Download

1 / 31

E N D
TIPI DATI In matematica è usuale classificare le variabili rispetto ad alcune loro caratteristiche importanti: si fanno chiare distinzioni tra variabili reali, complesse e logiche, oppure tra variabili che rappresentano valori individuali, insiemi di valori, o insiemi di insiemi, oppure tra funzioni, funzionali, insiemi di funzioni, e così via. Questa classificazione è ugualmente importante, se non di più, nella elaborazione dei dati, dove vale il principio che: tutte le costanti, le variabili, le espressioni e le funzioni appartengono a un certo tipo. Tale tipo caratterizza l’insieme di valori che può assumere una costante o una variabile, o che possono essere prodotti da una funzione. Nei testi di matematica il tipo di una variabile può di solito essere dedotto dai caratteri tipografici, indipendentemente dal contesto. Ciò non è possibile con i programmi, che di solito sono scritti con un solo repertorio di caratteri.
Perciò la regola, quasi ovunque accettata, stabilisce che il tipo associato sia reso esplicito con una dichiarazione della costante, della variabile o della funzione. Tale dichiarazione deve precedere l’utilizzo della costante, della variabile o della funzione. Questa regola appare particolarmente sensata se si considera che un compilatore deve fare una scelta di rappresentazione dell’oggetto, nella memoria dell’elaboratore. Evidentemente, la quantità di memoria che il compilatore riserva (alloca) a una variabile deve essere scelta considerando la dimensione dell’intervallo di valori che essa potrà assumere. Quando tale informazione sia nota al compilatore, esso riserva la quantità di memoria effettivamente necessaria a rappresentare la variabile (allocazione statica)
Se invece la quantità di memoria da riservare per un tipo dati non è nota (come succede con i file, che vedremo), il compilatore deve effettuare una allocazione dinamica, ossia riservare memoria via via che i valori si “espandono” e recuperarla quando essi si “restringono”. Le caratteristiche principali del concetto di tipo, che è incorporato nel linguaggio C, sono dunque le seguenti: • un tipo dati determina l’insieme dei valori al quale appartiene una costante, o i valori che una variabile o un’espressione possono assumere, o che una funzione o un operatore possono produrre; • il tipo del valore rappresentato da una costante, una variabile o un’espressione può derivare dalla sua forma o dalla sua dichiarazione, senza necessità di eseguire il processo di computazione; • ogni operatore e ogni funzione accettano argomenti di un tipo fissato, e producono risultati di un tipo fissato; se un operatore ammette argomenti di tipi diversi (ad es., + viene utilizzato per sommare sia numeri interi, sia numeri reali), allora il tipo del risultato può essere determinato mediante regole specifiche del linguaggio.
Di conseguenza, un compilatore può usare le informazioni di tipo per controllare la compatibilità e la legalità dei vari costrutti. Ad es., l’assegnamento di un valore booleano (logico) a una variabile aritmetica (reale), può essere rilevato senza eseguire il programma. Questo tipo di ridondanza nel testo del programma è estremamente utile per agevolare lo sviluppo degli algoritmi, e costituisce uno dei vantaggi principali dei buoni linguaggi ad alto livello, rispetto al codice macchina o al codice assemblativo simbolico. Evidentemente, alla fine tutti i dati verranno rappresentati nella memoria del computer sotto forma di cifre binarie, indipendentemente dal fatto che il programma sia stato inizialmente concepito in un linguaggio ad alto livello, dotato di tipi, oppure in codice assemblativo senza tipi. Dal punto di vista del computer, la memoria è un ammasso di bit, senza una struttura apparente. Ma è proprio la struttura astratta che, da sola, permette ai programmatori di dare un significato al monotono panorama di una memoria di computer.
