Download
1 / 34
340 likes | 562 Views
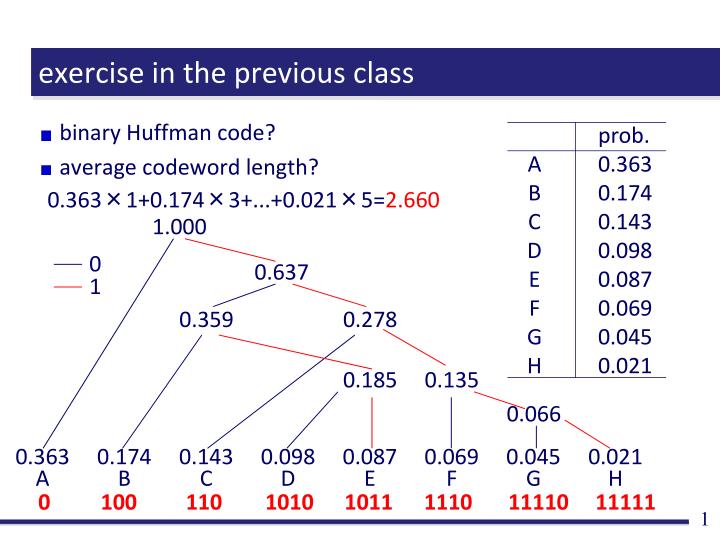
prob. 0.363 0.174 0.143 0.098 0.087 0.069 0.045 0.021. 0. A B C D E F G H. 1. exercise in the previous class. binary Huffman code? average codeword length?. 0.363 ×1+0.174 ×3+...+0.021×5= 2.660. 1.000. 0.637. 0.359. 0.278. 0.185. 0.135. 0.066. 0.363 A. 0.174 B.

E N D
prob. 0.363 0.174 0.143 0.098 0.087 0.069 0.045 0.021 0 A B C D E F G H 1 exercise in the previous class • binary Huffman code? • average codeword length? 0.363×1+0.174×3+...+0.021×5=2.660 1.000 0.637 0.359 0.278 0.185 0.135 0.066 0.363 A 0.174 B 0.143 C 0.098 D 0.087 E 0.069 F 0.045 G 0.021 H 0 100 110 1010 1011 1110 11110 11111
prob. 0.363 0.174 0.143 0.098 0.087 0.069 0.045 0.021 A B C D E F G H exercise in the previous class • 4-ary Huffman code? [basic idea] join four trees • we may have #trees < 4 in the final round. • with one “join”, 4 – 1 = 3 trees disappear. • add dummy nodes, start with 3k+1 nodes. ? dummy 1.000 d 0.320 a 0.066 b c 0.363 A 0.174 B 0.143 C 0.098 D 0.087 E 0.069 F 0.045 G 0.021 H 0 * 0 * a b c da db dc dda ddb
today’s class • basic properties needed for source coding • uniquely decodable • immediately decodable • Huffman code • construction of Huffman code • extensions of Huffman code • theoretical limit of the “compression” • related topics today
today’s class (detail) • Huffman codes are good, but how good are they? • Huffman codes for extended information sources • possible means (手段) to improve the efficiency • Shannon’s source coding theorem • the theoretical limit of efficiency • some more variations of Huffman codes • blocks of symbols with variable block length math. algorithm math. algorithm
0 0 0 1 1 1 how should we evaluate Huffman codes? good code • immediately decodable...“use code trees” • small average codewordlength (ACL) It seems that Huffman’s algorithm gives a good solution. To see that Huffman codes are really good, we discuss a mathematical limit of the ACL • ...under a certain assumption (up to the slide 11) • ...in the general case (Shannon’s theorem)
theoretical limit under an assumption assumption • the encoding is done in a symbol-by-symbol manner • define one codeword for each symbol of the source S • S produces M symbols with probabilities p1, ..., pM Lemma (restricted Shannon’s theorem): • for any code, the ACL ≥ H1(S) • a code with ACL ≤H1(S)+1 is constructible H1(S) is the borderline of “possible” and “impossible”.
Shannon’s lemma (bad naming...) To prove the restricted Shannon’s theorem a small technical lemma (Shannon’s lemma) is needed. Shannon’s lemma (シャノンの補助定理) For any non-negative numbers q1, ..., qM with q1 +...+ qM≤ 1, with the equation holds if and only if pi = qi. remind: p1, ..., pM are symbol probabilities and p1 +...+ pM= 1
proof (sketch) left hand side – right hand side= y = – logex 1 O y = 1 – x the equation holds iffqi/pi = 1
proof of the restricted Shannon’s theorem: 1 for any code, the average codeword length ≥ H1(S) Let l1, ..., lM be the length of codewords, and define . • Kraft: • Shannon’s Lemma: • the ACL • We have shown that L ≥ H1(S).
