Download

1 / 21
440 likes | 922 Views
Searching the Internet. CSCI-N 100 Department of Computer and Information Science. Searching the Internet. What is the Internet Does anyone own the Internet How is the Internet controlled. The Internet…. It is not a centrally owned or organized institution. It is not a single entity.

E N D
Searching the Internet CSCI-N 100 Department of Computer and Information Science
Searching the Internet • What is the Internet • Does anyone own the Internet • How is the Internet controlled
The Internet… • It is not a centrally owned or organized institution. • It is not a single entity. • It is not a 'Den of Iniquity' • It is not crawling with eight - year - old children controlling nuclear bombs. • The Internet is not a hive of viruses waiting to attack your computer. • The Internet is not just for pimple-faced teenagers with propeller beanies.
The Internet… • Is a vast repository of information. • Is relatively universal • Is dynamic – changing minute-by-minute
The Internet • InterNIC • - Internet Network Information Center - An international coalition of Internet organization that has what control there is of the Internet • IAB • - Internet Architecture Board - An organization that sets standards for the Internet • ICANN • - Internet Corporation for Assigned Names and Numbers – An organization responsible for the global coordination of the Internet's system of unique identifiers • W3C • World Wide Web Consortium - develops interoperable technologies, specifications, guidelines, software, and tools
Search engines • Search Engines • an information retrieval system • allows one to ask for content meeting specific criteria • list is often sorted with respect to some measure of relevance of the results • use regularly updated indexes to operate quickly and efficiently
Search engines • First search engines • Archie - archive" without the "v" • created in 1990 by a student at in Montreal • program downloaded the directory listings of all the files located on public anonymous FTP (File Transfer Protocol) sites • creating a searchable database of filenames • could not search by file contents
Search engines • Gopher • indexed plain text documents • created in 1991 at the University of Minnesota: Gopher was named after the school's mascot • most of the Gopher sites became websites after the creation of the World Wide Web because these were text files
Search engines • Veronica (Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) • provided a keyword search of most Gopher menu titles in the entire Gopher listings • Jughead (Jonzy's Universal Gopher Hierarchy Excavation And Display) • a tool for obtaining menu information from various Gopher servers
And the answer is … • People have trouble with • How to ask • What to ask • Where to ask • When to ask
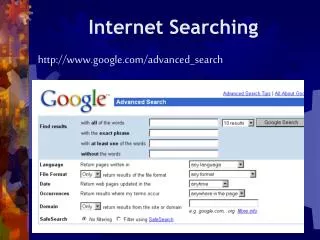
How to ask • Search criteria • Build a query • Date • File name • Location • Keyword • Domain • Country
How to ask • Boolean phrases • And, + (plus) • Finds documents containing all of the specified words or phrases • Peanut AND butter finds documents with both the word peanut and the word butter. • Or • Finds documents containing at least one of the specified words or phrases • Peanut OR butter finds documents containing either peanut or butter. The found documents could contain both items, but not necessarily. • Not, - (minus) • Excludes documents containing the specified word or phrase • Peanut NOT butter finds documents with peanut but not containing butter • Wild card (*) • Finds documents with just given information, * fills in the rest • Pea* returns all pages with the phrase pea (Be Careful!!)
What to ask • All of these words • Documents must contain all of the words you list • This exact phrase • Documents must contain these exact words in the order you typed them • Any of these words • Documents must contain at least one of the words you list • None of these words • Documents that contain these words will be omitted from your results
Where to ask • Search engines • Do not really search the World Wide Web directly • Searches a database of the full text of web pages selected from the billions of web pages out there residing on servers • Search engine databases are selected and built by computer robot programs called “spiders” • After spiders find pages, they pass them on to another computer program for "indexing."
Types of Search Tools • Search engines • built by computer robot programs ("spiders") -- not by human selection • NOT organized by subject categories -- all pages are ranked by a computer algorithm • contain full-text (every word) of the web pages they link to -- you find pages by matching words in the pages you want • huge and often retrieve a lot of information -- for complex searches use ones that allow you to search within results • Unevaluated -- contain the good, the bad, and the ugly -- YOU must evaluate everything you find • Google, Yahoo, Ask.com
Types of Search Tools • Subject directories • built by human selection -- not by computers or robot programs • organized into subject categories, classification of pages by subjects -- subjects not standardized and vary according to the scope of each directory • NEVER contain full-text of the web pages they link to -- you can only search what you can see (titles, descriptions, subject categories, etc.) -- use broad or general terms • small and specialized to large, but smaller than most search engines -- huge range in size • often carefully evaluated and annotated (but not always!!)
Directories • Librarians Index • www.lii.org • Infomine • infomine.ucr.edu • AcademicInfo • www.academicinfo.us • About.com • www.about.com • Google Directory • directory.google.com • Yahoo! • dir.yahoo.com
Types of Search Tools • Searchable database contents or the "Invisible Web" • Invisible Web is estimated to offer two to three times as many pages as the visible web • Pages in non-HTML formats (pdf, Word, Excel, Corell suite, etc.) are "translated" into HTML • Script-based pages, whose links contain a ? or other script coding, no longer cause most search engines to exclude them • Pages generated dynamically by other types of database software (e.g., Active Server Pages, Cold Fusion) can be indexed if there is a stable URL somewhere that search engine spiders can find
Types of search engines • Meta-Search Engines • submit keywords in its search box • it transmits your search simultaneously to several individual search engines and their databases of web pages • Meta-search engines do not own a database of Web pages • Examples • Dopgpile.com • Clusty.com • Surfwax.com
References • Module #8: Communication and Internet protocols • http://www.cs.iupui.edu/~aharris/mmcc/mod8/abip.html • Module #2: Communication and the World Wide Web • http://www.cs.iupui.edu/~aharris/mmcc/mod2/abwww.html • World Wide Web Consortium • http://www.w3.org/ • Search engine • http://en.wikipedia.org/wiki/Search_engine
References • The BEST Search EnginesUC Berkeley - Teaching Library Internet Workshops • http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/SearchEngines.html • http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/FindInfo.html