Download

1 / 29
310 likes | 633 Views
Introduction to plausible values. ICCS IDB Training Seminar Hamburg, 24-26 November 2010. Content of presentation. Rationale for scaling Rasch model and possible ability estimates Shortcomings of point estimates Drawing plausible values Computation of measurement error.

E N D
Introduction to plausible values ICCS IDB Training Seminar Hamburg, 24-26 November 2010
Content of presentation • Rationale for scaling • Rasch model and possible ability estimates • Shortcomings of point estimates • Drawing plausible values • Computation of measurement error
Rationale for IRT scaling of data • Summarising data instead of dealing with many single items • Raw scores or percent correct sample-dependent • Makes equating possible and can deal with rotated test forms
The ‘Rasch model’ • Models the probability to respond correctly to an item as • Likewise, the probability of NOT responding correctly is modelled as
How might we impute a reasonable proficiency value? • Choose the proficiency that makes the score most likely • Maximum Likelihood Estimate • Weighted Likelihood Estimate • Choose the most likely proficiency for the score • empirical Bayes • Choose a selection of likely proficiencies for the score • Multiple imputations (plausible values)
Score 3 Score 4 Score 5 Score 6 Score 2 Score 1 Score 0 Proficiency on Logit Scale The Resulting Proficiency Distribution
Characteristics of Maximum Likelihood Estimates (MLE) • Unbiased at individual level with sufficient information BUT biased towards ends of ability scale. • Arbitrary treatment of perfects and zeroes required • Discrete scale & measurement error leads to bias in population parameter estimates
Characteristics of Weighted Likelihood Estimates • Less biased than MLE • Provides estimates for perfect and zero scores • BUT discrete scale & measurement error leads to bias in population parameter estimates
Plausible Values • What are plausible values? • Why do we use them? • How to analyse plausible values?
Purpose of educational tests • Measure particular students(minimise measurement error of individual estimates) • Assess populations(minimise error when generalising to the population)
Posterior distributionsfor test scores on 6 dichotomous items
Characteristics of EAPs • Biased at the individual level but unbiased population means (NOT variances) • Discrete scale, bias & measurement error leads to bias in population parameter estimates • Requires assumptions about the distribution of proficiency in the population
Score 4 Score 5 Score 6 Score 0 Score 1 Score 2 Score 3 Proficiency on Logit Scale Plausible Values
Characteristics of Plausible Values • Not fair at the student level • Produces unbiased population parameter estimates • if assumptions of scaling are reasonable • Requires assumptions about the distribution of proficiency
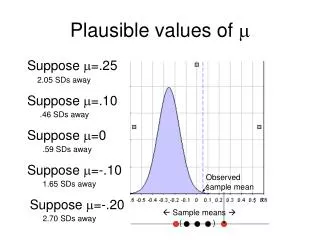
Estimating percentages below benchmark with Plausible Values Level One Cutpoint The proportion of plausible values less than the cut-point will be a superior estimator to the EAP, MLE or WLE based values
Methodology of PVs • Mathematically computing posterior distributions around test scores • Drawing 5 random values for each assessed individual from the posterior distribution for that individual
What is conditioning? • Assuming normal posterior distribution: • Model sub-populations:X=0 for boyX=1 for girl
Conditioning Variables • Plausible values should only be analysed with data that were included in the conditioning (otherwise, results may be biased) • Aim: Maximise information included in the conditioning, that is use as many variables as possible • To reduce number of conditioning variables, factor scores from principal component analysis were used in ICCS • Use of classroom dummies takes between-school variation into account (no inclusion of school or teacher questionnaire data needed)
Plausible values • Model with conditioning variables will improve precision of prediction of ability (population estimates ONLY) • Conditioning provides unbiased estimates for modelled parameters. • Simulation studies comparing PVs, EAPs and WLEs show that • Population means similar results • WLEs (or MLEs) tend to overestimate variances • EAPs tend to underestimate variance
Calculating of measurement error • As in TIMSS or PIRLS data files, there are five plausible values for cognitive test scales in ICCS • Using five plausible values enable researchers to obtain estimates of the measurement error
How to analyse PVs - 1 • Estimated mean is the AVERAGE of the mean for each PV • Sampling variance is the AVERAGE of the sampling variance for each PV
How to analyse PVs - 2 • Measurement variance computed as: • Total standard error computed from measurement and sampling variance as:
How to analyse PVs - 3 • can be replaced by any statistic for instance:- SD- Percentile- Correlation coefficient- Regression coefficient- R-square- etc.
Steps for estimating both sampling and measurement error • Compute statistic for each PV for fully weighted sample • Compute statistics for each PV for 75 replicate samples • Compute sampling error (based on previous steps) • Compute measurement error • Combine error variances to calculate standard error
Software that can handle PVs • Tailored macros (e.g. in SAS/SPSS) • IDB Analyser • SPSS Replicates module (ACER) • WESVAR • AM • HLM (for multilevel modelling)