Download
1 / 29
290 likes | 389 Views
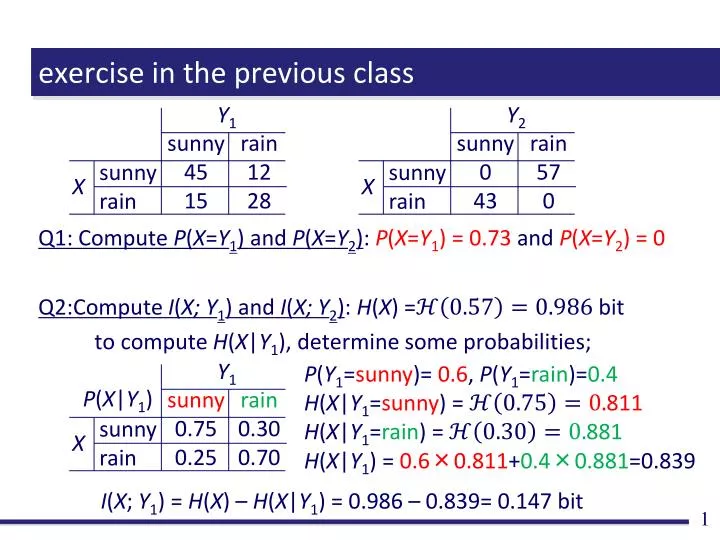
exercise in the previous class. Q1: Compute P ( X = Y 1 ) and P ( X = Y 2 ) : P ( X = Y 1 ) = 0.73 and P ( X = Y 2 ) = 0 Q2:Compute I ( X; Y 1 ) and I ( X; Y 2 ) : H ( X ) = bit to compute H ( X | Y 1 ), determine some probabilities;. Y 1. Y 2. Y 1. sunny 0.75 0.25. sunny

E N D
exercise in the previous class Q1: Compute P(X=Y1) and P(X=Y2): P(X=Y1) = 0.73 and P(X=Y2) = 0 Q2:Compute I(X; Y1) and I(X; Y2): H(X) = bit to compute H(X|Y1), determine some probabilities; Y1 Y2 Y1 sunny 0.75 0.25 sunny 0 43 sunny 45 15 rain 0.30 0.70 rain 12 28 rain 57 0 sunny rain sunny rain sunny rain P(Y1=sunny)= 0.6, P(Y1=rain)=0.4 H(X|Y1=sunny) =811 H(X|Y1=rain) =881 H(X|Y1) = 0.6×0.811+0.4×0.881=0.839 X X X P(X|Y1) I(X; Y1) = H(X) – H(X|Y1) = 0.986 – 0.839= 0.147 bit
exercise in the previous class (cnt’d) Q2:Compute I(X; Y1) and I(X; Y2): H(X) = bit to compute H(X|Y2), determine some probabilities; Y2 Y1 Y2 P(Y2=sunny)= 0.43, P(Y2=rain)=0.57 H(X|Y2=sunny) = H(X|Y2=rain) = H(X|Y2) = 0.43×0+0.57×0=0 sunny 45 15 sunny 0 1 sunny 0 43 rain 12 28 rain 57 0 rain 1 0 sunny rain sunny rain sunny rain X X X P(X|Y2) I(X; Y2) = H(X) – H(X|Y2) = 0.986 – 0= 0.986 bit Q3: Which is the better forecasting?Y2 gives more information.
