Download

1 / 31
320 likes | 516 Views
Hong Kong University of Science and Technology - MSc(IT) 2003 Fall Semester - Track 1 CSIT560 Internet Infrastructure: Switches and Routers Final Project Presentation #T1-6-2. VoQ Crossbar Schedulers. Group Members: Cyrus LO – 02784753 interman@ust.hk Ricky CHAN - 02784557 rickyccm@ust.hk

E N D
Hong Kong University of Science and Technology -MSc(IT) 2003Fall Semester - Track 1CSIT560 Internet Infrastructure: Switches and Routers Final Project Presentation #T1-6-2 VoQ Crossbar Schedulers Group Members: Cyrus LO – 02784753 interman@ust.hk Ricky CHAN - 02784557 rickyccm@ust.hk Ricky KWAN - 02784674 rickykcy@ust.hk Presented on 1 December 2003 Start
Agenda • Part I. Introduction • Project goals (30secs by Ricky Chan) • Part II. Some well-known MWM/MSM scheduling algorithms • What are the differences between MSM & MWM ? • Overview of PIM algorithm • What is the common problem? (2’30 mins by Ricky Chan) • Part III. Our findings • Requirements and assumptions • A new conceptual algorithm –Real De-synchronized Round-Robin Model (RDESRR) • What is RDESRR ? (6 mins by Ricky Kwan) • Part IV. Experimental results • SIM Results • Result comparisons : RDESRR Vs SSRR & ISLIP • Strengths & Weaknesses (4 mins by Cryus Lo) • Part V. Conclusion • Conclusions (1 min by Cryus Lo) • Part VI. Q & A (1 min by all)
Project goals • By further studying and analysis of the pointer desynchronization effect of some iterative arbitration algorithms, our group has the following goals: • Tackle the common problem of some well-known MSM algorithms • Propose a new conceptual algorithm for overcoming the problem • Simulate the proposed algorithm by using SIM • Justify the results
Part II. Some Well-known MWM/MSM scheduling algorithms
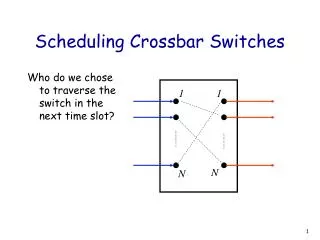
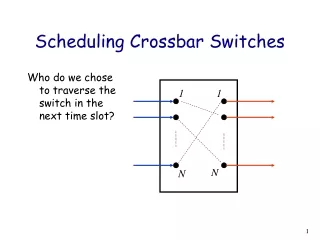
What are the differences between MSM & MWM ? • Maximum weight matching (MWM) – stable for independent, 100% throughput under any traffic. • Maximum size matching (MSM) – stable for i.i.d, uniform, admissible traffic. • Both are too complex to implement, time complexities are O(N3logN) – MWM and O(N5/2) – MSM Derandomized rotating double static round-robin ! • Only rely on some simple iterative algorithms to approximate MSM • Some simple iterative algorithms: • Parallel Iterative Matching (PIM) • Round-Robin Matching (RRM) • iterative SLIP (iSLIP). • Fcfs in Round-Robin Matching (FIRM) • Static Round-Robin Matching (SRR – SSRR, DSRR, Rotating DSRR & DRDSRR etc)
Overview of PIM algorithm The basic matching algorithm. Each iteration of the algorithm follows these three steps: 1. Request - Each unmatched input sends a request to every output for which it has a queued cell. 2. Grant - If an unmatched output receives any requests, it grants to one by randomly selecting a request uniformly over all requests. 3.Accept - If an input receives a grant, it accepts one by selecting an output randomly among those that granted to this output.. When no new matching can be found, the algorithm stops.
3 0 2 1 0 0 3 0 2 1 1 1 3 0 2 1 Both grant to 3 2 2 3 0 2 1 3 3 Is any improvement for PIM algorithms ? • PIM -> RRM -> ISLIP -> FIRM -> Pointer Desynchronized (SRR) • Some small change on pointers but make big improvement • SRR is desynchronized the highest priority pointers • It has no guarantee the grant result is desynchronized.
3 0 2 1 0 3 0 2 1 1 Grant Desynchronized (Real Desynchronized) 3 0 2 1 2 3 0 2 1 3 Is any improvement for PIM algorithms ? • If all grants are desynchronized. • Expect to get better result.
