Download
1 / 67
670 likes | 796 Views
Promoter Prediction in E.coli using ANN. A.Krishnamachari Bioinformatics Centre, JNU chari@mail.jnu.ac.in. Definition of Bioinformatics.

E N D
Promoter Prediction in E.coli using ANN A.Krishnamachari Bioinformatics Centre, JNU chari@mail.jnu.ac.in
Definition of Bioinformatics • Systematic development and application of Computing and Computational solution techniques to biological data to investigate biological process and make novel observations
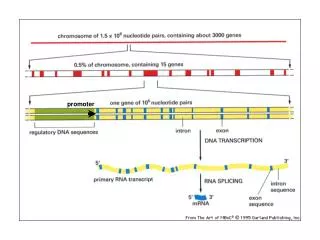
Research in Biology General approach Bioinformatics era Organism Functions Cell Chromosome DNA Sequences
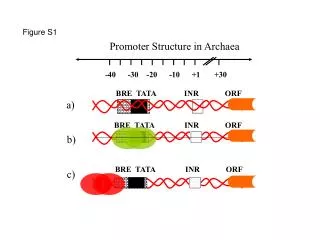
Genome Sequence intergenic TSS RBS CDS TF -10 -35 TF -> Transcription Factor Sites TSS->Transcription Start Sites RBS -> Ribosome Binding sites CDS - > Coding Sequence (or) Gene
Statement of the problem • Given a set of known sequences pertaining to a specific biological feature , develop a computational method to search for new members or sequences
Computational Methods • Pattern Recognition • Pattern classification • Optimisation Methods
Sequence Analysis AND Prediction Methods • Consensus • Position Weight Matrix (or) Profiles • Machine Learning Methods • Neural Networks • Markov Models • Support Vector Machines • Decision Tree • Optimization Methods Statistical Learning
Promoter- TATA BOX TAA T TA Consensus sequence 49%,54% and 58% 14 sites out of 291 sequences [Lisser and Margalitt] Mismatches but which one?
Describing features using frequency matrices • Goal: Describe a sequence feature (or motif) more quantitatively than possible using consensus sequences • Need to describe how often particular bases are found in particular positions in a sequence feature
Describing features using frequency matrices • Definition: For a feature of length m using an alphabet of ncharacters, a frequency matrixis an n by m matrix in which each element contains the frequency at which a given member of the alphabet is observed at a given position in an aligned set of sequences containing the feature
Frequency matrices (continued) • Three uses of frequency matrices • Describe a sequence feature • Calculate probability of occurrence of feature in a random sequence • Calculate degree of match between a new sequence and a feature
Frequency Matrices, PSSMs, and Profiles • A frequency matrix can be converted to a Position-Specific Scoring Matrix (PSSM) by converting frequencies to scores • PSSMs also called Position Weight Matrixes (PWMs) or Profiles
Methods for converting frequency matrices to PSSMs • Using log ratio of observed to expected where m(j,i) is the frequency of character j observed at position i and f(j) is the overall frequency of character j (usually in some large set of sequences) • Using amino acid substitution matrix (Dayhoff similarity matrix) [see later]
Finding occurrences of a sequence feature using a Profile • As with finding occurrences of a consensus sequence, we consider all positions in the target sequence as candidate matches • For each position, we calculate a score by “looking up” the value corresponding to the base at that position
Positions (Columns in alignment) V1 x12 + x21 + x33 + x44 + x52 TAGCT AGTGC if is above a threshold it is a site V1
Building a PSSM Set of Aligned Sequence Features PSSM builder PSSM Expected frequencies of each sequence element
Searching for sequences related to a family with a PSSM Set of Aligned Sequence Features PSSM builder Expected frequencies of each sequence element PSSM Sequences that match above threshold PSSM search Threshold Positions and scores of matches Set of Sequences to search
Consensus sequences vs. frequency matrices • consensus sequence or a frequency matrix which one to use? • If all allowed characters at a given position are equally "good", use IUB codes to create consensus sequence • Example: Restriction enzyme recognition sites • If some allowed characters are "better" than others, use frequency matrix • Example: Promoter sequences
Consensus sequences vs.frequency matrices • Advantages of consensus sequences: smaller description, quicker comparison • Disadvantage: lose quantitative information on preferences at certain locations
Linear Classification Problems Measure2 Measure1
Nonlinear Classification Problem Measure 2 Measure 1
What Is A Neural Network ? • A computational construct based on biological neuron • . A neural network can: • Learn by adapting its synaptic weights to changes in the surrounding environments; • handle imprecise, fuzzy, noisy, and probabilistic information; and • generalize from known tasks or examples to unknown ones. • Artificial neural networks (ANNs) attempt to mimic some,or all of these characteristics.
Neural Network • Characterised by: - its pattern of connections between the neurons (Network Architecture) - its method of determining the weights on the connections (training or learning algorithm)
Why Neural Network:Applications -Little or no incomplete understanding of the problem to be solved (very little theory) -Abundant data available
Neural Networks: Applications • Pattern classification • Speech synthesis and recognition • Image compression • Clustering • Medical Diagnosis • Manufacturing
Neural Network:Bioinformatics • Binding sites prediction • Protein Secondary Structure prediction • Protein folds • Micro array data clustering • Gene prediction
Neural Networks • Supervised Learning • Unsupervised Learning
Perceptron Output inputs Layer 2 (output) Layer 1 (input) 1 W1,3 3 W2,3 2 Direction of information flow
Perceptron Summation Operation xi * wij=x1*w1+x2*w2+x3w3….+xnWnj Thresholding functions Output = 0 if x*w < T Output = 1 if x*w >T 1 Output 1 Output 1 Threshold=0 0 0 T
Perceptron Output Input Logistic Transfer function 1 Output = - 1 + e Weight updates W(k+1) = w(k)+ µ[T9k) – w(k)x(k)]x(k) for 0 ≤ k≤ N-1
Learning Concepts • Generally • the target output is 1 for +ve • The target output is 0 for –ve • But practically (0.9, 0.1) combination • Stopping criterion Based on certain epochs or cycles Based on certain error estimates
Perceptron Nucleic Acid A T G C 1 2 Position In a sequence Of K nucleotides K-1 K
Bit-Coding • let the following binary values represent each base • A="0001 • C="0010 • G="0100 • T="1000 • then • G = 4 • A or C = "0011 = 3 • A,G or T = "1101 = 13 • etc.
NETWORK Nucleic Acid A T G C 1 A 0 0 0 1 Wi,j 2 G 0 1 0 0 Position In a sequence Of K nucleotides K-1 G 0 1 0 0 K T 1 0 0 0
Learning Model Test set Positive Model Negative Model P=50 N=50 TP + TN =100 Note: Training and Test sequences are fixed length
Learning Model Training Set Test Set 1 2 …………50 1 2 …………50 n=10 N=500
Learning Model TRAINING C G T A G C T A T A G T G G G T T T A A A C C C A A G A A T T A T G G A A T T T G G A A G T T T A G G A T A G C A C A G G A T A A G G C C T A G A T A T T T A T G C A T G A G A T G Prediction Method Output TEST C C T G A A C T G A G A T G A T A T A T A A G T G A A A T T C C G Input
Multilayer Perceptron Input Layer -1 Hidden layer Output Layer