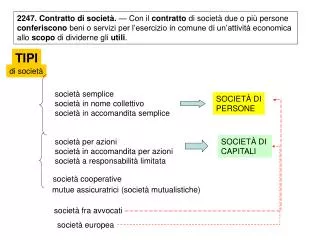
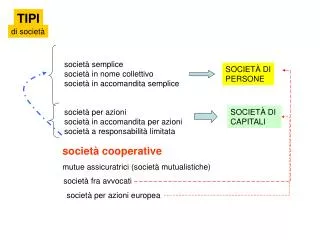
Il linguaggio C fornisce alcuni • tipi dati predefiniti, che contengono numeri e caratteri, e possono essere semplici o strutturati. • Inoltre consente di creare • tipi dati definiti dall’utente. • Se esiste un ordine tra i valori individuali, allora si dice che il tipo è ordinato. In C si assume che tutti i tipi non strutturati siano ordinati. • Tipi dati semplici • In C vi sono 4 tipi dati semplici: • integer (intero) • floating point (virgola mobile) • double precision (doppia precisione) • character (carattere)
Valori integer. Un valore intero, detto anche costante intera, è un numero positivo o negativo senza la virgola decimale. Esempi: 5 -10 +36 Come si vede, gli interi possono essere con segno (con un + o un - iniziale) o senza segno (senza + o - iniziale). I compilatori presentano limitazioni sui valori interi massimo (positivo) e minimo (negativo) che si possono usare in un programma. Queste limitazioni dipendono dalla implementazione, ossia dalla quantità di memoria che il compilatore mette a disposizione per un intero. Le allocazioni di memoria più comuni sono indicate in tabella.
L’operatore sizeof, che vedremo più avanti, consente di determinare la quantità di memoria riservata dal computer in uso per ciascun tipo dati.
Numeri floating point e double precision. I numeri in virgola mobile e in doppia precisione sono i numeri con o senza segno con il punto decimale. Esempi: +10.625 5. -6.2 3251.92 0.0 0.33 +2 La differenza tra i numeri in virgola mobile e in doppia precisione sta nella quantità di memoria riservata per ciascun tipo: molti computer riservano una quantità di memoria doppia per i numeri in doppia precisione rispetto a quella per i numeri in virgola mobile. In tale caso un numero in doppia precisione ha approssimativamente una precisione doppia rispetto a un numero in virgola mobile (che per questa ragione è detto anche numero in precisione singola). L’effettiva allocazione di memoria per ciascun tipo dati dipende tuttavia dal particolare computer, e in quelli che usano la stessa quantità di memoria per i numeri in doppia precisione e in virgola mobile i due tipi dati diventano identici.
Notazione esponenziale. I numeri in virgola mobile e in doppia precisione si possono scrivere in notazione esponenziale, che viene usata di solito per esprimere in forma compatta numeri molto grandi o molto piccoli. I seguenti esempi illustrano come si possono esprimere in notazione esponenziale numeri con il punto decimale.
Tipo character. Il quarto tipo dati fondamentale riconosciuto in C è il tipo carattere. I caratteri sono le lettere dell’alfabeto (minuscole e maiuscole), le dieci cifre da 0 a 9 e simboli speciali quali: + $ . , - ! Una costante a carattere singolo è qualsiasi lettera, cifra o simbolo speciale racchiuso tra apici singoli. Esempi: ‘A’ ‘$’ ‘b’ ‘7’ Le costanti carattere sono memorizzate in un computer usando tipicamente i codici ASCII o EBCDIC, e riservando 1 byte di memoria per ciascun carattere. Ad es., la parola Bytes sarebbe memorizzata come indica la figura.
Tipi dati strutturati Le variabili usate finora avevano tutte una caratteristica in comune: ognuna di esse poteva memorizzare un singolo valore alla volta del tipo dichiarato. Le variabili con questa caratteristica sono dette scalari. Una variabile scalare non può essere ulteriormente suddivisa o separata in tipi dati validi. Vettori. Spesso però s’incontrano insiemi di variabili, tutte dello stesso tipo dati, che formano un gruppo logico. Consideriamo, ad esempio, i voti di uno studente, i codici di un colore e i prezzi dei prodotti su uno scaffale.
