Download

1 / 19
190 likes | 206 Views
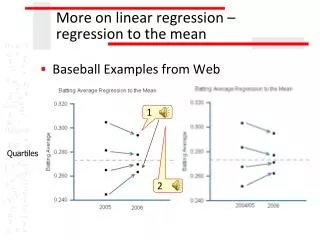
More on regression. Petter Mostad 2005.10.24. More on indicator variables. If an independent variable is an indicator variable, cases where it is 1 will just have an addition to the constant term

E N D
More on regression Petter Mostad 2005.10.24
More on indicator variables • If an independent variable is an indicator variable, cases where it is 1 will just have an addition to the constant term • To use different slopes for these cases, additional variables must be added (products of predictors and indicators) • By viewing the constant term as a data column, we can express the models more symmetrically
Several indicator variables • A model with two indicator variables will assume that the effect of one indicator adds to the effect of the other • If this may be unsuitable, use an additional interaction variable (product of indicators) • For categorical variables with m possible values, use m-1 indicators.
Logistic regression • What if the dependent variable is an indicator variable? • The model then has two stages: First, we predict a value zi from predictors as before, then the probability of indicator value 1 is given by • Given data, we can estimate coefficients in a similar way as before
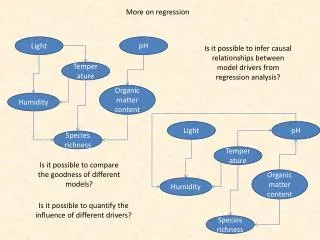
Experimental design • So far, we have considered data as given; to the extent that we can control what data we have, how should we choose to set the independent variables? • Choice of variables • Choice of values for these variables
Choice of variables • Include variables which you believe have a clear influence on the dependent variable, even if the variable is ”uninteresting”: This helps find the true relationship between ”interesting” variables and the dependent. • Avoid including a pair (or a set) of variables whose values are clearly linearily related
Multicollinearity • To discover it, make plots and compute correlations (or make a regression of one parameter on the others) • To deal with it: • Remove unnecessary variables • Define and compute an ”index” • If variables are kept, model could still be used for prediction
Specification bias • Unless two independent variables are uncorrelated, the estimation of one will influence the estimation of the other • Not including one variable which bias the estimation of the other • Thus, one should be humble when interpreting regression results: There are probably always variables one could have added
Choice of values • Should have a good spread: Again, avoid collinearity • Should cover the range for which the model will be used • For categorical variables, one may choose to combine levels in a systematic way.
Generating experimental designs • For n binary variables, there are 2n ways to set them in different combinations. • If 2n is too big, there are systematic ways to choose from these 2n experiments. • If 2n is too small, we can use several experiments at each setting.
Heteroscedasticity – what is it? • In the standard regression model it is assumed that all have the same variance. • If the variance varies with the independent variables or dependent variable, the model is heteroscedastic. • Sometimes, it is clear that data exhibit such properties.
Heteroscedasticity – why does it matter? • Our standard methods for estimation, confidence intervals, and hypothesis testing assume equal variances. • If we go on and use these methods anyway, our answers might be quite wrong!
Heteroscedasticity – how to detect it? • Fit a regression model, and study the residuals • make a plot of them against independent variables • make a plot of them against the predicted values for the dependent variable • Possibility: Test for heteroscedasticity by doing a regression of the squared residuals on the predicted values.
Heteroscedasticity – what to do about it? • Using a transformation of the dependent variable • log-linear models • If the standard deviation of the errors appears to be proportional to the predicted values, a two-stage regression analysis is a possibility
Dependence over time • Sometimes, y1, y2, …, yn are not completely independent observations (given the independent variables). • Lagged values: yi may depend on yi-1 in addition to its independent variables • Autocorrelated errors: Successive observations yi, yi+1,… depend similarily on unobserved variables
Lagged values • In this case, we may run a multiple regression just as before, but including the previous dependent variable yi-1 as a predictor variable for yi.
Autocorrelated errors • In the standard regression model, the errors are independent. • Using standard regression formulas anyway can lead to errors: Typically, the uncertainty in the result is underestimated. • Example: Taking observations closer and closer together in time will not increase your knowledge about regression parameters beyond a certain point
Autocorrelation – how to detect? • Plotting residuals against time! • The Durbin-Watson test compares the possibility of independent errors with a first-order autoregressive model: Option in SPSS Test statistic:
Autocorrelation – what to do? • It is possible to use a two-stage regression procedure: • If a first-order auto-regressive model with parameter is appropriate, the model will have uncorrelated errors • Estimate from the Durbin-Watson statistic, and estimate from the model above