Download
1 / 6
60 likes | 78 Views
Assessing the efficacy of dual-energy and tomosynthesis imaging in diagnosing lung cancer among high-risk patients. Statistical analysis suggests similar performance, with tomosynthesis not exceeding a 0.03 superiority over dual-energy. The study highlights the complexities of statistical evaluation in medical imaging diagnostics.

E N D
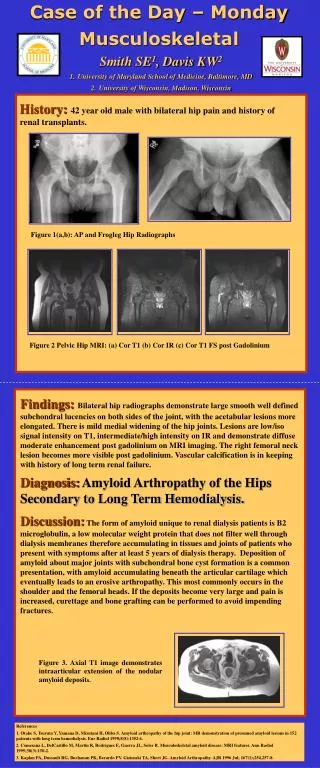
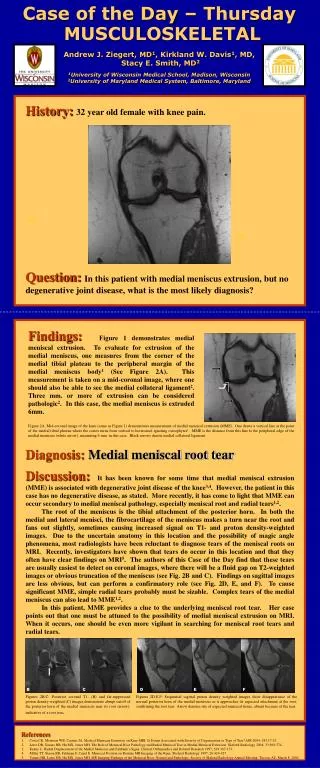
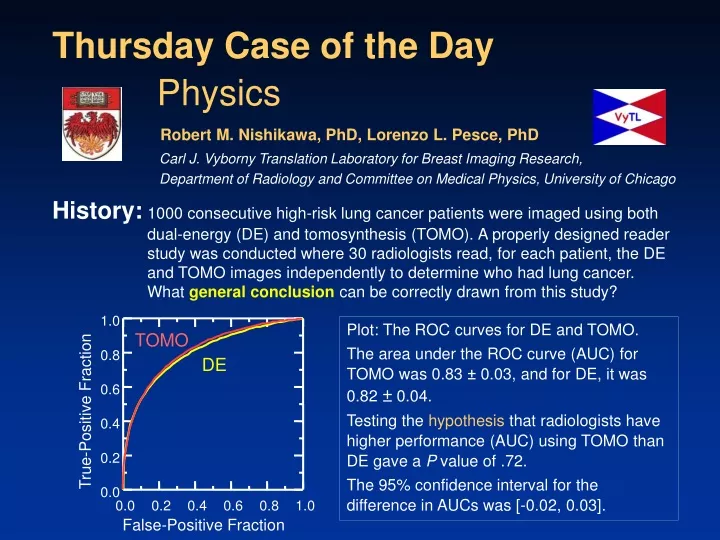
History:1000 consecutive high-risk lung cancer patients were imaged using both dual-energy (DE) and tomosynthesis (TOMO). A properly designed reader study was conducted where 30 radiologists read, for each patient, the DE and TOMO images independently to determine who had lung cancer. What general conclusion can be correctly drawn from this study? 1.0 TOMO 0.8 DE 0.6 True-Positive Fraction 0.4 0.2 0.0 0.0 0.2 0.4 0.6 0.8 1.0 False-Positive Fraction Thursday Case of the Day Physics Robert M. Nishikawa, PhD, Lorenzo L. Pesce, PhD Carl J. Vyborny Translation Laboratory for Breast Imaging Research, Department of Radiology and Committee on Medical Physics, University of Chicago Plot: The ROC curves for DE and TOMO. The area under the ROC curve (AUC) for TOMO was 0.83 ± 0.03, and for DE, it was 0.82 ± 0.04. Testing the hypothesis that radiologists have higher performance (AUC) using TOMO than DE gave a P value of .72. The 95% confidence interval for the difference in AUCs was [-0.02, 0.03].
Findings:The table below summarizes the main findings. The estimated difference in AUC between DE and TOMO was 0.01. Even though there were large numbers of cases and readers, this difference was not statistically significant (P = .72). Further, the 95% confidence interval for the difference in AUCs included 0. These data, however, do not allow one to draw the unqualified conclusion that TOMO and DE are equivalent.
Answer:The general conclusion that can be made from this study is that TOMO is not likely to be superior to DE by more than 0.03. Assuming that the trial was designed with sufficient statistical power to detect a clinically relevant difference, the likely conclusion is that TOMO, if superior at all, is not sufficiently superior to DE to recommend it against DE.
Discussion:In general, it is not possible to prove statistically that two systems are completely equivalent. Hypotheses are formed to show that: • One system is better than another (superiority). • One system is not “much” worse than another (noninferiority). • Two systems do not differ by “much” (equivalence). • The 95% CI means that if the study was repeated 20 times with a similar population of patients and a similar population of radiologists, then for about 19 out of the 20 trials, you would expect the difference in AUC to contain the true difference. This indirectly means that we are 95% confident that the difference in AUC is between -0.02 and +0.03. • Statistically speaking, a failure to show a difference never means equivalence, no matter how big the P value is. • Note, however, that if the 95% CI is sufficiently tight around zero, then the difference may be sufficiently small that we would expect both systems to perform equally well clinically. • This is why it is more important to report 95% CI than P values, especially when a statistically significant difference is not found.
Discussion:If the same hypothetical study would have been made with fewer radiologists and cases–say, 10 readers and 100 cases–and produced statistically similar AUC values for TOMO and DE, then • The P value would still probably be greater than .05 and therefore still labeled nonsignificant. • However, the 95% CI would be much bigger, probably around [-0.10 and 0.15]. • While you would still conclude that the study cannot show that TOMO is superior to DE, you would be foolhardy to assert that the two would perform equally well clinically or that either is noninferior. Based on the above data for the smaller reader study, it is possible that either system would be considerably superior in the actual clinical use (from the detection point of view, a difference of 0.1 in AUC is reasonably large).
References/Bibliography Pepe MS. The statistical evaluation of medical tests for classification and prediction. Oxford (2003). Zhou XH, Obuchowski NA, McClish DK. Statistical methods in diagnostic medicine. Wiley (2002). Broemeling LD. Bayesian biostatistics and diagnostic medicine. Chapman & Hall (2007).