Download

1 / 41
410 likes | 426 Views
Explore the impact of genome technologies and the exponential growth of sequence data, including DNA sequencing, microarrays, mass spectroscopy, yeast two-hybrid, X-ray crystallography, and NMR.

E N D
explosion of biological data Universitat Autònoma octubre2004
genome technologies • DNA sequencing • DNA microarrays • mass spectroscopy and 2-D gels • yeast two hibrids • X-ray cristallography and NMR Universitat Autònoma octubre2004
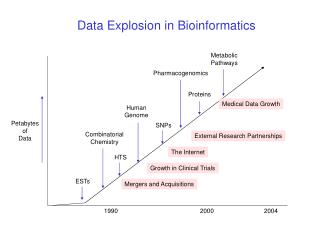
growth of sequence data Universitat Autònoma octubre2004
Moore’s law Universitat Autònoma octubre2004
google hits: X-informatics Universitat Autònoma octubre2004
the genome sequence decodificació del genoma ACTCAGCCCCAGCGGAGGTGAAGGACGTCCTTCCCCAGGAGCCGGTGAGAAGCGCAGTCGGGGGCACGGGGATGAGCTCAGGGGCCTCTAGAAAGATGTAGCTGGGACCTCGGGAAGCCCTGGCCTCCAGGTAGTCTCAGGAGAGCTACTCAGGGTCGGGCTTGGGGAGAGGAGGAGCGGGGGTGAGGCCAGCAGCAGGGGACTGGACCTGGGAAGGGCTGGGCAGCAGAGACGACCCGACCCGCTAGAAGGTGGGGTGGGGAGAGCATGTGGACTAGGAGCTAAGCCACAGCAGGACCCCCACGAGTTGTCACTGTCATTTATCGAGCACCTACTGGGTGTCCCCAGTGTCCTCAGATCTCCATAACTGGGAAGCCAGGGGCAGCGACACGGTAGCTAGCCGTCGATTGGAGAACTTTAAAATGAGGACTGAATTAGCTCATAAATGGAAAACGGCGCTTAAATGTGAGGTTAGAGCTTAGAATGTGAAGGGAGAATGAGGAATGCGAGACTGGGACTGAGATGGAACCGGCGGTGGGGAGGGGGAGGGGGTGTGGAATTTGAACCCCGGGAGAGAAAGATGGAATTTTGGCTATGGAGGCCGACCTGGGGATGGGGAAATAAGAGAAGACCAGGAGGGAGTTAAATAGGGAATGGGTTGGGGGCGGCTTGGTAACTGTTTGTGCTGGGATTAGGCTGTTGCAGATAATGGAGCAAGGCTTGGAAGGCTAACCTGGGGTGGGGCCGGGTTGGGGTCGGGCTGGGGGCGGGAGGAGTCCTCACTGGCGGTTGATTGACAGTTTCTCCTTCCCCAGACTGGCCAATCACAGGCAGGAAGATGAAGGTTCTGTGGGCTGCGTTGCTGGTCACATTCCTGGCAGGTATGGGGCGGGGCTTGCTCGGTTTTCCCCGCTTCTCCCCCTCTCATCCTCACCTCAACCTCCTGGCCCCATTCAAGCACACCCTGGGCCCCCTCTTCTTCTGCTGGTCTGTCCCCTGAGGGGAAAGCCCAGGTCTGAGGCTTCTATGCTGCTTTCTGGCTCAGAACAGCGATTTGACGCTCTGTGAGCCTCGGTTCCTCCCCCGCTTTTTTTTTTTCAGCCAGAGTCTCACTCTGTCGCCCAGGCTGGAGTGCAGTGGCGCAATCTCAGCTCACTGCAAGCTCCGCCTCCCGGGTTCACGCTATTCTCCCGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGCGCCCGCCACCATGCCCGGCTAATTTTTTGTACTTTGAGTAGGGAAGGGGTTTCACTGTATTATCCAGGATGGTCTCTATCTCCTGACCTCGTGATCTGCCCGCCTGGCCTCCCAAAGTGCTGGAATTACAGGCGTGAGCCTCCGCGCCCGGCCTCCCCATCCTTAATATAGGAGTTAGAAGTTTTTGTTTGTTTGTTTTGTTTTGTTTTTGTTTTGTTTTGAGATGAAGTCCCTCTGTCGCCCAGGCTGGAGTGCAGTGGCTCCCAGGCTGGAGTTCAGTGGCTGGATCTCGGCTCACTGCAAGCTCCGCCTCCCAGGTTCACGCCATTCTCCTGCCTCAGCCTCCGGAGTAGCTGGGACTACAGGAACATGCCACCACACCCGACTAACTTTTTTTGTATTTTTAGTAGAGACGGGGTTTCACCATGTTGGCCAGGCTGGTCTGGAACTCCTGACCTCAGGTGATCTGCCTGCTTCAACCTCCCAAAGTGCTGGGATTACAGACGTGGGCCACCGCGCCCGGCTGGGAGTTAAGAGGTTTCTAATGCATTGCATTAGAATACCAGACACGGGACAGCTGTGATCTTTATTCTCCATCACCCCACACAGCCCTGCCTGGGGCACACAAGGACACTCAATACACGCTTTTCGGGCGCGGTGGCTCAAGCTGTAATCCCAGCACTTTGGGAGGCTGAGGCGGGTGGTACATGAGGTCAGGAGATCGAGACCATCCTGGCTAACATGGTGAAACCCCGTCTCTACTAAAAATACAAAAAACTAGCCCGGGCGTGGTGGCGGGCGCCTGTAGTCCCAGCTACTCGGAGGCTGAGGCAGGAGAATGGCGTGAACCTGGGAGGCGGAGCTTGCAGTGAGCCGAGATCGCGCCACTGCACTCCAGCCTGGGTGACACAGCGCGAGACTCCGTCTCAAAAAAAAAAAAAAAAAAAAAAAAAAAAAATACACGCTTTTCCGCTAGGCACGGTGGCTCACCCCTGTAATCCCAGCATTTTGGGAGGCCAAGGTGGGAGGATCACTTGAGCCCAGGAGTTCAACACCAGACTCAGCAACATAGTGAGACTCTCTCTACTAAAAATACAAAAATTAGCCAGGCCTGGTGCCACACACCTGTGGTCCCAGCTACTCAGAAGGCTAAGGCAGGAGGATCGCTTAAGCCCAGAAGGTCAAGGTTGCAGTGAACCACGTTCAGGCCACTGCAGTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTGTAAATAAATAACGCTTTTCAAGTGATTAAACAGACTCCCCCCTCACCCTGCCCACCATGGCTCCAAAGCAGCATTTGTGGAGCACCTTCTGTGTGCCCCTAGGTACTAGCTGCCTGGACGGGGTCAGAAGGAACCTGAACCACCTTCAACTTGTTCCACACAGGATGCCAGGCCAAGGTGGAGCAACCGGTGGAGCCAGAGACAGAACCCGACGTTCGCCAGCAGGCTGAGTGGCAGAGCGGCCAGCCCTGGGAGCTGGCACTGGGTCGCTTTTGGGATTACCTGCGCTGGGTGCAGACACTGTCTGAGCAGGTGCAGGAGGAGCTGCTCAGCCCCCAGGTCACCCAGGAACTGACGTGAGTGTCCCCATCCCGGCCCTTGACCCTCCTGGTGGGCGGCTATACCTCCCCAGGTCCAGGTTTCATTCTGCCCCTGCCACTAAGTCTTGGGGGCCTGGGTCTCTGCTGGTTCTAGCTTCCTCTTCCCATTTCTGACTCCTGGCTTTAGCTCTCTGGAATTCTCTCTCTCAGTTCTGTTTCTCCCTCTTCCCTTCTGACTCAGCCTGTCACACTCGTCCTGGCGCTGTCTCTGTCCTTCACTAGCTCTTTTATATAGAGACAGAGAGATGGGGTCTCACTGTGTTGCCCAGGCTGGTCTTGAACTTCTGGGCTCAAGCGATCCTCCCACCTCGCCTCCCAAAGTGCTGGGAATAGAGACATGAGCCACCTTGCTCGGCCTCCTAGCTCTTTCTTCGTCTCTGCCTCTGCTCTCTGCGTCTGTCTTTGTCTCCTCTCTGCCTCTGTCCCGTTCCTTCTCTCTTGGTTCACTGCCCTTCTGTCTCTCCCTGTTCTCCTTAGGAGACTCTCCTCTCTTCCTTCTCGAGTCTCTCTGGCTGATCCCCATCTCACCCACACCTATCC
the genome sequence ACTCAGCCCCAGCGGAGGTGAAGGACGTCCTTCCCCAGGAGCCGGTGAGAAGCGCAGTCGGGGGCACGGGGATGAGCTCAGGGGCCTCTAGAAAGATGTAGCTGGGACCTCGGGAAGCCCTGGCCTCCAGGTAGTCTCAGGAGAGCTACTCAGGGTCGGGCTTGGGGAGAGGAGGAGCGGGGGTGAGGCCAGCAGCAGGGGACTGGACCTGGGAAGGGCTGGGCAGCAGAGACGACCCGACCCGCTAGAAGGTGGGGTGGGGAGAGCATGTGGACTAGGAGCTAAGCCACAGCAGGACCCCCACGAGTTGTCACTGTCATTTATCGAGCACCTACTGGGTGTCCCCAGTGTCCTCAGATCTCCATAACTGGGAAGCCAGGGGCAGCGACACGGTAGCTAGCCGTCGATTGGAGAACTTTAAAATGAGGACTGAATTAGCTCATAAATGGAAAACGGCGCTTAAATGTGAGGTTAGAGCTTAGAATGTGAAGGGAGAATGAGGAATGCGAGACTGGGACTGAGATGGAACCGGCGGTGGGGAGGGGGAGGGGGTGTGGAATTTGAACCCCGGGAGAGAAAGATGGAATTTTGGCTATGGAGGCCGACCTGGGGATGGGGAAATAAGAGAAGACCAGGAGGGAGTTAAATAGGGAATGGGTTGGGGGCGGCTTGGTAACTGTTTGTGCTGGGATTAGGCTGTTGCAGATAATGGAGCAAGGCTTGGAAGGCTAACCTGGGGTGGGGCCGGGTTGGGGTCGGGCTGGGGGCGGGAGGAGTCCTCACTGGCGGTTGATTGACAGTTTCTCCTTCCCCAGACTGGCCAATCACAGGCAGGAAGATGAAGGTTCTGTGGGCTGCGTTGCTGGTCACATTCCTGGCAGGTATGGGGCGGGGCTTGCTCGGTTTTCCCCGCTTCTCCCCCTCTCATCCTCACCTCAACCTCCTGGCCCCATTCAAGCACACCCTGGGCCCCCTCTTCTTCTGCTGGTCTGTCCCCTGAGGGGAAAGCCCAGGTCTGAGGCTTCTATGCTGCTTTCTGGCTCAGAACAGCGATTTGACGCTCTGTGAGCCTCGGTTCCTCCCCCGCTTTTTTTTTTTCAGCCAGAGTCTCACTCTGTCGCCCAGGCTGGAGTGCAGTGGCGCAATCTCAGCTCACTGCAAGCTCCGCCTCCCGGGTTCACGCTATTCTCCCGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGCGCCCGCCACCATGCCCGGCTAATTTTTTGTACTTTGAGTAGGGAAGGGGTTTCACTGTATTATCCAGGATGGTCTCTATCTCCTGACCTCGTGATCTGCCCGCCTGGCCTCCCAAAGTGCTGGAATTACAGGCGTGAGCCTCCGCGCCCGGCCTCCCCATCCTTAATATAGGAGTTAGAAGTTTTTGTTTGTTTGTTTTGTTTTGTTTTTGTTTTGTTTTGAGATGAAGTCCCTCTGTCGCCCAGGCTGGAGTGCAGTGGCTCCCAGGCTGGAGTTCAGTGGCTGGATCTCGGCTCACTGCAAGCTCCGCCTCCCAGGTTCACGCCATTCTCCTGCCTCAGCCTCCGGAGTAGCTGGGACTACAGGAACATGCCACCACACCCGACTAACTTTTTTTGTATTTTTAGTAGAGACGGGGTTTCACCATGTTGGCCAGGCTGGTCTGGAACTCCTGACCTCAGGTGATCTGCCTGCTTCAACCTCCCAAAGTGCTGGGATTACAGACGTGGGCCACCGCGCCCGGCTGGGAGTTAAGAGGTTTCTAATGCATTGCATTAGAATACCAGACACGGGACAGCTGTGATCTTTATTCTCCATCACCCCACACAGCCCTGCCTGGGGCACACAAGGACACTCAATACACGCTTTTCGGGCGCGGTGGCTCAAGCTGTAATCCCAGCACTTTGGGAGGCTGAGGCGGGTGGTACATGAGGTCAGGAGATCGAGACCATCCTGGCTAACATGGTGAAACCCCGTCTCTACTAAAAATACAAAAAACTAGCCCGGGCGTGGTGGCGGGCGCCTGTAGTCCCAGCTACTCGGAGGCTGAGGCAGGAGAATGGCGTGAACCTGGGAGGCGGAGCTTGCAGTGAGCCGAGATCGCGCCACTGCACTCCAGCCTGGGTGACACAGCGCGAGACTCCGTCTCAAAAAAAAAAAAAAAAAAAAAAAAAAAAAATACACGCTTTTCCGCTAGGCACGGTGGCTCACCCCTGTAATCCCAGCATTTTGGGAGGCCAAGGTGGGAGGATCACTTGAGCCCAGGAGTTCAACACCAGACTCAGCAACATAGTGAGACTCTCTCTACTAAAAATACAAAAATTAGCCAGGCCTGGTGCCACACACCTGTGGTCCCAGCTACTCAGAAGGCTAAGGCAGGAGGATCGCTTAAGCCCAGAAGGTCAAGGTTGCAGTGAACCACGTTCAGGCCACTGCAGTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTGTAAATAAATAACGCTTTTCAAGTGATTAAACAGACTCCCCCCTCACCCTGCCCACCATGGCTCCAAAGCAGCATTTGTGGAGCACCTTCTGTGTGCCCCTAGGTACTAGCTGCCTGGACGGGGTCAGAAGGAACCTGAACCACCTTCAACTTGTTCCACACAGGATGCCAGGCCAAGGTGGAGCAACCGGTGGAGCCAGAGACAGAACCCGACGTTCGCCAGCAGGCTGAGTGGCAGAGCGGCCAGCCCTGGGAGCTGGCACTGGGTCGCTTTTGGGATTACCTGCGCTGGGTGCAGACACTGTCTGAGCAGGTGCAGGAGGAGCTGCTCAGCCCCCAGGTCACCCAGGAACTGACGTGAGTGTCCCCATCCCGGCCCTTGACCCTCCTGGTGGGCGGCTATACCTCCCCAGGTCCAGGTTTCATTCTGCCCCTGCCACTAAGTCTTGGGGGCCTGGGTCTCTGCTGGTTCTAGCTTCCTCTTCCCATTTCTGACTCCTGGCTTTAGCTCTCTGGAATTCTCTCTCTCAGTTCTGTTTCTCCCTCTTCCCTTCTGACTCAGCCTGTCACACTCGTCCTGGCGCTGTCTCTGTCCTTCACTAGCTCTTTTATATAGAGACAGAGAGATGGGGTCTCACTGTGTTGCCCAGGCTGGTCTTGAACTTCTGGGCTCAAGCGATCCTCCCACCTCGCCTCCCAAAGTGCTGGGAATAGAGACATGAGCCACCTTGCTCGGCCTCCTAGCTCTTTCTTCGTCTCTGCCTCTGCTCTCTGCGTCTGTCTTTGTCTCCTCTCTGCCTCTGTCCCGTTCCTTCTCTCTTGGTTCACTGCCCTTCTGTCTCTCCCTGTTCTCCTTAGGAGACTCTCCTCTCTTCCTTCTCGAGTCTCTCTGGCTGATCCCCATCTCACCCACACCTATCC
