Download
1 / 25
260 likes | 866 Views
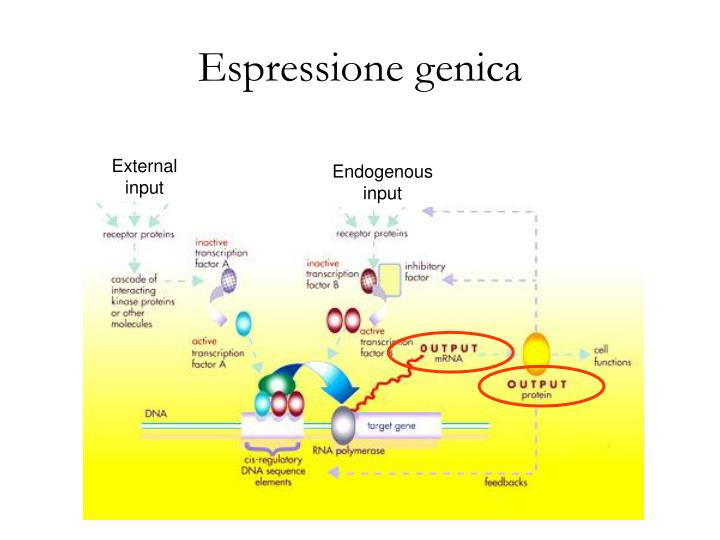
Espressione genica. External input. Endogenous input. Microarray per l’analisi dell’espressione genica. Diagramma di flusso operativo di un esperimento microarray. definizione dell’ipotesi biologica indagata identificazione di fattori di confondimento e schema di ibridazione

E N D
Espressione genica External input Endogenous input
Diagramma di flusso operativo di un esperimento microarray • definizione dell’ipotesi biologica indagata • identificazione di fattori di confondimento e schema di ibridazione • valutazione dei vincoli economici • valutazione dei limiti di gestione • estrazione dell’mRNA • marcatura dell’mRNA • ibridazione • lavaggio • asciugatura • scansione • “gridding” e quantizzazione numerica delle intensità di fluorescenza • estrazione delle intensità di “foreground” e di “background” • “quality control” dei dati grezzi • sottrazione del “background” • correzione degli errori sistematici attraverso la normalizzazione • verifica dell’effetto del pre-trattamento dei dati • applicazione di test statistici per determinare quali sono i geni differenzialmente espressi • validazione dei risultati con RTq-PCR • “pathway analysis” per l’interpretazione biologica dei risultati • annotazione dei risultati nelle banche dati • strutturazione secondo lo standard MIAME dell’informazione contenuta nell’esperimento • sottomissione delle informazioni a database per la pubblicazione dei dati Disegno dell’esperimento Preparazione dei campioni ed ibridazione Quantizzazione dei dati grezzi Pre-trattamento e normalizzazione dei dati Analisi statistica, validazione e annotazione dei risultati Sottomissione dell’esperimento a database pubblici
Da levare??? Categorie di esperimenti microarray Classi predefinite • Class comparison • Class prediction • Class discovery • Confrontare il livello medio di espressione fra gruppi di campioni e stabilire quali sono i geni responsabili di eventuali differenze • identificare geni differenzialmente espressi in differenti condizioni sperimentali: • - campioni da linee cellulari che contengono BRCA1 mutato vs campioni che contengono • BRCA1 non mutato • - campioni di cervello di ratti trattati con un farmaco vs campioni di cervello di ratti non trattati Classi non predefinite • Sviluppare profili di espressione genica differenziale da utilizzare come predittori dell’appartenenza di campioni a classi • generazione di signature tumorali • generazioni di profili di espressione che sono caratteristici di determinati stadi di crescita di una • cellula Classi non predefinite • Trovare un nuovo sistema di classificazione di campioni sulla base del profilo di espressione genica (cluster analysis) • identificare nuove sottoclassi di tumori
Il confronto fra le due classi è indiretto ed è realizzato attraverso il campione Reference (A vs R) vs (B vs R) Il confronto fra le due classi è diretto. Ciascun campione è ibridizzato due volte, con due fluorofori, su due array differenti Il confronto fra le due classi è diretto. Per ciascun gruppo (classe) metà dei campioni sono marcati con un fluorocromo e metà con l’altro Disegni sperimentali per class comparison Non-Reference-sample (Ai, Bi,…): tutti i campioni di interesse biologico Reference-sample (R): campione senza significato biologico che serve da baseline comune per la valutazione dell’espressione relativa fra i non-reference-sample • Reference Design • Loop Design • Balanced Block Design
Def: Efficienza ~ 1/varianza delle stime Obiettivo dell’esperimento microarray Precisione (efficienza) nella stima delle differenze fra le due classi Come disegno un esperimento efficiente? “Posso comprare solo 10 array (non ho problemi a reperire campioni).” “Ho solo 10 campioni (non ho problemi a comprare array).”