the purpose of chapter 2 We learn how to encode symbols from information source. • source coding • data compression the purpose of source encoding: • to give representations which are good for communication • to discard (捨てる) redundancy (冗長性) We want a source coding scheme which gives ... • as precise (正確) encoding as possible • as compact encoding as possible 0101101 encoder source
plan of the chapter • basic properties needed for source coding • uniquely decodable • immediately decodable • Huffman code • construction of Huffman code • extensions of Huffman code • theoretical limit of the “compression” • related topics today
words and terms Meanwhile, we consider symbol-by-symbol encodings only. • M...the set of symbols generated by an information source. • For each symbol in M, associate a sequence (系列) over {0, 1}. • codewords(符号語): sequences associated to symbols in M • code (符号): the set of codewords • alphabet: {0, 1} in this case... binary code three codewords; 00, 010 and 101 code C = {00, 010 and 101} 011 is NOT a codeword, for example M sunny cloudy rainy C 00 010 101
encoding and decoding • encode ... to determine the codeword for a given symbol • decode... to determine the symbol for a given codeword encode = 符号化 decode = 復号(化) sunny cloudy rainy 00 010 101 encode decode • NO separation symbols between codewords; • 010 00 101 101 ... NG, 01000101101 ... OK Why? • {0, 1 and “space”} ... the alphabet have three symbols, not two
uniquely decodable codes • A code must be uniquelydecodable(一意復号可能). • Different symbol sequences are encoded to different 0-1 sequences. • uniquely decodable codewords are all different, but the converse (逆) does not hold in general. with the code C3... C1 00 10 01 11 C2 0 01 011 111 C3 0 10 11 01 C4 0 10 11 0 a1a3a1 a1 a2 a3 a4 0110 a4 a2 yes yes no no
more than uniqueness C1 00 10 01 11 C2 0 01 011 111 consider a scenario of using C2... • a1,a4, a4, a1is encoded to 01111110. • The 0-1 sequence is transmitted by 1 bit/sec. • When does the receiver find that the first symbol is a1? a1 a2 a3 a4 • seven seconds later, the receiver obtains 0111111: • if 0 comes next, then 0 - 111 - 111 - 0 a1, a4, a4, a1 • if 1 comes next, then 01 - 111 - 111 a2, a4, a4 • We cannot finalize the first symbol even in the seven seconds later. • buffer to save data, latency (遅延) of decoding...
immediately decodable codes • A code must be uniquely decodable, and if possible, it should be immediately decodable (瞬時復号可能). • Decoding is possible without looking ahead the sequence. • If you find a codeword pattern, then decode it immediately. important property from an engineering viewpoint. formally writing... • If is written as with and , then there is no and such that . ≠ c1 s1 c2 s2
prefix condition If a code is NOT immediately decodable, then there is such that with different and . the codewordis a prefix (語頭) of (c1 is the same as the beginning part of c2) Lemma: A code C is immediately decodable if and only if no codeword in C is a prefix of other codewords. (prefix condition, 語頭条件) C2 0 01 011 111 a1 a2 a3 a4 = c1 s1 “0” is a prefix of “01” and “011” “01” is a prefix of “011” c2 s2
break: prefix condition and user interface The prefix condition is important in engineering design. • bad example: strokes for character writing on Palm PDA graffiti (ver. 2) some needs of two strokes prefix condition violated “– –”, and “=”, “– 1” and “+” graffiti (ver. 1) basically one stroke only
how to achieve the prefix condition easy ways to construct codes with the prefix condition: • let all codewords have the same length • put a special pattern at the end of each codeword C = {011, 1011, 01011, 10011} ... “comma code” ... too straightforward • select codewords by using a tree structure (code tree) • for binary codes, we use binary trees • for k-ary codes, we use trees with degree k a code tree with degree 3
construction of codes (k-ary case) how to construct a k-ary code with Mcodewords • constructa k-arytree T with M leaf nodes • for each branch (枝) of T, assign a label in {0, ..., k– 1} • sibling (兄弟) branches cannot have the same label • for each of leaf nodes of T, traverseT from the root to the leaf, with concatenating (連接する) labels on branches the obtained sequence is the codeword of the node
0 0 00 0 0 1 1 01 0 0 10 1 1 1 1 11 example construct a binary code with four codewords Step 1 Step 2 Step 3 the constructed code is{00, 01, 10, 11}
1 0 0 1 0 1 1 0 0 0 0 1 0 0 1 1 1 1 0 1 0 example (cnt’d) other constructions; • we can choose different trees, different labeling... C1={0, 10, 110, 111} C2={0, 11, 101, 100} C3={01, 000, 1011, 1010} The prefix condition is always guaranteed. Immediately decodable codes are constructed.
