Download
1 / 13
130 likes | 262 Views
POP 1.4.3 Performance - 1 Degree Global Problem.

E N D
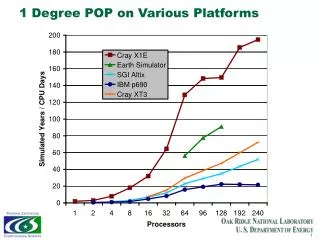
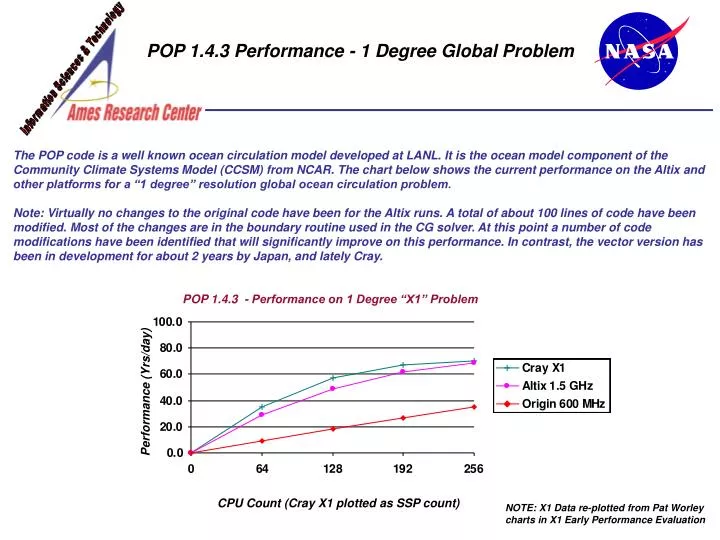
POP 1.4.3 Performance - 1 Degree Global Problem The POP code is a well known ocean circulation model developed at LANL. It is the ocean model component of the Community Climate Systems Model (CCSM) from NCAR. The chart below shows the current performance on the Altix and other platforms for a “1 degree” resolution global ocean circulation problem. Note: Virtually no changes to the original code have been for the Altix runs. A total of about 100 lines of code have been modified. Most of the changes are in the boundary routine used in the CG solver. At this point a number of code modifications have been identified that will significantly improve on this performance. In contrast, the vector version has been in development for about 2 years by Japan, and lately Cray. POP 1.4.3 - Performance on 1 Degree “X1” Problem Performance (Yrs/day) CPU Count (Cray X1 plotted as SSP count) NOTE: X1 Data re-plotted from Pat Worley charts in X1 Early Performance Evaluation
POP 1.4.3 - Performance on 0.1 Degree “NA” Problem Performance (Yrs/day) CPU Count POP 1.4.3 - 0.1 Degree North Atlantic Problem The second POP scenario was a run of the 0.1 degree North Atlantic simulation as defined by LANL last year. The grid for this problem is 992x1280x40 (~51M points). As stated before no significant code changes were made. The results are presented below. Note that this simulation contains about 10x more points than the 1 degree problem above and requires about 6x more time steps per day. Thus, the “work” is about 60x more, yet yet the run performance is only about 17x slower on 256 CPUs. The turnover in both 1.0 and 0.1 degree problems is due to two effects, 1) Scaling in the barotropic computation, and 2) Extra useless work engendered by the extensive use of F90 array syntax notation in the code. NOTE: POP graphics courtesy of Bob Malone LANL
CCSM 2.0 Code Performance - 1000 year simulation CCSM was used last year by NCAR to conduct a 1000 year global simulation using T42 resolution for the atmosphere and 1 degree resolution for the ocean. The simulation required 200 days of compute time to complete. The Altix code at this point has been partially optimized using MLP for all inter model communications. Some sub-models have been optimized further. About 4 man-months have been devoted to the project. MLP Altix 1.5GHz 53 days (192 CPUs) 73 days (256 CPUS) MLP O3K 0.6 GHz 200 days MPI IBM Pw3 318 days MPI SGI O3k 0 days 200 days 400 days Compute time for 1000 year simulation
Performance Results for • Applications in the Aerosciences • ARC3D • OVERFLOW • CART3D
OVERFLOW-MLP - 35M Point “Airplane” Problem The OVERFLOW “Airplane” problem has become a benchmarking standard at NAS. It has been one of the primary benchmarks used in evaluating the scaling performance of candidate HPC platforms for the past 6 years. This is very appropriate as more than 50% of all cycles burned at NAS are from OVERFLOW runs and/or codes with very similar performance characteristics. The “Airplane” problem is a high fidelity steady state computation of a full aircraft configured for landing. The problem consists of 160 3-D blocks varying in size from 1.6M points to 11K points. The total point count is 35M. Load balance is very critical for this problem. SSI architectures are particularly well suited for load balancing. The chart below shows the size distribution of the 160 blocks in this problem. Percentage of Total Point Count by Block Percentage of Total Pts Block Number