the genome sequence ACTCAGCCCCAGCGGAGGTGAAGGACGTCCTTCCCCAGGAGCCGGTGAGAAGCGCAGTCGGGGGCACGGGGATGAGCTCAGGGGCCTCTAGAAAGATGTAGCTGGGACCTCGGGAAGCCCTGGCCTCCAGGTAGTCTCAGGAGAGCTACTCAGGGTCGGGCTTGGGGAGAGGAGGAGCGGGGGTGAGGCCAGCAGCAGGGGACTGGACCTGGGAAGGGCTGGGCAGCAGAGACGACCCGACCCGCTAGAAGGTGGGGTGGGGAGAGCATGTGGACTAGGAGCTAAGCCACAGCAGGACCCCCACGAGTTGTCACTGTCATTTATCGAGCACCTACTGGGTGTCCCCAGTGTCCTCAGATCTCCATAACTGGGAAGCCAGGGGCAGCGACACGGTAGCTAGCCGTCGATTGGAGAACTTTAAAATGAGGACTGAATTAGCTCATAAATGGAAAACGGCGCTTAAATGTGAGGTTAGAGCTTAGAATGTGAAGGGAGAATGAGGAATGCGAGACTGGGACTGAGATGGAACCGGCGGTGGGGAGGGGGAGGGGGTGTGGAATTTGAACCCCGGGAGAGAAAGATGGAATTTTGGCTATGGAGGCCGACCTGGGGATGGGGAAATAAGAGAAGACCAGGAGGGAGTTAAATAGGGAATGGGTTGGGGGCGGCTTGGTAACTGTTTGTGCTGGGATTAGGCTGTTGCAGATAATGGAGCAAGGCTTGGAAGGCTAACCTGGGGTGGGGCCGGGTTGGGGTCGGGCTGGGGGCGGGAGGAGTCCTCACTGGCGGTTGATTGACAGTTTCTCCTTCCCCAGACTGGCCAATCACAGGCAGGAAGATGAAGGTTCTGTGGGCTGCGTTGCTGGTCACATTCCTGGCAGGTATGGGGCGGGGCTTGCTCGGTTTTCCCCGCTTCTCCCCCTCTCATCCTCACCTCAACCTCCTGGCCCCATTCAAGCACACCCTGGGCCCCCTCTTCTTCTGCTGGTCTGTCCCCTGAGGGGAAAGCCCAGGTCTGAGGCTTCTATGCTGCTTTCTGGCTCAGAACAGCGATTTGACGCTCTGTGAGCCTCGGTTCCTCCCCCGCTTTTTTTTTTTCAGCCAGAGTCTCACTCTGTCGCCCAGGCTGGAGTGCAGTGGCGCAATCTCAGCTCACTGCAAGCTCCGCCTCCCGGGTTCACGCTATTCTCCCGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGCGCCCGCCACCATGCCCGGCTAATTTTTTGTACTTTGAGTAGGGAAGGGGTTTCACTGTATTATCCAGGATGGTCTCTATCTCCTGACCTCGTGATCTGCCCGCCTGGCCTCCCAAAGTGCTGGAATTACAGGCGTGAGCCTCCGCGCCCGGCCTCCCCATCCTTAATATAGGAGTTAGAAGTTTTTGTTTGTTTGTTTTGTTTTGTTTTTGTTTTGTTTTGAGATGAAGTCCCTCTGTCGCCCAGGCTGGAGTGCAGTGGCTCCCAGGCTGGAGTTCAGTGGCTGGATCTCGGCTCACTGCAAGCTCCGCCTCCCAGGTTCACGCCATTCTCCTGCCTCAGCCTCCGGAGTAGCTGGGACTACAGGAACATGCCACCACACCCGACTAACTTTTTTTGTATTTTTAGTAGAGACGGGGTTTCACCATGTTGGCCAGGCTGGTCTGGAACTCCTGACCTCAGGTGATCTGCCTGCTTCAACCTCCCAAAGTGCTGGGATTACAGACGTGGGCCACCGCGCCCGGCTGGGAGTTAAGAGGTTTCTAATGCATTGCATTAGAATACCAGACACGGGACAGCTGTGATCTTTATTCTCCATCACCCCACACAGCCCTGCCTGGGGCACACAAGGACACTCAATACACGCTTTTCGGGCGCGGTGGCTCAAGCTGTAATCCCAGCACTTTGGGAGGCTGAGGCGGGTGGTACATGAGGTCAGGAGATCGAGACCATCCTGGCTAACATGGTGAAACCCCGTCTCTACTAAAAATACAAAAAACTAGCCCGGGCGTGGTGGCGGGCGCCTGTAGTCCCAGCTACTCGGAGGCTGAGGCAGGAGAATGGCGTGAACCTGGGAGGCGGAGCTTGCAGTGAGCCGAGATCGCGCCACTGCACTCCAGCCTGGGTGACACAGCGCGAGACTCCGTCTCAAAAAAAAAAAAAAAAAAAAAAAAAAAAAATACACGCTTTTCCGCTAGGCACGGTGGCTCACCCCTGTAATCCCAGCATTTTGGGAGGCCAAGGTGGGAGGATCACTTGAGCCCAGGAGTTCAACACCAGACTCAGCAACATAGTGAGACTCTCTCTACTAAAAATACAAAAATTAGCCAGGCCTGGTGCCACACACCTGTGGTCCCAGCTACTCAGAAGGCTAAGGCAGGAGGATCGCTTAAGCCCAGAAGGTCAAGGTTGCAGTGAACCACGTTCAGGCCACTGCAGTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTGTAAATAAATAACGCTTTTCAAGTGATTAAACAGACTCCCCCCTCACCCTGCCCACCATGGCTCCAAAGCAGCATTTGTGGAGCACCTTCTGTGTGCCCCTAGGTACTAGCTGCCTGGACGGGGTCAGAAGGAACCTGAACCACCTTCAACTTGTTCCACACAGGATGCCAGGCCAAGGTGGAGCAACCGGTGGAGCCAGAGACAGAACCCGACGTTCGCCAGCAGGCTGAGTGGCAGAGCGGCCAGCCCTGGGAGCTGGCACTGGGTCGCTTTTGGGATTACCTGCGCTGGGTGCAGACACTGTCTGAGCAGGTGCAGGAGGAGCTGCTCAGCCCCCAGGTCACCCAGGAACTGACGTGAGTGTCCCCATCCCGGCCCTTGACCCTCCTGGTGGGCGGCTATACCTCCCCAGGTCCAGGTTTCATTCTGCCCCTGCCACTAAGTCTTGGGGGCCTGGGTCTCTGCTGGTTCTAGCTTCCTCTTCCCATTTCTGACTCCTGGCTTTAGCTCTCTGGAATTCTCTCTCTCAGTTCTGTTTCTCCCTCTTCCCTTCTGACTCAGCCTGTCACACTCGTCCTGGCGCTGTCTCTGTCCTTCACTAGCTCTTTTATATAGAGACAGAGAGATGGGGTCTCACTGTGTTGCCCAGGCTGGTCTTGAACTTCTGGGCTCAAGCGATCCTCCCACCTCGCCTCCCAAAGTGCTGGGAATAGAGACATGAGCCACCTTGCTCGGCCTCCTAGCTCTTTCTTCGTCTCTGCCTCTGCTCTCTGCGTCTGTCTTTGTCTCCTCTCTGCCTCTGTCCCGTTCCTTCTCTCTTGGTTCACTGCCCTTCTGTCTCTCCCTGTTCTCCTTAGGAGACTCTCCTCTCTTCCTTCTCGAGTCTCTCTGGCTGATCCCCATCTCACCCACACCTATCC Universitat Autònoma octubre2004
gagttttatcgcttccatgacgcagaagttaacactttcggatatttctgatgagtcgaaaaattatcttgataaagcaggaattactactgcttgtttacgaattaaatcgaagtggactgctggcggaaaatgagaaaattcgacctatccttgcgcagctcgagaagctcttactttgcgacctttcgccatcaactaacgattctgtcaaaaactgacgcgttggatgaggagaagtggcttaatatgcttggcacgttcgtcaaggactggtttagatatgagtcacattttgttcatggtagagattctcttgtgagttttatcgcttccatgacgcagaagttaacactttcggatatttctgatgagtcgaaaaattatcttgataaagcaggaattactactgcttgtttacgaattaaatcgaagtggactgctggcggaaaatgagaaaattcgacctatccttgcgcagctcgagaagctcttactttgcgacctttcgccatcaactaacgattctgtcaaaaactgacgcgttggatgaggagaagtggcttaatatgcttggcacgttcgtcaaggactggtttagatatgagtcacattttgttcatggtagagattctcttgt MALWTRLRPLLALLALWPPPPARAFVNQHLCGSHLVEALYLVCGERGFFYTPKARREVEGPQVGALELAGGPGAGGLEGPPQKRGIVEQCCASVCSLYQLENYCN
probabilistic patterns ingene predictionroderic guigó serrarobert castelo (IMIM-UPF-CRG) Universitat Autònoma octubre2004
the genome sequence decodificació del genoma ACTCAGCCCCAGCGGAGGTGAAGGACGTCCTTCCCCAGGAGCCGGTGAGAAGCGCAGTCGGGGGCACGGGGATGAGCTCAGGGGCCTCTAGAAAGATGTAGCTGGGACCTCGGGAAGCCCTGGCCTCCAGGTAGTCTCAGGAGAGCTACTCAGGGTCGGGCTTGGGGAGAGGAGGAGCGGGGGTGAGGCCAGCAGCAGGGGACTGGACCTGGGAAGGGCTGGGCAGCAGAGACGACCCGACCCGCTAGAAGGTGGGGTGGGGAGAGCATGTGGACTAGGAGCTAAGCCACAGCAGGACCCCCACGAGTTGTCACTGTCATTTATCGAGCACCTACTGGGTGTCCCCAGTGTCCTCAGATCTCCATAACTGGGAAGCCAGGGGCAGCGACACGGTAGCTAGCCGTCGATTGGAGAACTTTAAAATGAGGACTGAATTAGCTCATAAATGGAAAACGGCGCTTAAATGTGAGGTTAGAGCTTAGAATGTGAAGGGAGAATGAGGAATGCGAGACTGGGACTGAGATGGAACCGGCGGTGGGGAGGGGGAGGGGGTGTGGAATTTGAACCCCGGGAGAGAAAGATGGAATTTTGGCTATGGAGGCCGACCTGGGGATGGGGAAATAAGAGAAGACCAGGAGGGAGTTAAATAGGGAATGGGTTGGGGGCGGCTTGGTAACTGTTTGTGCTGGGATTAGGCTGTTGCAGATAATGGAGCAAGGCTTGGAAGGCTAACCTGGGGTGGGGCCGGGTTGGGGTCGGGCTGGGGGCGGGAGGAGTCCTCACTGGCGGTTGATTGACAGTTTCTCCTTCCCCAGACTGGCCAATCACAGGCAGGAAGATGAAGGTTCTGTGGGCTGCGTTGCTGGTCACATTCCTGGCAGGTATGGGGCGGGGCTTGCTCGGTTTTCCCCGCTTCTCCCCCTCTCATCCTCACCTCAACCTCCTGGCCCCATTCAAGCACACCCTGGGCCCCCTCTTCTTCTGCTGGTCTGTCCCCTGAGGGGAAAGCCCAGGTCTGAGGCTTCTATGCTGCTTTCTGGCTCAGAACAGCGATTTGACGCTCTGTGAGCCTCGGTTCCTCCCCCGCTTTTTTTTTTTCAGCCAGAGTCTCACTCTGTCGCCCAGGCTGGAGTGCAGTGGCGCAATCTCAGCTCACTGCAAGCTCCGCCTCCCGGGTTCACGCTATTCTCCCGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGCGCCCGCCACCATGCCCGGCTAATTTTTTGTACTTTGAGTAGGGAAGGGGTTTCACTGTATTATCCAGGATGGTCTCTATCTCCTGACCTCGTGATCTGCCCGCCTGGCCTCCCAAAGTGCTGGAATTACAGGCGTGAGCCTCCGCGCCCGGCCTCCCCATCCTTAATATAGGAGTTAGAAGTTTTTGTTTGTTTGTTTTGTTTTGTTTTTGTTTTGTTTTGAGATGAAGTCCCTCTGTCGCCCAGGCTGGAGTGCAGTGGCTCCCAGGCTGGAGTTCAGTGGCTGGATCTCGGCTCACTGCAAGCTCCGCCTCCCAGGTTCACGCCATTCTCCTGCCTCAGCCTCCGGAGTAGCTGGGACTACAGGAACATGCCACCACACCCGACTAACTTTTTTTGTATTTTTAGTAGAGACGGGGTTTCACCATGTTGGCCAGGCTGGTCTGGAACTCCTGACCTCAGGTGATCTGCCTGCTTCAACCTCCCAAAGTGCTGGGATTACAGACGTGGGCCACCGCGCCCGGCTGGGAGTTAAGAGGTTTCTAATGCATTGCATTAGAATACCAGACACGGGACAGCTGTGATCTTTATTCTCCATCACCCCACACAGCCCTGCCTGGGGCACACAAGGACACTCAATACACGCTTTTCGGGCGCGGTGGCTCAAGCTGTAATCCCAGCACTTTGGGAGGCTGAGGCGGGTGGTACATGAGGTCAGGAGATCGAGACCATCCTGGCTAACATGGTGAAACCCCGTCTCTACTAAAAATACAAAAAACTAGCCCGGGCGTGGTGGCGGGCGCCTGTAGTCCCAGCTACTCGGAGGCTGAGGCAGGAGAATGGCGTGAACCTGGGAGGCGGAGCTTGCAGTGAGCCGAGATCGCGCCACTGCACTCCAGCCTGGGTGACACAGCGCGAGACTCCGTCTCAAAAAAAAAAAAAAAAAAAAAAAAAAAAAATACACGCTTTTCCGCTAGGCACGGTGGCTCACCCCTGTAATCCCAGCATTTTGGGAGGCCAAGGTGGGAGGATCACTTGAGCCCAGGAGTTCAACACCAGACTCAGCAACATAGTGAGACTCTCTCTACTAAAAATACAAAAATTAGCCAGGCCTGGTGCCACACACCTGTGGTCCCAGCTACTCAGAAGGCTAAGGCAGGAGGATCGCTTAAGCCCAGAAGGTCAAGGTTGCAGTGAACCACGTTCAGGCCACTGCAGTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTGTAAATAAATAACGCTTTTCAAGTGATTAAACAGACTCCCCCCTCACCCTGCCCACCATGGCTCCAAAGCAGCATTTGTGGAGCACCTTCTGTGTGCCCCTAGGTACTAGCTGCCTGGACGGGGTCAGAAGGAACCTGAACCACCTTCAACTTGTTCCACACAGGATGCCAGGCCAAGGTGGAGCAACCGGTGGAGCCAGAGACAGAACCCGACGTTCGCCAGCAGGCTGAGTGGCAGAGCGGCCAGCCCTGGGAGCTGGCACTGGGTCGCTTTTGGGATTACCTGCGCTGGGTGCAGACACTGTCTGAGCAGGTGCAGGAGGAGCTGCTCAGCCCCCAGGTCACCCAGGAACTGACGTGAGTGTCCCCATCCCGGCCCTTGACCCTCCTGGTGGGCGGCTATACCTCCCCAGGTCCAGGTTTCATTCTGCCCCTGCCACTAAGTCTTGGGGGCCTGGGTCTCTGCTGGTTCTAGCTTCCTCTTCCCATTTCTGACTCCTGGCTTTAGCTCTCTGGAATTCTCTCTCTCAGTTCTGTTTCTCCCTCTTCCCTTCTGACTCAGCCTGTCACACTCGTCCTGGCGCTGTCTCTGTCCTTCACTAGCTCTTTTATATAGAGACAGAGAGATGGGGTCTCACTGTGTTGCCCAGGCTGGTCTTGAACTTCTGGGCTCAAGCGATCCTCCCACCTCGCCTCCCAAAGTGCTGGGAATAGAGACATGAGCCACCTTGCTCGGCCTCCTAGCTCTTTCTTCGTCTCTGCCTCTGCTCTCTGCGTCTGTCTTTGTCTCCTCTCTGCCTCTGTCCCGTTCCTTCTCTCTTGGTTCACTGCCCTTCTGTCTCTCCCTGTTCTCCTTAGGAGACTCTCCTCTCTTCCTTCTCGAGTCTCTCTGGCTGATCCCCATCTCACCCACACCTATCC