proof of the restricted Shannon’s theorem: 2 a code with average codeword length ≤H1(S)+1 is constructible Choose integers l1, ..., lM so that . • The choice makes , and ... Kraft’s inequality • We can construct a code with codeword length l1, ..., lM, whose ACL is
the lemma and the Huffman code Lemma (restricted Shannon’s theorem): • for any code, the ACL ≥ H1(S) • a code with ACL ≤H1(S)+1 is constructible We can show that, for a Huffman code, • L≤H1(S) + 1 • there is no symbol-by-symbol code whose ACL is smaller than L. proof ... by recursion on the size of code trees • A Huffman code is said to be a compact code.
symbol A B average prob. 0.8 0.2 C1 0 1 1.0 C2 1 0 1.0 A A A B C C 10 11 11 0 0 0 coding for extended information sources The Huffman code is the best symbol-by-symbol code, but... • the ACL 1 • not good for encoding binary information sources If we encode severalsymbols in a block, then... • the ACL per symbolcan be < 1 • good for binary sources also A B A C C A 10 110 01
block Huffman coding message ABCBCBBCAA... • fixed-length (equal-, constant-) • variable-length (unequal-) • block partition • run-length “block” operation blocked message ABCBCBBCAA... Huffman encoding codewords 01 10 001 1101...
fixed-length block Huffman coding • ACL: 0.6×1+0.3×2+ 0.1×2 = 1.4 bit for one symbol prob. 0.6 0.3 0.1 codeword 0 10 11 A B C blocks with two symbols • ACL: 0.36×1+ ... + 0.01×6 = 2.67 bit, but this is for two symbols • 2.67 / 2 = 1.335 bit for one symbol prob. 0.36 0.18 0.06 0.18 0.09 0.03 0.06 0.03 0.01 codeword 0 100 1100 101 1110 11110 1101 111110 111111 AA AB AC BA BB BC CA CB CC improved!
block coding for binary sources • ACL: 0.8×1+ 0.2×1 = 1.0 bit for one symbol prob. 0.8 0.2 codeword 0 1 A B blocks with two symbols • ACL: 0.64×1+ ... + 0.04×3 = 1.56 bit for two symbols • 1.56 / 2 = 0.78 bit for one symbol prob. 0.64 0.16 0.16 0.04 codeword 0 10 110 111 AA AB BA BB improved!
block size 1 2 3 : ACL per symbol 1.0 0.78 0.728 : the block length prob. 0.512 0.128 0.128 0.032 0.128 0.032 0.032 0.008 codeword 0 100 101 11100 110 11101 11110 11111 blocks with three symbols • ACL: 0.512×1+ ... + 0.008×5 = 2.184 bit for three symbols • 2.184 / 3 = 0.728 bit for one symbol AAA AAB ABA ABB BAA BAB BBA BBB larger block size more compact
block code and extension of information source What happens if we increase the block length further? Observe that... • a block code defines a codewordfor each block pattern. • one block = a sequence of n symbols of S = one symbol of Sn, the n-th order extension of S restricted Shannon’s theorem is applicable: H1(Sn) ≤ Ln < H1(Sn) + 1 • Ln = the ACL for n symbols • for one symbol of S,
Shannon’s source coding theorem • H1(Sn) / n ... the n-th order entropy of S (→ Apr. 12) • If n goes to the infinity... Shannon’s source coding theorem: for any code, the ACL ≥ H(S) a code with ACL ≤H(S) + εis constructible
what the theorem means • Shannon’s source coding theorem: • for any code, the ACL ≥ H(S) • a code with ACL ≤H(S) + ε is constructible • Use block Huffman codes, and you can approach to the limit. • You never overcome the limit. however. prob. 0.8 0.2 block size 1 2 3 : ACLper symbol 1.0 0.78 0.728 : 0.723 + ε A B H(S) = 0.723
remark 1 Why block codes give smaller ACL? • fact 1: the ACL is minimized by a real-numbersolution • if P(A) = 0.8, P(B) = 0.2, then we want l1 and l2 with... s.t. • fact 2: the length of a codeword must be an integer ...loss! ...gain! s.t. and integers frequent loss, seldom gain...