Assumptions • Not enough knowledge in Hardware • Look for the theoretical solution • We ignore all hardware implementation issues Requirements • The system is stable • 100% Throughput in uniform traffic • Target to desynchronize the grant results • (so called Real Desynchronize)
A new algorithm – RDESRR • Concept: • Real Desynchronized Round Robin Model (RDESRR) • Based on 2 phases RRM model (Request and Grant) • Add a small share memory that each outputs can read/write (called Share Bits) • The size of the memory is 1 bit per input • If the bit is set, the corresponding input has already granted by an output • If the bit is not set, the output may grant to corresponding input port
0 1 2 3 RDESRR Conceptual model Share Bits 3 0 2 1 0 0 3 0 2 1 1 1 3 0 2 1 2 2 3 0 2 1 3 3
RDESRR model • 2 phases only • Request. Each input sends a request to every output for which it has a queued cell. • Grant. If an output receives any requests, it chooses the one that appears next in a fixed, round-robin schedule starting from the highest priority element. The output check the corresponding bit is set or not, if not set, the output will set the bit and notifies the input its request was granted. Otherwise, the output will look for next request until all requests has gone through. The pointer gi to the highest priority element of the round-robin schedule is incremented (modulo N) to one location beyond the granted input. If no request is received, the pointer stays unchanged.
RDESRR Demo - Request Step 1: Request 0 0 1 1 2 2 3 3
Share Bits 0 3 0 2 1 1 3 0 2 1 2 3 0 2 1 3 0 2 1 3 RDESRR Demo – Add a share memory in Output • Add a small share memory that each outputs can read/write (called Share Bits) Step 2: Grant 0 0 1 1 2 2 3 3
0 3 0 2 1 1 3 0 2 1 2 3 0 2 1 3 0 2 1 3 RDESRR Demo – Output check the share bits • The output check the corresponding bit is set or not Step 2: Grant Share Bits 0 0 1 1 2 2 3 3
0 3 0 2 1 1 3 0 2 1 2 3 0 2 1 3 0 2 1 3 RDESRR Demo – When share bit is occupied • if not set, the output will set the bit and notifies the input its request was granted • The share bit is First Come First Serve Step 2: Grant Share Bits 0 0 1 1 2 2 3 3
0 3 0 2 1 1 3 0 2 1 2 3 0 2 1 3 0 2 1 3 RDESRR Demo – Output looks for next request • If set, the output will look for next request until all requests have gone through Step 2: Grant Share Bits 0 0 1 1 2 2 3 3
0 3 0 2 1 1 3 0 2 1 2 3 0 2 1 3 0 2 1 3 RDESRR Demo – All share bits are allocated • Fully allocate the share bit will result for fully grant all input request Step 2: Grant Share Bits 0 0 1 1 2 2 3 3
0 3 0 2 1 0 0 1 3 0 2 1 1 1 2 3 0 2 1 2 2 3 0 2 1 3 3 3 RDESRR Demo – Pointer update/Share bit reset • The pointer gi to the highest priority element of the round-robin schedule is incremented (modulo N) to one location beyond the granted input • If no request is received, the pointer stays unchanged • Share bits are also reset Share Bits
RDESRR model (Recap) • 2 phases only • Request. Each input sends a request to every output for which it has a queued cell. • Grant. If an output receives any requests, it chooses the one that appears next in a fixed, round-robin schedule starting from the highest priority element. The output check the corresponding bit is set or not, if not set, the output will set the bit and notifies the input its request was granted. Otherwise, the output will look for next request until all requests has gone through. The pointer gi to the highest priority element of the round-robin schedule is incremented (modulo N) to one location beyond the granted input. If no request is received, the pointer stays unchanged.
SIM Results • Run the test for 32x32 port in SIM using –l 1000000
Result comparisons : RDESRR Vs SSRR & ISLIP • The latency in load = 1 is 715.59 • The average match size in load = 1 is 31.985 (99.95% match)
Strengths • 2 phase operations • Each input only get one grant, • no arbiter in input port • Save Cost • It is simple to implement because base on RR • Has a lot of potential varieties to study • May achieve Maximum Size Match after few iterations. Unknown factors Parallel processing for ports scheduling. • All outputs access the share bits simultaneously • Multi-process protection for Share Bits • Prevent deadlock, Check and set bit should be atomic action • Any chance for two outputs access same bit at the same time?
Final thought… • Future research and study • Hardware implementation feasibility? • Apply to ISLIP, FIRM, may get better result? • Comments on SIM • We have successfully build the SIM on Linux platform so we expect it can also be build on Windows platform with Cywin library • It cannot simulate the parallel processing behaviour therefore we cannot know what happen in the real scheduler • The processing time of SIM is quite slow so we cannot have enough time to simulate more revised algorithms and more iterations Conclusion: RDESRR is a conceptual model which get the good result in SIM