Download

1 / 24
240 likes | 255 Views
Learn about the significance of web crawlers for indexing, focused crawling techniques, considerations like URL prioritization, content freshness, load minimization, and the future ambitions of these crawling tools. Explore parallel crawling strategies for efficient web exploration and evaluation of content quality.

E N D
Web Crawlers IST 497 Vladimir Belyavskiy 11/21/02
Overview Introduction to Crawlers Focused Crawling Issues to consider Parallel Crawlers Ambitions for the future Conclusion
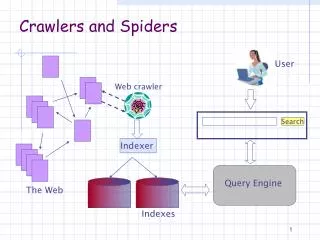
Introduction What is a crawler? Why are crawlers important? Used by many Main use is to create indexes for search engines Tool was needed to keep track of web content In March of 2002 there were 38,118,962 web sites
Focused Crawling Focused Crawler: selectively seeks out pages that are relevant to a pre-defined set of topics. Topics specified by using exemplary documents (not keywords) Crawl most relevant links Ignore irrelevant parts. Leads to significant savings in hardware and network resources.
Issues to consider Where to start crawling? Keyword search User specifies keywords Search for given criteria Popular sites are found using weighted degree measures Approached used for 966 Yahoo category searches (ex Business/Electronics) Users input User gives document examples Crawler compared documents to find matches
Issues to consider URLs found are stored in a queue, stack or a deck Which link do you crawl next? Ordering metrics: Breadth-First URLs are placed in the queue in order discovered First link found is the first to crawl
Issues to consider Backlink count Counts the number of links to the page Site with greatest # of links is given priority Page Rank backlinks are also counted Popular backlinks are given extra value (Ex. Yahoo) Works the best
Issues to consider What pages should crawler download? Not enough space Not enough time How to keep content fresh? Fixed Order - Explicit list of URL’s to visit Random Order – Start from seed and follow links Purely Random – Refresh pages on demand
Issues to consider Estimate frequency of changes Visit pages once a week for five weeks Estimate change frequency Adjust revisit frequency based on the estimate Most effective method
Issues to consider How to minimize the load on visited pages? Crawler should obey the constraints Crawler html tags Robot.txt file User-Agent: * Disallow: / Spider Traps
Parallel Crawlers Web is too big to be crawled by a single crawler, work should be divided Independent assignment Each crawler starts with its own set of URLs Follows links without consulting other crawlers Reduces communication overhead Some overlap is unavoidable
Parallel Crawlers Dynamic assignment Central coordinator divides web into partitions Crawlers crawl their assigned partition Links to other URLs are given to Central coordinator Static assignment Web is partitioned and divided to each crawler Crawler only crawls its part of the web
Evaluation Content Quality better for single-process crawler Overlap in most multiple processors or they don’t cover all of the content Overall crawlers are useful tools
Future Query interface pages Ex. http://www.weatherchannel.com Detect web page changes better Separate dynamic from static content Share data better between servers and crawlers
Bibliography Cheng, Rickie & Kwong, April. April 2000 http://sirius.cs.ucdavis.edu/teaching/289FSQ00/project/Reports/crawl_init.pdf. Cho, Junghoo. http://rose.cs.ucla.edu/~cho/papers/cho-thesis.pdf 2002. Dom, Brian. http://www8.org/w8-papers/5a-search-query/crawling/March1999. Polytechnic University, CIS Department http://hosting.jrc.cec.eu.int/langtech/Documents/Slides-001220_Scheer_OSILIA.pdf
The End Any Questions?