Un gruppo di valori singoli tutti dello stesso tipo dati scalare è detto vettore (a una dimensione), e i valori singoli sono detti le sue componenti. Così diremo che voti è un vettore di interi con 5 componenti, codici un vettore di caratteri con 4 componenti, prezzi un vettore in doppia precisione con 6 componenti. Vettori a più dimensioni. Un vettore a due dimensioni consiste in righe e colonne di elementi. Ad esempio, il vettore di numeri consiste in 3 righe e 4 colonne. In modo analogo si possono definire vettori a 3 o più dimensioni.
Concettualmente, come indica la figura, un vettore a 3 dimensioni si può considerare come un libro di tabelle di dati. Con questa analogia, il primo indice si può pensare come la localizzazione di una riga della tabella, il secondo come la localizzazione di una colonna e il terzo come il numero di pagina della tabella. Nella stessa maniera si possono dichiarare vettori di qualsiasi dimensione.
Strutture. Talvolta, tuttavia, le variabili che formano un gruppo logico non appartengono tutte allo stesso tipo dati, come avviene ad esempio per le 5 variabili che costituiscono la seguente etichetta postale: Nome_Cognome: Indirizzo: C.A.P: Città: Stato: Nella programmazione una unità d’informazione costituita da gruppi di variabili correlate appartenenti a tipi dati diversi è detta record o, in C, struttura; ciascuna variabile componente è detta campo o, in C, membro della struttura. Ciascun campo costituisce un’entità autonoma ma, presi insieme, tutti i campi formano una singola unità, che rappresenta un’organizzazione naturale dei dati di una etichetta postale. Sebbene in un elenco postale completo vi possano essere migliaia di nomi, indirizzi, C.A.P., città e Stati, la forma di ciascuna etichetta postale è identica.
Occorre distinguere tra forma e contenuto di una struttura. La forma consiste nei • tipi dati, • nomi simbolici, • disposizione dei dati individuali presenti nella struttura. Il contenuto si riferisce ai dati effettivamente memorizzati nei nomi simbolici. Ad es., un contenuto valido per la struttura precedente potrebbe essere: Francis Bronson Via Nazionale, 128 00100 Roma Italia
La differenza tra vettori e strutture risiede quindi nei tipi degli elementi che contengono: • un vettore è un tipo dati omogeneo, in quanto tutte le sue componenti sono dello stesso tipo; • una struttura è un tipo dati eterogeneo, in quanto ciascuno dei suoi campi può essere di un tipo dati differente. • Così, un vettore di strutture sarebbe un tipo dati omogeneo, i cui elementi sono dello stesso tipo eterogeneo
Liste concatenate. Un problema classico di gestione di dati è quello di compiere aggiunte o cancellazioni a record esistenti che vadano mantenuti in un ordine specifico. Ciò è illustrato considerando la parte di elenco telefonico indicata in figura. Aloisi, Sandro 0432 174973 Dolan, Edih 02 385602 Lisi, Giovanni 0556 390048 Melloni, Paolo 02 35581224 Zermann Harold 091 1275294
A partire da questo insieme iniziale di nomi e numeri di telefono, vogliamo: • inserire nuovi record alla lista nella corretta sequenza alfabetica; • cancellare i record esistenti in modo tale che lo spazio di memoria per i record cancellati sia eliminato. Sebbene l’inserimento e la cancellazione di record ordinati si possano eseguire con un vettore di strutture, esso non è una rappresentazione efficiente per aggiungere o cancellare record interni al vettore. I vettori sono fissi e di dimensione specificata in precedenza. La cancellazione di un record da un vettore crea uno spazio vuoto che richiede o una marcatura particolare o lo spostamento “in alto” di tutti gli elementi al di sotto del record cancellato per chiudere lo spazio vuoto.
