Download
1 / 27
480 likes | 1.14k Views
Eukaryotic Gene Finding. Adapted in part from http://online.itp.ucsb.edu/online/infobio01/burge/. Prokaryotes small genomes high gene density no introns (or splicing) no RNA processing similar promoters overlapping genes. Eukaryotes large genomes low gene density introns (splicing)

E N D
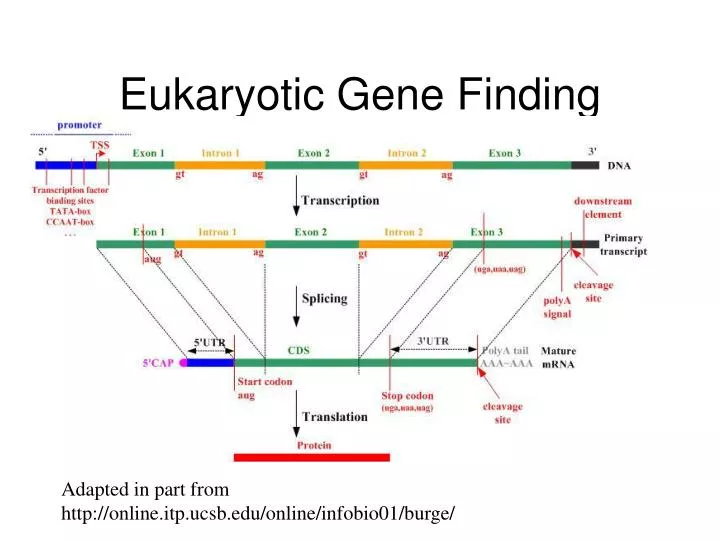
Eukaryotic Gene Finding Adapted in part from http://online.itp.ucsb.edu/online/infobio01/burge/
Prokaryotes small genomes high gene density no introns (or splicing) no RNA processing similar promoters overlapping genes Eukaryotes large genomes low gene density introns (splicing) RNA processing heterogeneous promoters polyadenylation Prokaryotic vs. Eukaryotic Genes
P P P N N N R 5 R R 5 n 6 n n s 3 F s s F A 2 1 A 1 2 U U U 2 U U SR proteins branch signal ’ ’ ’ 5 splice signal 5 splice signal 3 splice signal polyY exonic repressor exonic enhancers intronic enhancers intronic repressor Pre-mRNA Splicing exon definition intron definition ... (assembly of spliceosome, catalysis) ...
Some Statistics • On average, a vertebrate gene is about 30KB long • Coding region takes about 1KB • Exon sizes can vary from double digit numbers to kilobases • An average 5’ UTR is about 750 bp • An average 3’UTR is about 450 bp but both can be much longer.
Human Splice Signal Motifs 5' splice signal 3' splice signal
N - intergenic region P - promoter F - 5’ untranslated region Esngl – single exon (intronless) (translation start -> stop codon) Einit – initial exon (translation start -> donor splice site) Ek – phase k internal exon (acceptor splice site -> donor splice site) Eterm – terminal exon (acceptor splice site -> stop codon) Ik – phase k intron: 0 – between codons; 1 – after the first base of a codon; 2 – after the second base of a codon GenScan States
GenScan features • Model both strands at once • Each state may output a string of symbols (according to some probability distribution). • Explicit intron/exon length modeling • Advanced splice site modeling • Parameters learned from annotated genes • Separate parameter training for different CpG content groups
GenScan Signal Modeling • PSSM: P(S) = P1(S1)•P2(S2) •…•Pn(Sn) • PolyA signal • Translation initiation/termination signal • Promoters • WAM: P(S) = P1(S1) •P2(S2|S1)•…•Pn(Sn|Sn-1) • 5’ and 3’ splice sites
HMM-based Gene Finding • GENSCAN (Burge 1997) • FGENESH (Solovyev 1997) • HMMgene (Krogh 1997) • GENIE (Kulp 1996) • GENMARK (Borodovsky & McIninch 1993) • VEIL (Henderson, Salzberg, & Fasman 1997)
GenomeScan • Idea: We can enhance our gene prediction by using external information: DNA regions with homology to known proteins are more likely to be coding exons. • Combine probabilistic ‘extrinsic’ information (BLAST hits) with a probabilistic model of gene structure/composition (GenScan) • Focus on ‘typical case’ when homologous but not identical • proteins are available.
GeneWise [Birney, Amitai] • Motivation: Use good DB of protein world (PFAM) to help us annotate genomic DNA • GeneWise algorithm aligns a profile HMM directly to the DNA
Developing GeneWise Model • Start with a PFAM domain HMM • Replace AA emissions with codon emissions • Allow for sequencing errors (deletions/insertions) • Add a 3-state intron model
central PY tract spacer GeneWise Intron Model 5’ site 3’ site
GeneWise Model • Viterbi algorithm -> “best” alignment of DNA to protein domain • Alignment gives exact exon-intron boundaries • Parameters learned from species-specific statistics
GeneWise problems • Only provides partial prediction, and only where the homology lies • Does not find “more” genes • Pseudogenes, Retrotransposons picked up • CPU intensive • Solution: Pre-filter with BLAST
Summary • Genes are complex structures which are difficult to predict with the required level of accuracy/confidence • Different approaches to gene finding: • Ab Initio : GenScan • Ab Initio modified by BLAST homologies: GenomeScan • Homology guided: GeneWise






















