Download

1 / 29
290 likes | 425 Views
Toward Managing Uncertain Spatial Information for Situational Awareness Applications. Authors: Yiming Ma, Dmitri V. Kalashnikov and Sharad Mehrotra Presented by: Jonathan Durda. Situational Awareness Applications.

E N D
Toward Managing Uncertain Spatial Information for Situational Awareness Applications Authors: Yiming Ma, Dmitri V. Kalashnikov and SharadMehrotra Presented by: Jonathan Durda
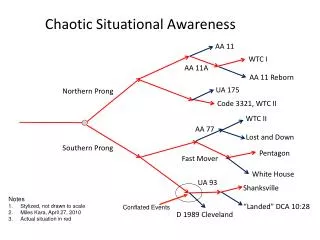
Situational Awareness Applications • Take different inputs and aid in decision making, reasoning and analysis of emergency situations • Example: September 11, 2001 • 1. “... The PAPD Mobile Command Post was located on West St. north of WTC and there was equipment being staged there. .. • 2. “... a PAPD Command Truck parked on the west side of Broadway St. and north of Vesey St. ...”
Situational Awareness Applications • Algorithms take this data as input and attempt to reason where the event is taking place • Information can be used to help emergency personnel and first responders to a disaster to have a better idea of where the event is taking place
Introduction • Uncertain locations are represented as random variables • Algorithm assumes that when events are reported, those reporting use landmarks to describe location • In our example, the landmark would be the World Trade Centers • Spatial descriptors refer to words that describe location, including “near WTC, in front of WTC, behind WTC”
Situational Awareness • Probabilistic Model used for uncertain spatial information • Formality – this model adds to the probability theory • Practicality – it has been implemented • Generality – the model can handle many types of queries about different spatial information • Effectiveness – other models and solutions that are already in place are known to work
Situational Awareness • A grid is used representing all of the information of possible space • Using input, the model gives the probability that an event happened in a given cell • Histograms used to represent locations, data is stored in a database in quad-tree form • Uncertain locations are indexed using R-trees
Situational Awareness • Each node in R-tree stores additional information about the left and right “x bound” of the uncertain event • Also stores top and bottom “y bounds” for location • A rectangle is formed based on the x bounds • Range queries include indoor and outdoor events
Modeling Location Uncertainty • The goal when a request is made is to give the location of the event by f(x,y|report) • F(x,y,|s,t) • “A traffic accident near World Trade Center” • S would be “near(WTC)” and t would be “traffic accident” • S gives the best location of the event • T helps us determine where the event may have happened, in this case in the road
Modeling Location Uncertainty • Four classes of s-descriptors: topoligical relations, cardinal direction relations, orientation relations and distance relations • S-expression contains many s-descriptors • “I am near building A and near building B” • This would create the s-expression {near(A) , near (B)}
Modeling Location Uncertainty • Pdf is Probability Density Function
Modeling Location Uncertainty • An s-descriptor can be near a building • Outside of a building is also s-descriptor • If an event is not inside of a building, the probability density function (pdf) is zero for inside the building • Bayes formula: f(x,y|s1,s2) = P(s1,s2|x,y) f(x,y) • P(s1,s2) • P(s1,s2) is the probability of observing events s1 and s2 given location x and y
Modeling Location Uncertainty • Events s1 and s2 are independent, therefore: • F(x,y|s1,s2) = f(x,y|s1) x f(x,y|s2) • Event t can be viewed uniform or non uniform • F(x,y|t) tells where a given even is likely to occur • If t is “home robbery”, the event occurred in a home and not in the street
Spatial Queries • A range query is defined to be all elements whose probability of being inside R is greater than zero • Probabilistic query is detached if it returns elements without probabilities assigned to them • The query is attached if it returns a set of tuples with elements and probabilities assigned to them • By default, spatial queries are detached
Spatial Queries • A query is said to have threshold semantics if a query Q returns all elements that have probabilities greater than threshold p • We represent shapes and objects in a grid with notation G(I,j) with i and j being coordinates in the grid • A region R must occupy either all of a cell or no part of a cell at all • vcellsin(R) denotes how many cells are in a range R
Efficient pdf Representation • Histograms represent pdfs, but may take up a large amount of space • Amount of space needed can be reduced by determining that some locations do not need to be in as much detail as others • Query processing can be more efficient by keeping only certain information about locations • Histogram is indexed using a quad-tree • Can be used to index the pixels of an image
U-Grid • Uncertain grid (U-grid) is a 2 dimensional array of cells
U-Grid • Each cell Lij also has pmax and psum attributes that has the maximum pmax and psum value of the entire list • Processing of range queries has indexing and object phases • Quad tree is traversed to find probability of query • Information stored in the grid is used to find a good upper bound for a location
U-Grid • Cell-level pruning is done by finding the minimum of the number of cells in a range x pmax,psum • If cell level pruning does now work, the list Lij is processed sequentially by location • Location pruning is the lowest level of Pruning. If it cannot be pruned, it is inserted into a processor list
Multiple Lists • Having multiple lists per cell increases efficiency and each list has a threshold • When algorithm goes to process a list of lists, it starts with the rightmost list • Each list looked at for pruning • Lists are created to maximize the pruning power of a range query
Multiple Lists • Minimize size of bounding regions (BR) so that this region does not intersect with a query region • BR should be chosen to minimize I/O time and increase efficiency • BR should be selected so that storing and indexing locations is very fast • Primary list of a cell is the list itself, and all other lists are secondary lists • Bounding regions are split into four corners so that algorithm runs efficiently
Index Slicing • Store many x bounds to increase pruning power • Increases size of R tree however • So we use multiple indexes with information in each one • Create kxbounds for each threshold level • Algorithm starts with rightmost R tree, this technique does not greatly increase size of R tree
Processing Range Queries with U-Grids • Computing exact probabilities for each cell can be very time consuming • We find a good upper bound using information in the directory grid
Evaluating this Strategy • Authors experimented on 2 GHz PC with 1 GB RAM • Data used is from 164 NYPD reports on September 22, 2001 • The retrieval time for each model is examined
Experimenting • U-Grid is the best solution for a city level area • Events separated into low (less than 10x10 vcells) medium (less than 20x20) and high (less than 100x100) • Data uncertainty controlled by including many objects with different uncertainty levels