Analogamente, l’aggiunta di un record al corpo di un vettore di strutture richiede che tutti gli elementi al di sotto di quello aggiunto siano spostati “in basso” per fare posto al nuovo entrato. In alternativa, si può aggiungere il nuovo elemento alla fine del vettore e riordinare quest’ultimo in modo da ripristinare l’ordine corretto dei record. Perciò, sia l’aggiunta sia la cancellazione di record a tale lista richiede in genere di ristrutturare e riscrivere la lista: operazione noiosa, lunga e inefficiente. Una lista concatenata fornisce un metodo conveniente per mantenere una lista che cambia in continuazione, senza la necessità di riordinare e ristrutturare in continuazione l’intera lista. Una lista concatenata è semplicemente un insieme di strutture ognuna delle quali contiene almeno un membro il cui valore è l’indirizzo della successiva struttura in ordine logico della lista.
Anziché richiedere che ogni record sia fisicamente memorizzato nell’ordine corretto, ogni nuovo record è fisicamente aggiunto o alla fine della lista esistente, o dovunque il computer abbia spazio libero nella sua area di memoria. I record sono concatenati insieme inserendo l’indirizzo del record successivo in quello che lo precede nell’ordine logico. Dal punto di vista del programmatore, il record corrente che viene elaborato contiene l’indirizzo del record successivo, in maniera indipendente da dove esso sia effettivamente memorizzato. Il concetto di lista concatenata è illustrato in figura.
Sebbene i dati effettivi per la struttura Lisi illustrata in figura possano essere memorizzati fisicamente in qualsiasi punto della memoria, il membro aggiuntivo inserito alla fine della struttura Dolan mantiene l’ordine alfabetico corretto. Questo membro fornisce l’indirizzo di partenza della locazione dove è memorizzato il record Lisi. Unioni. Una unione è un tipo dati che riserva la stessa area di memoria per due o più variabili, ciascuna delle quali può essere di un tipo dati diverso. Una variabile dichiarata come tipo dati unione può essere usata per contenere una variabile carattere, una intera, una in doppia precisione o qualsiasi altro tipo dati valido in C. Ognuno di essi, ma solamente uno alla volta, possono effettivamente essere assegnati alla variabile unione.
Alberi. Gli alberi sono un esempio di struttura che può essere definita in modo elegante attraverso la ricorsività, come segue: • Una struttura ad albero, con tipo base T, può essere: • la struttura vuota • un nodo di tipo T, associato a un numero finito di strutture ad albero disgiunte aventi tipo base T, denominate sottoalberi. Da questo punto di vista, la sequenza (o lista) è una struttura nella quale ogni nodo ha al più un sottoalbero, per cui viene anche chiamata albero degenere. Una struttura ad albero può essere rappresentata in diversi modi: la figura seguente ne mostra due per un tipo base T che varia nell’insieme delle lettere. Le due rappresentazioni mostrano la stessa struttura e sono perciò equivalenti.
La struttura di grafo illustra esplicitamente le relazioni di diramazione che hanno condotto alla denominazione di albero. Il nodo in cima (A) viene chiamato radice.
A A C B B C Un albero si dice ordinato se i rami di ogni nodo sono ordinati. Quindi i due alberi indicati in figura sono oggetti distinti e diversi. Un nodo y, direttamente collegato sotto il nodo x, viene chiamato un discendente (diretto) di x; se x si trova al livello i, allora si dice che y è al livello i+1. Reciprocamente, il nodo x si dice avo (diretto) di y. Per definizione, la radice di un albero si trova al livello 1. Il massimo livello degli elmenti di un albero si dice profondità o altezza dell’albero.
Se un elemento non ha discendenti, viene chiamato elemento terminale o foglia, mentre gli elementi che non sono terminali si chiamano nodi interni. Il numero di discendenti (diretti) di un nodo interno è il suo grado. Il massimo grado di tutti i nodi è il grado dell’albero. Il numero di rami, o archi, che si devono attraversare per procedere dalla radice a un nodo x si chiama lunghezza del cammino di x. La radice ha lunghezza 1, i suoi discendenti hanno lunghezza 2, ecc. In generale, un nodo al livello i ha lunghezza di cammino pari a i. La lunghezza del cammino di un albero viene definita come la somma delle lunghezze dei cammini di tutte le sue componenti, e viene anche chiamata lunghezza del cammino interno. Ad es., per l’albero mostrato nella figura iniziale la lunghezza del cammino interno è 52.
