Download
1 / 1
10 likes | 110 Views
X. Y. IR. PC 1. PC 1. PC 1. PC 1. t0. t1. t2. t3. t4. t5. t6. t7. t8. t9. t10. t11. t12. t13. t14. F. D. X. M. W. F. D. D. D. D. X. M. W. F. F. F. F. D. D. D. D. X. M. W. F. F. F. F. D. D. D. D. GPR1. GPR1. GPR1. GPR1. D$. +1. t0. t1.

E N D
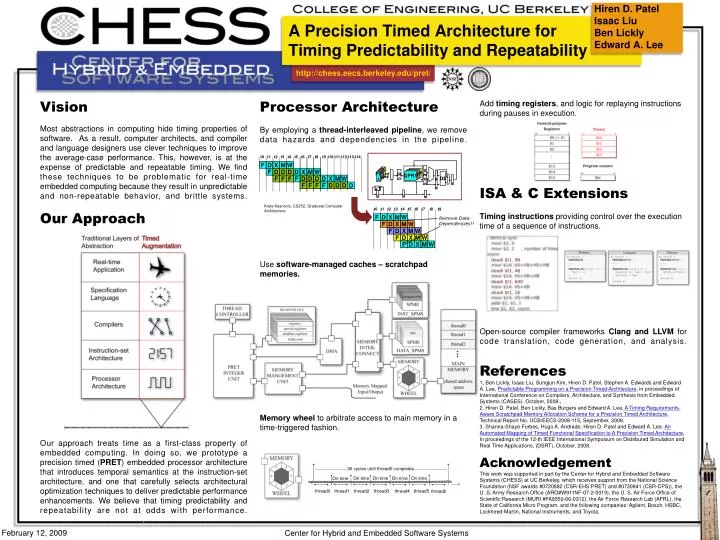
X Y IR PC 1 PC 1 PC 1 PC 1 t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 t11 t12 t13 t14 F D X M W F D D D D X M W F F F F D D D D X M W F F F F D D D D GPR1 GPR1 GPR1 GPR1 D$ +1 t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 F D X M W Remove Data Dependencies!! F D X M W F D X M W F D X M W F D X M W Hiren D. Patel Isaac Liu Ben Lickly Edward A. Lee A Precision Timed Architecture for Timing Predictability and Repeatability 90 cycles until thread0 completes Vision Most abstractions in computing hide timing properties of software. As a result, computer architects, and compiler and language designers use clever techniques to improve the average-case performance. This, however, is at the expense of predictable and repeatable timing. We find these techniques to be problematic for real-time embedded computing because they result in unpredictable and non-repeatable behavior, and brittle systems. . Our Approach Our approach treats time as a first-class property of embedded computing. In doing so, we prototype a precision timed (PRET) embedded processor architecture that introduces temporal semantics at the instruction-set architecture, and one that carefully selects architectural optimization techniques to deliver predictable performance enhancements. We believe that timing predictability and repeatability are not at odds with performance. . Processor Architecture By employing a thread-interleaved pipeline, we remove data hazards and dependencies in the pipeline. Use software-managed caches – scratchpad memories. Memory wheel to arbitrate access to main memory in a time-triggered fashion. Add timing registers, and logic for replaying instructions during pauses in execution. ISA & C Extensions Timing instructions providing control over the execution time of a sequence of instructions. Open-source compiler frameworks Clang and LLVM for code translation, code generation, and analysis. References 1. Ben Lickly, Isaac Liu, Sungjun Kim, Hiren D. Patel, Stephen A. Edwards and Edward A. Lee, Predictable Programming on a Precision Timed Architecture, in proceedings of International Conference on Compilers, Architecture, and Synthesis from Embedded Systems (CASES), October, 2008.. 2. Hiren D. Patel, Ben Lickly, Bas Burgers and Edward A. Lee, A Timing Requirements-Aware Scratchpad Memory Allocation Scheme for a Precision Timed Architecture, Technical Report No. UCB/EECS-2008-115, September, 2008. 3. Shanna-Shaye Forbes, Hugo A. Andrade, Hiren D. Patel and Edward A. Lee. An Automated Mapping of Timed Functional Specification to A Precision Timed Architecture, In proceedings of the 12-th IEEE International Symposium on Distributed Simulation and Real Time Applications, (DSRT), October, 2008. Acknowledgement This work was supported in part by the Center for Hybrid and Embedded Software Systems (CHESS) at UC Berkeley, which receives support from the National Science Foundation (NSF awards #0720882 (CSR-EHS:PRET) and #0720841 (CSR-CPS)), the U. S. Army Research Office (ARO#W911NF-07-2-0019), the U. S. Air Force Office of Scientific Research (MURI #FA9550-06-0312), the Air Force Research Lab (AFRL), the State of California Micro Program, and the following companies: Agilent, Bosch, HSBC, Lockheed-Martin, National Instruments, and Toyota. On time On time On time On time On time thread0 thread1 thread2 thread3 thread4 thread5 thread0 Krste Asanovic, CS252, Graduate Computer Architecture Center for Hybrid and Embedded Software Systems






















