Download
1 / 36
360 likes | 370 Views
This chapter provides a comprehensive overview of syntax analysis, including context-free grammar and regular expressions. It covers topics such as top-down and bottom-up parsing, automatic generation of parsers, lexical analyzers, intermediate representation, and more. The chapter also explores the comparison between regular expressions and context-free grammars. Suitable for computer science students and professionals.

E N D
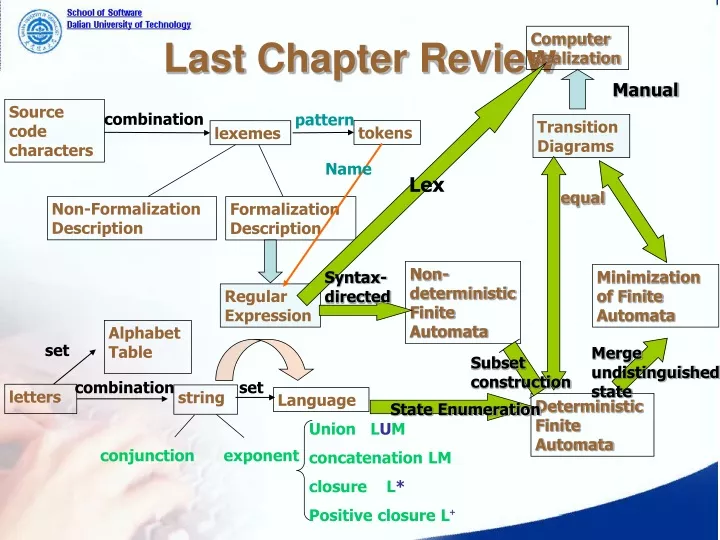
Last Chapter Review Source code characters Alphabet Table combination pattern set tokens lexemes combination set letters string Language Computer Realization Manual Transition Diagrams Name Lex equal Non-Formalization Description Formalization Description Non-deterministic Finite Automata Minimization of Finite Automata Syntax-directed Regular Expression Merge undistinguished state Subset construction Deterministic Finite Automata State Enumeration UnionLUM concatenationLM closureL* Positive closure L+ conjunctionexponent
Chapter 3 Syntax Analysis Contents Context-Free Grammars Top-Down Parsing and Bottom-Up Parsing Automatic generation of parser token Parse tree Rest of Front End Parser Lexical Analyzer Intermediate Representation Source program Get next token Symbol Table
object expression attribute object expression expression + noun (DLUT Student) Adjective expression expression (excellent) identifier * (initial) identifier (rate) num (60) syntax analysis:syntax token -〉syntax phrase(Parse Tree) initial + rate * 60 Excellent DLUT Student id + id * num Adjective noun
Lexical Analyzer(regular expression) character string token (context-free Grammar) expression Syntactic analyzer sentence Program block parse tree program
3.1 Context-free Grammar 3.1.1 Context-free Grammar Definition Regular Expression defines simple language, represents a fixed number of given structure repetition or not specified number of repetition ex:a (ba)5, a (ba)* Regular expression cannot define all expressions with properly balanced parentheses and nested block structure ex:set of paired parentheses strings, {wcw | w is a and b series}
3.1 Context-free Grammar Context-free Grammar is tetrad(VT , VN , S, P) VT: Terminals VN: Nonterminal S : start symbol P: productions,form of production: A ex( {id, +, *, , (, )}, {expr, op}, expr, P ) exprexpropexpr expr (expr) expr expr expr id op + op *
3.1 Context-free Grammar Simplified Representation Besides, 1)Uppercase letters late in the alphabet ,such as X,Y is either nonterminal or terminals 2)Lowercase letters late in the alphabet, like u,v,..represents strings of terminals. 3)Lowercase Greek letters represents strings of grammar symbols. 4)If A—>a1,A—>a2,then A—>a1|a2 Following symbols usually represent terminals 1)lowercase letters early in the alphabet, ex:a,b,c 2)Boldface string, ex:id, while 3)digit0,1,…,9 4)interpunction,ex:bracket,comma 5)Operation symbol,ex:+,- Following symbols usually represent nonterminal 1)uppercase letters early in the alphabet,ex:A,B,C 2)Letter S, usually represents start symbol 3)Lowercase ,ex:expr、stmt
3.1 Context-free Grammar Ex:( {id, +, *, , (, )}, {expr, op}, expr, P ) exprexpropexpr expr (expr) expr expr expr id op + op * Simplified representation E E A E | (E ) | E | id A + | *
3.1 Context-free Grammar Context-free Grammar E E A E | (E ) | E | id A + | * Comparison: Context-free Grammar & regular expression • Regular expression • letter [A-Za-z] • digit [0-9] • id letter(letter|digit)*
3.1 Context-free Grammar 3.1.2Derivations Productions are treated as rewriting rules, replaces a nonterminal by the body of one of its productions. exE E + E | E*E | (E ) | E | id E E (E) (E + E) (id + E) (id + id) Symbol S *、 S + w definition Sentential form、sentence、context-free language、equivalent grammars
3.1 Context-free Grammar E E + E | E*E | (E ) | E | id E E (E) (E + E) Leftmost derivation E lmE lm(E) lm(E + E) lm(id + E) lm (id + id) Rightmost derivation(canonical derivations) E rmE rm(E) rm(E + E) rm(E + id) rm (id + id) Leftmost derivation and rightmost derivation ? ?