1 0 0 1 0 1 1 0 0 0 0 0 1 1 1 the “best” among immediately decodable codes • C1 seems to give more compact representation than C3. • codeword length = [1, 2, 3, 3] Can we construct more compact immediately decodable codes? • codeword length = [1, 1, 1, 1]? • codewordlength = [1, 2, 2, 3]? • codewordlength = [2, 2, 2, 3]? C1={0, 10, 110, 111} C3={01, 000, 1011, 1010} ? What is the criteria (基準)?
Kraft’s inequality Theorem: A) If a k-ary code {c1, ..., cM} with |ci| = liis immediately decodable, then (Kraft’s inequality) holds. B) If , then we can construct a k-ary immediately decodable code {c1, ..., cM} with |ci| = li. proof omitted in this class ... use results of graph theory [trivia] The result is given in the Master’s thesis of L. Kraft.
back to the examples Can we construct more compact immediately decodable codes? • codeword length = [1, 2, 2, 3]? … We cannot construct an immediately decodable code. • codeword length = [2, 2, 2, 3]? … We canconstruct an immediately decodable code, by simply constructing a code tree....
to the next step • basic properties needed for source coding • uniquely decodable • immediately decodable • Huffman code • construction of Huffman code • extensions of Huffman code • theoretical limit of the “compression” • related topics today
the measure of efficiency • We want to construct a good source coding scheme. • easy to use ... immediately decodable • efficient ... what is the efficiency? We try to minimize... the expected length of a codeword for representing one symbol: symbol a1 a2 : aM probability p1 p2 : pM codeword c1 c2 : cM length l1 l2 : lM average codeword length
computing the average codeword length • C1: 0.4×1+0.3×2+ 0.2×3+ 0.1×3 = 1.9 • C2: 0.4×3+ 0.3×3+ 0.2×2+ 0.1×1 = 2.6 • C3: 0.4×2+ 0.3×2+ 0.2×2+ 0.1×2 = 2.0 It is expected that... C1 gives the most compact representation intypical cases. symbol a1 a2 a3 a4 probability 0.4 0.3 0.2 0.1 C1 0 10 110 111 C2 111 110 10 0 C3 00 01 10 11
Huffman code Huffman algorithm gives a clever way to construct a code with small average codeword length. • prepare isolated M nodes,each attached with a probability of a symbol (node = size-one tree) • repeat the following operation until all trees are joined to one • select two treesT1 and T2 having the smallest probabilities • join T1 and T2 by introducing a new parent node • the sum of probabilities of T1 and T2is given to the new tree David Huffman 1925-1999
0.15 0.6 A 0.25 B 0.1 C 0.05 D 0.6 A 0.25 B 0.1 C 0.05 D 1.0 0.4 0.4 1 0 1 0 0.15 0.15 0 1 0.6 A 0.25 B 0.1 C 0.05 D 0.6 A 0.25 B 0.1 C 0.05 D example “merger of small companies”
exercise • compare the average length with the equal-length codes... prob. 0.2 0.1 0.3 0.3 0.1 codewords A B C D E
exercise • compare the average length with the equal-length codes... prob. 0.3 0.2 0.2 0.1 0.1 0.1 codewords A B C D E F
different construction, same efficiency • We may have multiple options on the code construction: • several nodes have the same small probabilities • labels can be assigned differently to branches • Different option results in a different Huffman code, but... the average length does not depend on the chosen option. 0.4 a1 0.2 a2 0.4 a1 0.2 a2 0.2 a3 0.1 a4 0.1 a5 0.2 a3 0.1 a4 0.1 a5
summary of today’s class • basic properties needed for source coding • uniquely decodable • immediately decodable • Huffman code • construction of Huffman code • extensions of Huffman code • theoretical limit of the “compression” • related topics today
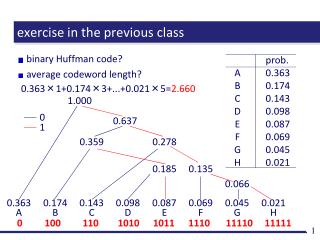
prob. 0.363 0.174 0.143 0.098 0.087 0.069 0.045 0.021 A B C D E F G H exercise • Construct a binary Huffman code for the information source given in the table. • Compute the average codeword length of the constructed code. • Can you construct a 4-ary Huffman code for the source?