the amino acid sequence of the proteins QIKDLLVSSSTDLDTTLVLVNAIYFKGMWKTAFNAEDTREMPFHVTKQESKPVQMMCMNNSFNVATLPAEKMKILELPFASGDLSMLVLLPDEVSDLERIEKTINFEKLTEWTNPNTMEKRRVKVYLPQMKIEEKYNLTSVLMALGMTDLFIPSANLTGISSAESLKISQAVHGAFMELSEDGIEMAGSTGVIEDIKHSPESEQFRADHPFLFLIKHNPTNTIVYFGRYWS
eukaryotic gene structure Universitat Autònoma octubre2004
Universitat Autònoma octubre2004
INTRONS PROMOTOR EXONS DOWNSTREAM REGULATOR UPSTREAM REGULATOR eukaryotic gene structure donor acceptor Universitat Autònoma octubre2004
modeling donor sites GGG GTGAGCCCAG GTG GTAAGAGACA TAG GTGAGTGTGA GCG GTAGGTACTC CAG GTAATTTTCT AAG GTAGGCTCTG AGG GTGAGTCCAG GAG GTGGGTCACA CAG GTCAGTCTTT ACG GTAAGACCTG CAG GTGGGTGCTG CAG GTAAGCAGTG AGG GTGAGTTCAG CAG GTAAGCATTG AGG GTGAGTTCAG Universitat Autònoma octubre2004
the donor site pattern reflects underlying biological constraints Universitat Autònoma octubre2004
the donor site pattern reflects underlying biological constraints Universitat Autònoma octubre2004
searching the pattern the donor site pattern
prediction of splice sites Universitat Autònoma octubre2004
modeling dependencies Universitat Autònoma octubre2004
modeling dependencies, first order markov models Weigth Array Models (WAM) Zhang and Marr (1993) Universitat Autònoma octubre2004
Universitat Autònoma octubre2004
extending the Markov order • Salzberg et al., (1998) Interpolated Markov Models • Cawley (2000) Variable length Markov Models Universitat Autònoma octubre2004
modeling non-local dependencies in splice sites • Burge and Karlin, 1997. Maximal Dependence Decomposition (MDD) • Agarwal and Bafna, 1998 • Yeo and Burge, 2003 • Zhao et al., 2004. Permutated Variable Length Markov Models (PVMLL) • Cai et al., 2000; Dash and Gopalakrishman, 2001. Bayesian Networks • Castelo and Guigó, 2004, Inclusion-Driven Learned Bayesian Networks (idlBNS) Universitat Autònoma octubre2004
idlBNs • Bayesian Networks: allow one to learn from the data those (in)dependencies that conform an acyclic digraph (DAG). • Inclusion-driven structure learning algorithms (Castelo and Kocka, 2003): under the assumption that the data is sampled from a DAG-distribution, and in the limit of the size of the sample they learn a correct DAG structure using a consistent scoring metric. Universitat Autònoma octubre2004