OVERFLOW-MLP Performance The following chart displays the performance of OVERFLOW-MLP for Altix and Origin systems. OVERFLOW-MLP is a hybrid multi-level parallel code using OpenMP for loop level parallelism and MLP (a faster alternative to MPI) for the coarse grained parallelism. NOTE: This code is 99% VECTOR per Cray. The performance below translates into a problem run time of 0.9 seconds per step on the 256p Altix. 35 Million Point “Airplane” Problem - GFLOP/s versus CPU Count CPU count
The ARC3D Code - OpenMP Test The chart below presents the results of executions of the ARC3D code on O3K and Altix systems for differing CPU counts. ARC3D was a production CFD code at NAS for many years. It is a pure OpenMP parallel code. Its solution techniques for a single grid block are very similar to numerous production CFD codes in use today at NAS (OVERFLOW, CFL3D, TLNS3D, INS3D). It is an excellent test for revealing how a new system will perform at the single CFD block level. It’s response is applicable to earth science ocean and climate models as well. The test below is for a 194x194x194 dimensioned grid. It shows excellent performance on the Altix relative to the O3K for 1-64 CPUs with almost a 3x win at all CPU counts. ARC3D Performance Relative to O3K 600 MHz Speedup Relative to O3K
The CART3D Code - OpenMP Test The CART3D code was the NASA “Software of the Year” winner for 2003. It is routinely used for a number of CFD problems within the agency. It’s most recent application was to assist in the foam impact analysis done for the STS107 accident investigation. The chart to the right presents the results of executing the OpenMP based CART3D production CFD code on various problems across differing CPU counts on the NAS Altix and O3K systems. As can be seen, the scaling to 500 CPUs on the weeks old Altix 512 CPU system is excellent.
NASA HSP Compute Server Suite
NAS HSP3 Compute Server Suite Performance The charts below present the relative performance (O3K600=1) across 4 platforms for the NAS HSP3 Compute Server Suite. This selection of codes was used historically as a benchmark suite for the HSP3 procurement (C90) at NAS. HSP3 Compute Server Suite Performance Relative Performance Code Relative Performance Code Code
The NAS Parallel Benchmarks (NPBs) V2.1 The chart below presents the results of several executions of the NAS Parallel Benchmarks (NPBs 2.1) on Origin 3000 and Altix 1.3/1.5 GHz Systems. The NPBs are a collection of codes and code segments used throughout industry to comparatively rate the performance of alternative HPC systems. NPB Performance Relative to O3K 600 MHz Ratio to O3K
Summary and Observations • The NASA - SGI 512p Altix SSI effort is already highly successful. A few items remain, but the system is very useable and stable • The Altix system routinely provides 3-5x the performance over current NAS systems Smaller jobs (1-64 CPUs) tend to larger percent wins • The 512 system is well along its way to a solid production system for NASA needs. Running >50% workload 24/7 Batch system up and running - jobs managed by PBS Pro System uptime already measured in weeks
So what got accelerated by NASA Ames? Production CFD Codes executing 100x C90 numbers of just a few years ago Earth Science codes executing 2-4x faster than last year’s best efforts, 50x over a few years ago. New expanded shared memory architectures: First 256,512, and 1024 CPU Origin systems. First 256,512 quasi-production Altix systems Where is the future at NAS? Expanded Altix to 4096?