Gli alberi ordinati di grado 2 si chiamano alberi binari e hanno particolare importanza; quelli di grado maggiore di 2 si chiamano alberi generali. Definiamo un albero binario ordinato come un insieme finito di elementi (nodi) , che può essere vuoto, oppure consiste in un nodo radice con due alberi binari disgiunti, detti sottoalbero sinistro e destro della radice. • Due esempi familiari di alberi binari sono: • la storia di un torneo di calcio, dove ogni nodo, simboleggiato dal nome della squadra vincitrice, rappresenta una partita che ha come discendenti le due partite precedenti tra gli avversari; • un’espressione aritmetica con operatori diadici, nella quale ogni operatore denota un nodo interno che ha i propri operandi come sottoalberi.
La figura seguente è una rappresentazione ad albero dell’espressione (a+b/c)*(d-e*f)
File di dati. I dati per i programmi che abbiamo visto finora sono stati definiti all’interno dei programmi stessi, oppure immessi in modo interattivo durante l’esecuzione. In entrambi i casi risulta poco pratico gestire grandi quantità di dati e in particolare condividerli tra programmi. Affinché i dati prodotti in uscita da un programma possano essere immessi direttamente in un altro programma, senza dover essere ricreati o ridefiniti ogni volta, essi vanno salvati in modo indipendente e separato dal programma - ossa all’esterno di esso - di solito su dispositivi di memoria secondaria quali i dischi fissi o rimovibili, i cd-rom o i nastri magnetici. La struttura dati utilizzata in questo caso è il file (dati), che è una collezione di dati memorizzati insieme sotto un nome comune su un supporto di memorizzazione diverso dalla memoria principale di un computer.
Un file è un insieme di record correlati, quale ad es. il file degli stipendi di un’azienda, il quale contiene un record per ciascun impiegato. Per facilitare il recupero di un record specifico da un file, si sceglie almeno uno dei suoi campi come chiave del record, che lo identifica come appartenente a una particolare persona. Ad es., nel file degli stipendi si può scegliere come chiave il codice fiscale. • I record di un file sono organizzati di solito in due modi: • in un file sequenziale i record sono ordinati il base al campo chiave del record, e possono avere lunghezze differenti; • in un file ad accesso casuale i record hanno tutti la stessa lunghezza, in modo che si possa accedere a ciascuno in modo diretto, cioè senza passare attraverso gli altri record. • Vedremo più avanti le istruzioni C necessarie per • creare • scrivere o modificare • leggere • un file dati.
Tipi dati definiti dall’utente Oltre ai tipi dati predefiniti, il linguaggio C specifica alcuni metodi di definizione dei tipi dati. Ove sia necessario, è possibile costruire nuovi tipi di dati mediante tipi definiti in precedenza. I valori che appartengono a un tipo definito in questo modo sono detti, di solito, strutturati, e sono agglomerati di valori componenti, appartenenti ai tipi costituenti definiti in precedenza. Nel caso in cui ci sia un solo tipo costituente, cioè in cui tutte le componenti siano di quel tipo, esso si chiamerebbe tipo base. Il numero di valori discreti che appartengono a un tipo T viene detto cardinalità di T. La cardinalità fornisce una misura della quantià di memoria necessaria per memorizzare una variabile x di tipo T.
Poiché i tipi costituenti potrebbero essere a loro volta strutturati, si possono costruire intere gerarchie di tipi; ovviamente, però, le componenti più elementar di una struttura devono essere atomiche. Quindi è necessario disporre di una notazione per introdurre tali tipi primitivi non strutturati. Un metodo immediato è l’enumerazione dei valori che costituiscono un tipo. Per esempio, in un programma relativo alla geometria piana si potrebbe introdurre un tipo primitivo detto figura, i cui valori potrebbero essere indicati con gli identificatori rettangolo, quadrato, ellisse, circonferenza.