remark 1 (cnt’d) • the gap between the ideal and the realcodeword lengths: ... is an integer approximation of • the gap is weighted by the probability… the weighted gap long block many symbols small probabilities small weighted gaps close to the ideal ACL p
today’s class (detail) • Huffman codes are good, but how good are they? • Huffman codes for extended information sources • possible means (手段) to improve the efficiency • Shannon’s source coding theorem • the theoretical limit of efficiency • some more variations of Huffman codes • blocks of symbols with variable block length math. algorithm math. algorithm
practical issues (問題) of block coding • Theoretically saying, the block Huffman codes are the best. • From practical viewpoint, there are several problems: • We need to know the probability distribution in advance. (this will be discussed in the next class) • We need a large table for the encoding/decoding. • if one byte is needed to record one entry of the table... • 256 byte table, if block length = 8 • 64 Kbyte table, if block length = 16 • 4 Gbytetable, if block length = 32
use blocks with variable-length prob. 0.512 0.128 0.128 0.032 0.128 0.032 0.032 0.008 codeword 0 100 101 11100 110 11101 11110 11111 If we define blocks so that they have the same length, then ... • some blocks have small probabilities • those blocks also need codewords If we define blocks so that they have similar probabilities, then ... • length differ from block by block • the table has little useless blocks AAA AAB ABA ABB BAA BAB BBA BBB prob. 0.512 0.128 0.16 0.2 codeword 0 100 101 11 AAA AAB AB B
definition of block patterns Block patterns must be defined so that... the patterns can represent (almost) all symbol sequences. • bad example: block pattern = {AAA, AAB, AB} AABABAAB AAB AB AAB AABBBAAB AAB ? two different approaches are well-known; • block partition approach • run-length approach
AA AB B 0.64 0.16 0.2 A B 0.8 0.2 define patterns with block partition approach • prepare all blocks with length one • partition the block with the largest probability by appending one more symbol • go to 2 Example: P(A) = 0.8, P(B) = 0.2 codewords AAA AAB AB B 0.512 0.128 0.16 0.2 0 100 101 11
how good is this? to determine the average codeword length, assume that n blocks are produced from S: AAA AAB AB B 0.512 0.128 0.16 0.2 0 100 101 11 S AAA AB AAA B AB ... 0 101 0 11 101 ... encode • 0.512n×1 + 0.128n×3 ... • = 1.776n bits • 0.512n×3 + 0.128n×3 ... • = 2.44n symbols 2.44n symbols are encoded to 1.776n bits the average codewordlength is 1.776n / 2.44n = 0.728 bit (almost the same as the block length = 8, p. 16, but small table)
define patterns with run-length approach run = a sequence of consecutive (連続の) identical symbol Example: divide a message into runs of “A”: A B B A A A A A B A A A B run of length = 3 run of length = 1 run of length = 0 run of length =5 The message is constructible if the lengths of runs are given. define blocks as runs of various length
upper-bound the run-length small problem? ... there can be very long run put an upper-bound limit : run-length limited (RLL) coding upper-bound = 3 • ABBAAAAABAAAB is represented as • one “A” followed by B • zero“A” followed by B • three or more “A”s followed by B • two“A”s followed by B • three or more “A”s followed by B • zero “A” followed by B run length 0 1 2 3 4 5 6 7 : representation 0 1 2 3+0 3+1 3+1 3+3+0 3+3+1 :
run-length Huffman code • Huffman code defined to encode the length or runs • effective when there is strong bias on the symbol probabilities p(A) = 0.9, p(B) = 0.1 run length 0 1 2 3 or more block pattern B AB AAB AAA prob. 0.1 0.09 0.081 0.729 codeword 10 110 111 0 • ABBAAAAABAAAB: 1, 0, 3+, 2, 3+, 0 ⇒ 110 10 0 111 0 10 • AAAABAAAAABAAB: 3+, 1, 3+, 2, 2 ⇒ 0 110 0 111 111 • AAABAAAAAAAAB: 3+, 0, 3+, 3+, 2 ⇒ 0 10 0 0 111
example of various block coding • S: memoryless & stationary. P(A) = 0.9, p(B) = 0.1 • the entropy of S is H(S) = –0.9log20.9 – 0.1log20.1=0.469 bit symbol A B prob. 0.9 0.1 codeword 0 1 • code 1: a naive Huffman code average codeword length = 1 • code 2: fixed-length (3bit) average codeword length = 1.661/3symbols = 0.55/symbol AAA AAB ABA ABB 0.729 0.081 0.081 0.009 0 100 110 1010 BAA BAB BBA BBB 0.081 0.009 0.009 0.009 1110 1011 11110 11111
example of various block coding (cnt’d) with n blocks... • 0.1n×1 + ... + 0.478n×7 = 5.215n symbols • 0.1n×3 + ... + 0.478n×1 = 2.466n bits the average codeword length per symbol = 2.466 / 5.215 = 0.47 • code 3: run-length Huffman (upper-bound = 8) length 0 1 2 3 prob. 0.1 0.09 0.081 0.073 codeword 110 1000 1001 1010 length 4 5 6 7+ prob. 0.066 0.059 0.053 0.478 codeword 1011 1110 1111 0
summary of today’s class • Huffman codes are good, but how good are they? • Huffman codes for extended information sources • possible means (手段) to improve the efficiency • Shannon’s source coding theorem • the theoretical limit of efficiency • some more variations of Huffman codes • blocks of symbols with variable block length
exercise • Write a computer program to construct a Huffman code for a given probability distribution. • Modify the above program so that it can handle fixed-length block coding. • Give distribution, change the block length, and observe how the average codeword length changes according to the change.