Reference Design # sample per classe = 5 # array totali = 10 Loop Design # sample per classe = 5 # array totali = 10 Balanced Block # sample per classe = 10 # array totali = 10 “Posso comprare solo 10 array “ …ma posso collezionare i campioni che mi servono • Efficienza: stima più precisa della media delle differenze fra le due popolazioni • ibridizzazione di più campioni possibile sui microarray a disposizione
RD LD BBD Balanced Block # sample per classe = 10 # sample totali = 20 “Posso comprare solo 10 array “ …ma posso collezionare i campioni che mi servono Svantaggi: - Poca tolleranza alle variazioni (variazione nell’appartenenza alle classi, perdita di un vetrino, etc)
“Ho solo 10 campioni “ …ma posso comprare gli array che mi servono • Efficienza: stima più precisa delle intensità dei singoli campioni • ibridizzazione di più array Reference Design # sample per classe = 5 # array totali = 10 Balanced Block # sample per classe = 5 # array totali = 5
“Ho solo 10 campioni “ …ma posso comprare gli array che mi servono Reference Design # sample per classe = 5 # array totali = 10 Svantaggi: - Collezione di innumerevoli informazioni “inutili” sul campione di Reference RD BBD
Balanced Block Design Reference Design Come si determina la numerosità n in maniera efficiente? Non conosciamo le limitazioni sul numero di array da acquistare o di campioni da collezionare • Per testare l’ipotesi nulla di assenza di espressione genica differenziale bisogna fissare: • un livello α di significatività • un livello 1-β di potenza • l’effect-size δ da detettare (fold change) • i livelli di varianza σ2 o τ2 dei dati • il disegno sperimentale
Fase “wet” di un esperimento microarray Estrazione mRNA Retrotrascrizione e Marcatura Ibridazione Scansione
Scansione del vetrino • Scanner a due laser • Lunghezze d’onda di eccitazione dei fluorocromi • 635 nm - Red • 532 nm - Green • Canali separati in acquisizione • formazione di due immagini • Codifica su 16 bit • 2^16 = 65536 livelli di colore • Occupazione di memoria • 130 MB c.a.
Scatterplot MAplot A =½ log (R*G) M = log (R/G) Imageplot Boxplot PCA 2D Metodi di visualizzazione dei dati
Metodi di sottrazione del “background” Subtract In =If – Ib Minimum In = If – Ib se I>0 In = min(If – Ib >0) se I<0 Normexp+offset (Ritchie et al, 2007) Ib~ N(μ, σ2) If ~ exp(λ)
Risultati Dati grezzi Subtract Minimum Normexp+ offset
Metodi di normalizzazione Diversa efficienza di incorporazione dei due fluorocromi; Diversa efficienza di emissione dei due fluorocromi; Diversa efficienza dello scanner nel leggere i due canali. Correzione degli errori sistematici generati dalla procedura sperimentale Sistema di rivelazione per fluorescenza
Metodi di normalizzazione within array Ciascun array viene normalizzato separatamente Obiettivo: centrare su ciascun array la distribuzione dei log-fold-change ed eliminare gli errori intensità-dipendenti - Trasformazione linlog per attenuare l’effetto della sottrazione del rumore alle basse intensità, i dati di intensità sono presi in scala lineare alle basse intensità e in scala logaritmica alle medie e alte intensità - Metodo globale: median o centraggio della mediana valutazione dello scostamento della mediana (o media) della distribuzione reale dei log-fold-change da quella ideale ed eliminazione - Metodo intensità-dipendente: LOESS interpolazione di polinomi di primo e secondo grado a finestre di dati per determinare la “smoothing curve”. Tale curva viene utilizzata sulla visualizzazione MA dei dati per riportare la distribuzione reale dei dati a quella reale
Metodi di normalizzazione between arrays Tutte le copie biologiche dello stesso gruppo vengono normalizzate insieme Obiettivo: eliminare gli errori sistematici che possono rendere eterogenei array biologicamente simili - Metodo scale riscalatura della dispersione dei log-fold-change fra array per equilibrare i valori di M fra array - Metodo di sostituzione dei quantili: quantile riscalatura dei valori delle intensità assolute fra array per uniformare le distribuzioni
Risultati linlog median LOESS
Risultati scale
Risultati quantile
Esperimento ApoAI Knockout Materiali e metodi: - 16 topi C57BL/6 “black six” - in 8 topi è stato “spento” il gene che codifica per l’apolipoproteina AI - per ciascun topo è stato estratto l’RNA dal fegato, è stato isolato l’mRNA, è stato retrotrascritto in cDNA e marcato con un fluorocromo rosso Cianina Cy5 - il cDNA marcato di ciscun topo è stato mescolato con un’aliquota di un campione di riferimento, ottenuto facendo il pool degli RNA degli 8 topi di controllo e marcando il materiale così ottenuto con il fluorocromo verde Cianina Cy3 - le 16 miscele sono state ibridizzate su 16 microarray distinti
Esperimento Swirl zebrafish Materiali e metodi: - 2 pesci zebra - in 1 pesce è presente una mutazione sul gene BMP2 - per ciascun pesce è stato estratto l’RNA, è stato isolato l’mRNA, è stato retrotrascritto in cDNA. Il cDNA di ogni pesce è stato diviso in quattro aliquote. - Due aliquote di cDNA di pesce mutato sono state marcate con il fluorocromo rosso Cianina Cy5 e le altre due con il fluorocromo verde Cianina Cy3. Analogamente per il cDNA del pesce wild-type. - il disegno sperimentale è di tipo diretto con dye-swap