3.1 Context-free Grammar 3.1.3 Parse Tree E E E E E E E E E E ( ) E ( ) E E E E E E E E E E E E E ( ) ( ) ( ) E E E ( ) ( ) ( ) E E E E E E E + E E + + E E E E + E E + + id id id id id id E lmE lm(E) lm(E + E) lm(id + E) lm (id + id) E rmE rm(E) rm(E + E) rm(E + id) rm (id + id)
3.1 Context-free Grammar 3.1.3 Ambiguity E E * EEE + E id * E E*E +E id *E + E id *E + E id * id + E id * id + E id * id + id id * id + id E E E E E + E * E E E E + * id id id id id id
3.2Language and Grammar Context-free Grammar advantage Grammar gives explicit, easy understanding expressions of the expression Automate generate high-efficiency parser Define language hierarchy Grammar-based language is more easier to modified Context-free Grammar disadvantage Grammar can only describes most of the expressions
3.2Language and Grammar 3.2.1Comparison: Regular Expression and Context-free Grammar Regular expression (a|b)*ab grammar A0aA0 | b A0 | aA1 A1bA2 A2 a 2 b begin a 1 0 b
3.2Language and Grammar 3.2.1Comparison: Regular expression and Context-free Grammar NFA Context-free Grammar confirm the terminals set For each state, create a nonterminal Ai If state I has a transition to state j on input a ,add the production AiaAj,if i is an accepting state,add Ai a 2 b start a 1 0 b NFA • Grammar • A0 aA0 | b A0 | aA1 • A1 bA2 • A2
3.2Language and Grammar 3.2.2 Reason for lexical parserdetach Why using regular expression defines the lexical Lexical rule is simple, do not need the context-free grammar. Using regular expression to describe lexical tokens is simple and easy to understand. Lexical analyzer based on regular expression is high-efficient.
3.2Language and Grammar Reason for detaching the lexical analyses from syntax parsing Simplify the design Improve the compiler’s efficiency Enhance the compiler’s portability Easy for partitioning compiler front-end Modules
3.2Language and Grammar 3.2.3Verifying the language Generated by a Grammar G : S (S ) S | L(G) =set of strings of balanced Parentheses
3.2Language and Grammar 3.2.3Verifying the language Generated by a Grammar G : S (S ) S | L(G) =set of strings of balanced parentheses Show that every sentence derivable is balanced. Inductive proof on the number of steps n in a derivation
3.2Language and Grammar 3.2.3Verifying the language Generated by a Grammar G : S (S ) S | L(G) = set of strings of balanced parentheses Inductive proof on the number of steps n in a derivation Basis: S hypothesis:less than nstep derivations produce balanced parentheses Procedure:n step leftmost derivation: S (S )S * (x) S * (x) y
3.2Language and Grammar 3.2.3Verifying the language Generated by a Grammar G : S (S ) S | L(G) = set of strings of balanced parentheses Induction on the length of a sting :balanced parentheses is derivable from S
3.2Language and Grammar 3.2.3Verifying the language Generated by a Grammar G : S (S ) S | L(G) = set of strings of balanced parentheses Induction on the length of a sting :balanced parentheses can be derivate by S Basis: S hypothesis :length less than 2n is derivable from S Procedure:consider length is2n(n 1)w = (x) yS (S )S * (x) S * (x) y
3.2Language and Grammar 3.2.4 Proper Expression Grammar Expression production:E E + E | E * E | (E ) | E | id Using a hierarchy view to see expression id * id * (id+id) + id * id + id E E E E E + E * E E E E + * id id id id id id
3.2Language and Grammar 3.2.4 Proper Expression Grammar Using a hierarchy view to see expression id * id * (id+id) + id * id + id id*id*(id+id)
3.2Language and Grammar 3.2.4 Proper Expression Grammar Using a hierarchy view to see expression id * id * (id+id) + id * id + id id*id*(id+id) Grammar exprexpr + term | term
3.2Language and Grammar 3.2.4 Proper Expression Grammar Using a hierarchy view to see expression id * id * (id+id) + id * id + id id*id*(id+id) Grammar exprexpr + term | term termterm* factor | factor
3.2Language and Grammar 3.2.4 Proper Expression Grammar Using a hierarchy view to see expression id * id * (id+id) + id * id + id id*id*(id+id) Grammar exprexpr + term | term termterm* factor | factor factor id | (expr)
3.2Language and Grammar exprexpr + term | term termterm* factor | factor factor id | (expr) expr expr expr term term + term factor term factor term * * term factor id factor * id factor factor id id id id Parse tree of id * id * id andid + id * id
3.2Language and Grammar 3.2.5 Eliminating Ambiguity stmt if expr then stmt | if expr then stmt else stmt | other Sentential form:if expr then if expr then stmtelse stmt Two Leftmost derivation: stmt if expr then stmt if expr then if expr then stmt else stmt stmt if expr then stmt else stmt if expr then if expr then stmt else stmt
3.2Language and Grammar non-Ambiguous Grammar stmtmatched _stmt | unmatched_stmt matched_stmt if expr then matched_stmt else matched_stmt | other unmatched_stmt if expr then stmt | if expr then matched_stmt else unmatched_stmt
3.2Language and Grammar 3.2.6 Elimination of Left Recursion Grammar left Recursion A+Aa Immediate left Recursion AAa |b String characterba . . . a Eliminate immediate left recursionA b A Aa A |
3.2Language and Grammar ex:Arithmetical Expression Grammar EE + T | T ( T + T . . . + T) TT*F | F ( F*F . . . *F ) F ( E ) | id Grammar after eliminate the left recursive ETE E + TE | TFT T *F T | F ( E ) | id
3.2Language and Grammar Non-Immediate left Recursion SAa | b ASd | Translate to Non-Immediate left Recursion S Aa | b AAad | bd | Then Eliminate left recursive S Aa | b A bd A| A A adA|
Exercise 3.1 3.2






















