any node can be chosen as the root
Graph ADT • A set of methods • Create a new graph (specify # vertices) • Iterate through vertices of graph • Iterate through neighbors of a vertex • Is there an edge between 2 vertices? • What is the weight of an edge between 2 vertices? • Insert an edge into the graph • Other options might be available • E.g. add vertices, connect a vertex to another, etc.
Representing Vertices and Edges • Vertex represented as integer • Doesn’t allow named vertices • Index into an array of names if you need them • Edge represented by a class • Source vertex, destination vertex, weight (default 1.0) • For undirected graph, add each edge in both directions
Graph Representations • Adjacency List • Each vertex is associated with a list of edges • Looks a lot like a hash table; linked lists hanging off an array • Adjacency Matrix • 2D matrix: M[R][C] = weight of edge from R to C
Adjacency List Example (Directed) 2 0 1 2 3 4 0 3 4 1 4
Adjacency List Example (Undirected) 2 0 1 2 3 4 0 0 3 1 0 4 0 3 4
Adjacency Matrix Example 10 2 0 8 7 5 3 1 7 5 4 Value at row,col = weight from row to col The value “x” means infinity (Double.POSITIVE_INFINITY in Java) Unweighted graph can use boolean: (edge = true)
Graph Traversals vs. Tree Traversals • Tree has no cycles; graph can have cycles • Mark visited nodes, and don’t repeat them! • Tree is connected; graph does not have to be • After your traversal is “finished” check to see if there are leftover (not visited) nodes • A graph traversal induces a tree structure on the graph • The edges that are used to “find” nodes are part of the tree • The root of the tree is the node that started the traversal
Breadth-First vs. Depth-First • Breadth-first • Visit all my immediate neighbors before visiting their neighbors • In tree - all children before any grandchildren (level-order traversal) • Depth-first • Visit first child, first grandchild, … as deep as possible before looking at second child
Breadth First Algorithm • For each vertex • If the vertex is unseen, offer it to the queue and mark it identified • While the queue is not empty • Current_vertex = q.poll(); • For each neighbor of the current vertex • If the neighbor is not yet visited, offer it to the queue and mark it identified • Mark current vertex as visited • End for • End While
Three Kinds of Nodes • Unseen (white in your textbook) • Nodes that have not yet been seen at all • Identified (pale blue in your textbook) • Nodes that are currently in the queue • Must have at least one visited neighbor • Visited (dark blue in your textbook) • Nodes that have been completed • All neighbors are visited or identified
Depth First Search Algorithm • For each vertex • If the vertex is unseen, push it on the stack and mark it identified • While the stack is not empty • Current_vertex = q.pop(); • For each neighbor of the current vertex • If the neighbor is not yet visited, push it on the stack and mark it identified • Mark current vertex as visited • End for • End While
Recursive Depth First Search • Rec_dfs(current-node){ • mark current-node identified • for each neighbor of current_node • if neighbor is not identified • (set parent of neighbor to current node) • rec_dfs(neighbor) • mark current-node visited • }
Comments on Recursive DFS • Recursive DFS visits the same nodes, in the same order as Stack DFS • Recursive DFS actually uses a stack • (Why?) • Why is there no recursive BFS?
DFS / BFS analysis • Each search visits every node, and considers every neighbor of every node • The number of nodes visited is O(V) • The number of neigbors considered is O(E) • Every vertex is a neighbor for one of its edges • Time proportional to V+E • But, since E >> V (there cannot be fewer than O(V) edges, but there can be O(V2 )), overall time is O(E) in both cases
Common Graph Algorithms • Dijkstra’s algorithm • Shortest path from one vertex to all others in a weighted graph • If the graph isn’t weighted use BFS. The path you take to the node is by definition the shortest. • Prim’s algorithm • Finding the spanning tree with the minimum total weight • A spanning tree is a subset of (V-1) edges that minimally connects the graph
Dijkstra’s Algorithm • The main idea: • If the (best possible known) cost from point A to point B is x • And there is a connection from B to C that costs y, • Then the (best possible known) path from point A to point C through B costs x+y
Keeping Track of Paths • We will find all possible distances from a starting node, A • Create a table of all other nodes (e.g. B,C,D) • Initially, distances are all infinite (unreachable) • Now, we’ll visit one node at a time (starting with A) and adding all its links to the table…
Visiting a node • Assume you are looking at node A • Suppose there is an edge from A to B costing k • Let d(A) and d(B) be the distances (in the table) from the starting node to A and B respectively • If d(A)+k < d(B), change d(B) to d(A)+k and mark B’s predecessor as A • Do the above for all edges of A
Putting it all together • Initialize the table • Visit the starting node • While (not all nodes have been visited) • Visit the node that is closest to the starting point • When done, the table will contain all shortest distances