Universitat Autònoma octubre2004
prediction of splice sites vs. gene prediction Universitat Autònoma octubre2004
d4 d2 d1 d3 a1 a2 e1 a3 e2 a4 e3 a5 e4 e5 e6 e7 e4 e8 sites exons genes e8 e1 the gene prediction problem
gene prediction accuracy SN : fraction of true exons predicted correctly SP : fraction of predicted exons that are correct Universitat Autònoma octubre2004
(codon usage table) Universitat Autònoma octubre2004
coding statistics Universitat Autònoma octubre2004
the real accuracy Accuracy on human chromosome 22 Universitat Autònoma octubre2004
search for additional patterns • real exons with weak splice sites, Fairbrother et al., 2002 • “pseudoexons” with strong splice sites, Zhang and Chasin, 2004 Universitat Autònoma octubre2004
Fairbrother et al., 2002. splicing enhancers in exons with weak sites Universitat Autònoma octubre2004
Zhang and Chasin, 2004. splicing silencers in pseudoexons with strong sites Universitat Autònoma octubre2004
125.000 human 5’splice sites Consensus sequence bottom 1% top 1% random 1% GGGCTGGGG 310 69 217 GA A CCCTCCCCC 147 51 107 AG TT Weight matrix T TTTTCTTTT 192 16 90 A AAAAA T Selection of the 1% lower score 5’ splice sites Identification of downstream sequences over-represented in the lower 1% pool. dowsntream sequences are conserved in orthologous mouse exons with weak sites in collaboration with Juan Valcárcel, CRG
(1) (2) (3) GGGGAGGGG CT RNA/U1snRNA EXON GTAGACCTGGGGTGGGG………. EXON GTAGACCTGCTGTTTTGC………. RNA EXON GTAAGTCTGCTGTTTTGC………. Nuclear Extracts (NE) U1 KO NE INHIBITORY EFFECT OF ON 5’SS RECOGNITION BY U1 snRNP U1 Weak 5’ss followed by a G-rich element (1) Deletion of the G-rich element in (1) (2) Strong 5’ ss (3) Universitat Autònoma octubre2004
CAUUCAUApppGm3 5’ GUAAUU UUUUUUUUU +5 TIA-1 promotes U1 snRNP binding to weak 5’ splice sites Followed by uridine-rich sequences XXXXXXXXX TIA-1 Universitat Autònoma octubre2004
the second genetic code • genetic code • mapping of nucleotide triplets into 3’ into the twenty aminoacids • highly deterministic: a given triplet always codes for the same amino acid • splicing code • mapping of nucleotide sequences into 3’ and 5’ intron boundaries. • inherently stochastic: the probability of an splicing sequence to participate in the definition of an inron boundary ranges from zero to one, and it is conditionated to very many different factors (which could be other sequences) Universitat Autònoma octubre2004